A guerra de chamas desta semana na lista de desempenho do pgsql mais uma vez gira em torno do fato de que o PostgreSQL não tem a sintaxe tradicional de dicas disponível em outros bancos de dados. Há uma mistura de razões técnicas e pragmáticas por trás disso:
- A introdução de dicas é uma fonte comum de problemas posteriores, porque corrigir um local de consulta uma vez em um caso especial não é uma abordagem muito robusta. À medida que seu conjunto de dados cresce e possivelmente também altera a distribuição, a ideia que você sugeriu quando era pequena pode se tornar uma ideia cada vez mais ruim.
- Adicionar uma interface de dica útil complicaria o código do otimizador, que é bastante difícil de manter como está. Parte do motivo pelo qual o PostgreSQL funciona tão bem quanto a execução de consultas é porque o código agradável (“podemos marcar as dicas em nossa lista de recursos de comparação de fornecedores!”) que na verdade não se paga, em termos de tornar o banco de dados melhor o suficiente para justificar sua manutenção contínua, é rejeitado pela política. Se não funcionar, não será adicionado. E quando avaliadas objetivamente, as dicas são, em média, um problema e não uma solução.
- O tipo de problema que as dicas funcionam podem ser bugs do otimizador. A comunidade do PostgreSQL responde a erros reais no otimizador mais rápido do que qualquer outra pessoa no setor. Pergunte ao redor e você não precisa conhecer muitos usuários do PostgreSQL antes de encontrar um que relatou um bug e o viu ser corrigido no dia seguinte.
Agora, a principal resposta completamente válida para descobrir que as dicas estão faltando, normalmente de DBAs que estão acostumados a elas, é “bem, como eu lido com um bug do otimizador quando eu me deparo com ele?” Como todo trabalho de tecnologia hoje em dia, geralmente há uma enorme pressão para obter a solução mais rápida possível quando um problema de consulta ruim aparece.
Se o PostgreSQL não tivesse algumas maneiras de lidar com essa situação, não haveria bancos de dados PostgreSQL sérios de produção . A diferença é que as coisas que você ajusta nesse banco de dados estão mais enraizadas em influenciar as decisões que o otimizador já toma de maneira bastante sutil, em vez de apenas você dizer o que fazer. Essas são dicas no sentido literal da palavra, elas simplesmente não têm uma interface de usuário para sugerir que usuários de outros bancos de dados novos no PostgreSQL vão procurar.
Com isso em mente, vamos dar uma olhada no que você pode fazer no PostgreSQL para contornar planos de consulta ruins e bugs do otimizador, particularmente as coisas que muitas pessoas parecem pensar que só podem ser resolvidas com dicas:
- join_collapse_limit: ajusta a flexibilidade que o otimizador tem para reordenar as junções de várias tabelas. Normalmente, ele tenta todas as combinações possíveis quando as junções podem ser reorganizadas (o que é na maioria das vezes, a menos que você esteja usando uma junção externa). Reduzir join_collapse_limit, talvez até 1, remove parte ou toda essa flexibilidade. Com ele definido como 1, você obterá as junções na ordem em que as escreveu, ponto final. Planejar um grande número de junções é uma das coisas mais difíceis para o otimizador; cada junção aumenta os erros nas estimativas e aumenta o tempo de planejamento da consulta. Se a natureza subjacente de seus dados torna óbvio qual ordem de junção deve acontecer e você não espera que isso mude, depois de descobrir a ordem certa, você pode bloqueá-la usando este parâmetro.
- random_page_cost:com o padrão 4.0, este parâmetro define o custo da busca em disco para encontrar uma página aleatória no disco, em relação a um valor de referência de 1.0. Agora, na realidade, se você medir a proporção de E/S aleatória para sequencial em discos rígidos comuns, verá que esse número está mais próximo de 50. Então, por que 4,0? Primeiro, porque funcionou melhor do que valores maiores nos testes da comunidade. Em segundo lugar, em muitos casos, os dados de índice em particular serão armazenados em cache na memória, diminuindo o custo efetivo de leitura desses valores. Se, por exemplo, seu índice estiver 90% armazenado em cache na RAM, isso significa que 10% das vezes você fará a operação que é 50 vezes mais cara; isso faria com que o custo_da_página_aleatória efetivo fosse de cerca de 5. Esse tipo de situação do mundo real é o motivo pelo qual o padrão faz sentido onde está. Normalmente, vejo índices populares obterem> 95% de cache na memória. Se o seu índice é realmente muito mais provável do que isso estar na RAM, reduzir random_page_cost até um pouco acima de 1.0 pode ser uma escolha razoável, para refletir que não é mais caro do que qualquer outra leitura. Ao mesmo tempo, buscas aleatórias em sistemas muito ocupados podem ser muito mais caras do que a expectativa que você teria apenas olhando para simulações de usuário único. Eu tive que definir random_page_cost tão alto quanto 60 para fazer com que o banco de dados parasse de usar índices quando o planejador estava estimando incorretamente o quão caro eles seriam. Normalmente, essa situação vem de um erro de estimativa de sensibilidade por parte do planejador – se você estiver digitalizando mais de cerca de 20% de uma tabela, o planejador sabe que usar uma Varredura Sequencial será muito mais eficiente do que uma Varredura de Índice. A situação feia em que tive que forçar esse comportamento a acontecer muito antes disso ocorreu quando o planejador esperava que 1% das linhas fossem retornadas, mas na verdade estava mais perto de 15%.
