Armazenar ~3,5 TB de dados e inserir cerca de 1 K/s 24 horas por dia, 7 dias por semana, e também consultar a uma taxa não especificada, é possível com o SQL Server, mas há mais perguntas:
- qual é o requisito de disponibilidade que você tem para isso? 99,999% de tempo de atividade ou 95% é suficiente?
- qual requisito de confiabilidade você tem? A falta de uma inserção custa US $ 1 milhão?
- qual é o requisito de capacidade de recuperação que você tem? Se você perder um dia de dados, isso importa?
- qual requisito de consistência você tem? É necessário garantir que uma gravação seja visível na próxima leitura?
Se você precisar de todos esses requisitos que destaquei, a carga que você propõe custará milhões em hardware e licenciamento em um sistema relacional, qualquer sistema, não importa quais truques você tente (sharding, particionamento etc). Um sistema nosql, por sua própria definição, não atenderia a todos esses requisitos.
Então, obviamente, você já relaxou alguns desses requisitos. Há um bom guia visual comparando as ofertas nosql com base no paradigma 'escolha 2 de 3' no Guia Visual para Sistemas NoSQL:
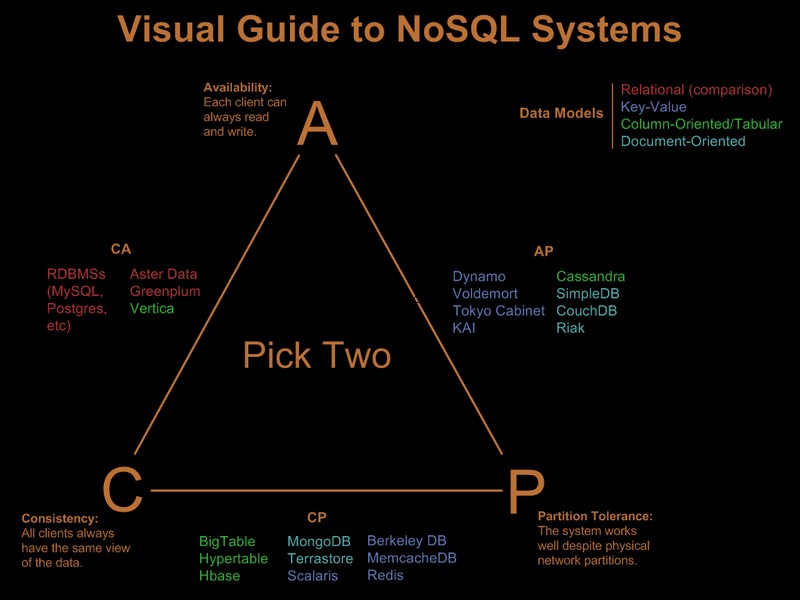
Após a atualização do comentário do OP
Com o SQL Server, isso seria uma implementação direta:
- uma única chave de tabela agrupada (GUID, hora). Sim, vai ficar fragmentado, mas a fragmentação afeta as leituras antecipadas e as leituras antecipadas são necessárias apenas para varreduras de intervalo significativas. Como você consulta apenas GUID e intervalo de datas específicos, a fragmentação não importa muito. Sim, é uma chave larga, portanto, as páginas não-folha terão uma densidade de chave ruim. Sim, isso levará a um fator de preenchimento ruim. E sim, podem ocorrer divisões de página. Apesar desses problemas, atendendo aos requisitos, ainda é a melhor escolha de chave clusterizada.
- particione a tabela por tempo para que você possa implementar a exclusão eficiente dos registros expirados, por meio de uma janela deslizante automática. Aumente isso com uma reconstrução de partição de índice online do último mês para eliminar o fator de preenchimento ruim e a fragmentação introduzidos pelo cluster de GUID.
- ative a compactação de página. Como os grupos de chaves agrupados por GUID primeiro, todos os registros de um GUID estarão próximos uns dos outros, dando à compactação de página uma boa chance de implantar a compactação de dicionário.
- você precisará de um caminho de E/S rápido para o arquivo de log. Você está interessado em alta taxa de transferência, não em baixa latência para que um log acompanhe 1.000 inserções/s, portanto, a remoção é obrigatória.
O particionamento e a compactação de página exigem um SQL Server Enterprise Edition, eles não funcionarão no Standard Edition e ambos são muito importantes para atender aos requisitos.
Como uma observação lateral, se os registros vierem de um farm de servidores Web de front-end, eu colocaria o Express em cada servidor da Web e, em vez de INSERT no back-end,
SEND as informações para o back-end, usando uma conexão/transação local no Express co-localizado com o servidor web. Isso fornece uma história de disponibilidade muito melhor para a solução. Então é assim que eu faria no SQL Server. A boa notícia é que os problemas que você enfrentará são bem compreendidos e as soluções são conhecidas. isso não significa necessariamente que isso seja melhor do que você poderia conseguir com Cassandra, BigTable ou Dynamo. Vou deixar alguém mais experiente em coisas não-sql para argumentar seu caso.
Note que eu nunca mencionei o modelo de programação, suporte .Net e tal. Sinceramente, acho que eles são irrelevantes em grandes implantações. Eles fazem uma enorme diferença no processo de desenvolvimento, mas uma vez implantados, não importa o quão rápido o desenvolvimento foi, se a sobrecarga do ORM matar o desempenho :)