- work_mem: ajusta a quantidade de memória disponível para consultas que fazem classificação, hash e operações semelhantes baseadas em memória. Esta é apenas uma orientação aproximada para consultas, não um limite rígido, e um único cliente pode acabar usando múltiplos de work_mem ao executar uma consulta. Assim, você precisa ter cuidado para não definir esse valor muito alto no arquivo postgresql.conf. O que você pode fazer, no entanto, é configurá-lo antes de executar uma consulta que realmente se beneficie de ter memória extra para armazenar dados de classificação ou hash. Às vezes, você pode encontrar essas consultas registrando as lentas usando log_min_duration_statement. Você também pode encontrá-los ativando log_temp_files, que serão registrados sempre que work_mem for muito pequeno e, portanto, as operações de classificação são derramadas no disco em vez de ocorrer na memória.
- OFFSET 0: PostgreSQL reorganizará as subconsultas na forma de uma junção, para que possa usar a lógica de ordem de junção normal para otimizá-la. Em alguns casos, essa decisão pode ser muito ruim, pois o tipo de coisa que as pessoas tendem a escrever como subconsultas parece um pouco mais difícil de estimar por algum motivo (eu digo isso com base no número de consultas problemáticas que vejo). Um truque sorrateiro que você pode fazer para evitar essa lógica é colocar OFFSET 0 no final da subconsulta. Isso não altera os resultados, mas inserir o tipo de nó de consulta Limit usado para executar OFFSET impedirá o rearranjo. A subconsulta sempre será executada da maneira que a maioria das pessoas espera – como seu próprio nó de consulta isolado.
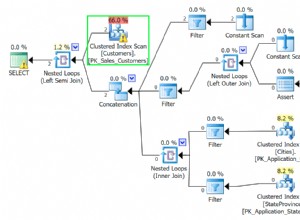
- enable_seqscan, enable_indexscan, enable_bitmapscan: Desativar um desses recursos para pesquisar linhas em uma tabela é um martelo bastante grande para recomendar evitar esse tipo de verificação (nem sempre impedindo-o, se não houver como executar seu plano, mas um seqscan, você obterá um seqscan mesmo se os parâmetros estiverem desativados). A principal coisa que eu recomendo não é corrigir consultas, é experimentar EXPLAIN e ver exatamente por que o outro tipo de verificação foi preferido.
- enable_nestloop, enable_hashjoin, enable_mergejoin: Se você suspeitar que o problema é o tipo de junção que está sendo usado e não como as tabelas estão sendo lidas, tente desativar o tipo que você está vendo em seu plano usando um desses parâmetros e execute EXPLAIN novamente. Erros nas estimativas de sensibilidade podem facilmente fazer uma junção parecer mais ou menos eficiente do que realmente é. E, novamente, ver como o plano muda com o método de junção atual desativado pode ser muito informativo sobre o motivo pelo qual ele decidiu por esse em primeiro lugar.
- enable_hashagg, enable_material: Esses recursos são relativamente novos no PostgreSQL. O uso agressivo de Hash Aggregation foi introduzido na versão 8.4 e a materialização mais agressiva na 9.0. Se você está vendo esses tipos de nós em sua saída EXPLAIN
e eles parecem estar fazendo algo errado, porque esse código é muito mais novo, é um pouco mais provável que tenha uma limitação ou bug do que alguns dos recursos mais antigos. Se você tinha um plano que funcionava bem em versões mais antigas do PostgreSQL, mas usa um desses tipos de nó e parece ter um desempenho muito pior como resultado, desabilitar esses recursos às vezes pode retornar ao comportamento anterior – além de esclarecer um pouco por que o otimizador fez a coisa errada como feedback útil. Observe que geralmente é assim que os recursos mais avançados tendem a ser introduzidos no PostgreSQL: com a opção de desativá-lo para fins de solução de problemas, se houver uma regressão do plano em relação à forma como as versões anteriores executavam as coisas. - cursor_tuple_fraction: se você não pretende ler todas as linhas de uma consulta, use um cursor para implementar isso. Nesse caso, o otimizador tenta priorizar se retorna a primeira linha rapidamente ou se prefere otimizar a consulta inteira, com base nesse parâmetro. Por padrão, o banco de dados assume que você estará lendo 10% da consulta novamente quando usar um cursor. Ajustar esse parâmetro permite que você o envie para esperar que você leia menos ou mais do que isso.
Todos esses parâmetros e ajustes de consulta devem ser considerados ajustes de triagem. Você não quer correr com eles para sempre (exceto talvez para join_collapse_limit). Você os usa para sair de um congestionamento e, em seguida, espera descobrir qual a verdadeira causa subjacente do plano ruim – estatísticas ruins, limitação/bug do otimizador ou qualquer outra coisa – e, em seguida, resolva o problema dessa direção. Quanto mais você estiver empurrando o comportamento do otimizador em uma direção, mais exposto você estará a futuras mudanças em seus dados, fazendo com que esse push não seja mais correto. Se você usá-los corretamente, como uma maneira de estudar por que você pegou o plano errado (a abordagem que usei no capítulo de otimização de consulta do PostgreSQL 9.0 High Performance), a maneira como você sugere coisas no PostgreSQL deve resultar em você deixar todas as execuções. com mau comportamento do otimizador um pouco mais experiente sobre como evitar esse tipo de problema no futuro