Como você deve ter notado em meu blog anterior, os últimos meses foram ocupados em atualizar o Postgres-XL com a última versão 9.5 do PostgreSQL. Assim que tivemos uma versão razoavelmente estável do Postgres-XL 9.5, mudamos nossa atenção para medir o desempenho desta nova versão do Postgres-XL. Nossa escolha do benchmark é amplamente influenciada pelo trabalho em andamento no projeto AXLE, financiado pela União Europeia sob o contrato de doação 318633. Como estamos usando o TPC BENCHMARK™ H para medir o desempenho de todos os outros trabalhos realizados neste projeto, decidimos use o mesmo benchmark para avaliar o Postgres-XL. Também se adequa ao Postgres-XL porque o TPC-H tenta medir cargas de trabalho OLAP, algo que o Postgres-XL deve fazer bem.
1. Configuração do cluster Postgres-XL
Uma vez que o benchmark foi decidido, outro grande desafio foi encontrar os recursos certos para testes. Não tínhamos acesso a um grande cluster de máquinas físicas. Então fizemos o que a maioria faria. Decidimos usar o Amazon AWS para configurar o cluster Postgres-XL. A AWS oferece uma ampla variedade de instâncias, com cada tipo de instância oferecendo um poder de computação ou de E/S diferente.
Esta página na AWS mostra vários tipos de instâncias disponíveis, recursos disponíveis e seus preços para diferentes regiões. Deve-se notar que os preços e disponibilidade podem variar de região para região, por isso é importante que você verifique todas as regiões. Como o Postgres-XL requer baixa latência e alta taxa de transferência entre seus componentes, também é importante instanciar todas as instâncias na mesma região. Para nosso TPC-H de 3 TB, decidimos optar por um cluster de 16 dados de instâncias i2.xlarge da AWS. Essas instâncias têm 4 vCPU, 30 GB de RAM e 800 GB de SSD cada, armazenamento suficiente para manter todas as tabelas distribuídas, tabelas replicadas (que ocupam mais espaço com o aumento do tamanho do cluster), os índices nelas e ainda deixando espaço livre suficiente em tablespace temporário para CREATE INDEX e outras consultas.
2. Configuração de comparativo de mercado
2.1 TPC Benchmark™ H
O benchmark contém 22 consultas com o objetivo de examinar grandes volumes de dados, executar consultas com alto grau de complexidade e dar respostas a questões críticas de negócios. Gostaríamos de observar que a especificação completa do TPC Benchmark™ H lida com uma variedade de testes, como carga, potência e rendimento testes. Para nossos testes, executamos apenas consultas individuais e não o conjunto de testes completo. O TPC Benchmark™ H é composto por um conjunto de consultas de negócios projetadas para exercitar as funcionalidades do sistema de maneira representativa de aplicativos complexos de análise de negócios. Essas consultas receberam um contexto realista, retratando a atividade de um fornecedor atacadista para ajudar o leitor a se relacionar intuitivamente com os componentes do benchmark.
2.2 Entidades, relacionamentos e características do banco de dados
Os componentes do banco de dados TPC-H são definidos para consistir em oito tabelas separadas e individuais (as Tabelas Base). As relações entre as colunas dessas tabelas são ilustradas no diagrama a seguir.
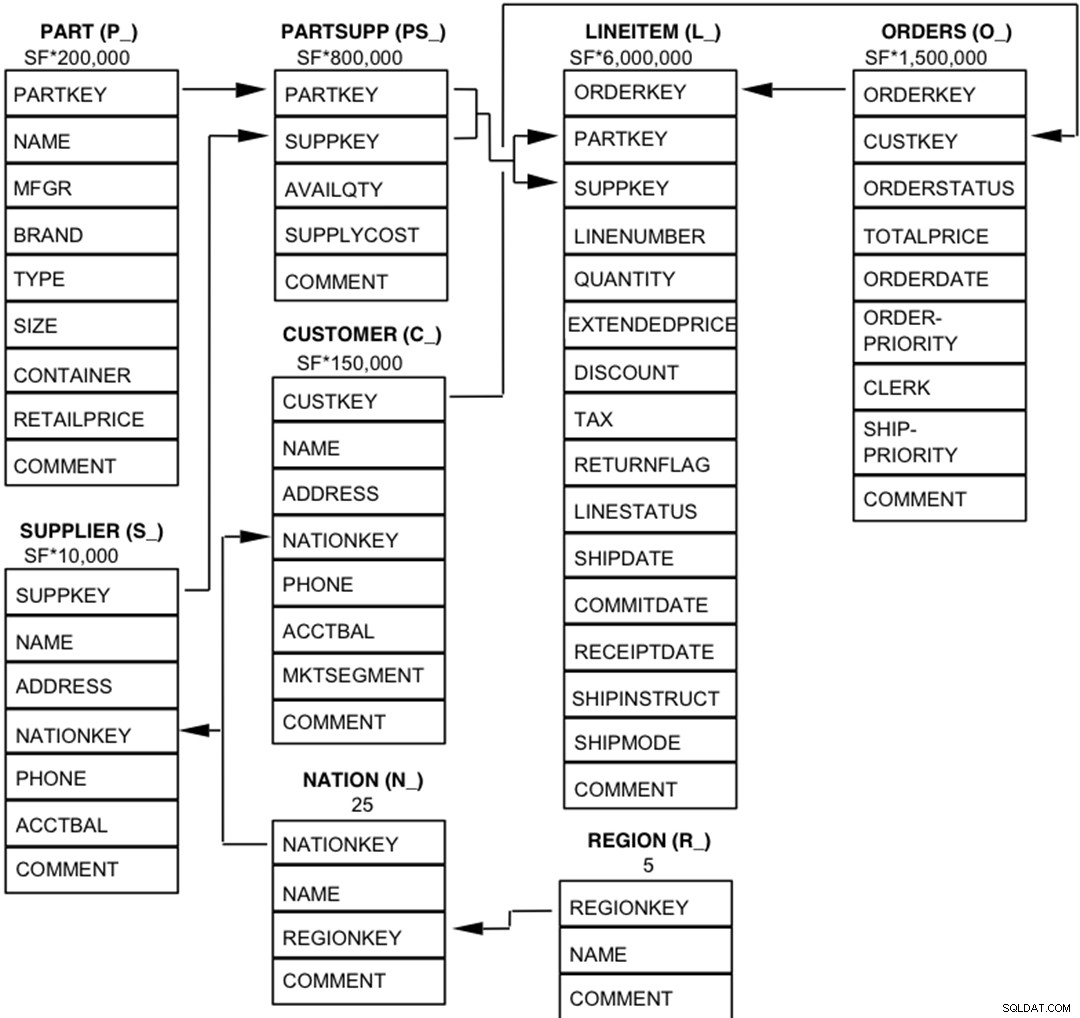 Legenda :
Legenda :- Os parênteses após cada nome de tabela contêm o prefixo dos nomes das colunas dessa tabela;
- As setas apontam na direção dos relacionamentos um para muitos entre as tabelas
- O número/fórmula abaixo de cada nome de tabela representa a cardinalidade (número de linhas) da tabela. Alguns são fatorados pelo SF, o Fator de Escala, para obter o tamanho do banco de dados escolhido. A cardinalidade da tabela LINEITEM é aproximada
2.3 Distribuição de dados para Postgres-XL
Analisamos todas as 22 consultas no benchmark e criamos a seguinte estratégia de distribuição de dados para várias tabelas no benchmark.
| Nome da tabela | Estratégia de distribuição |
| LINEITEM | HASH (l_orderkey) |
| PEDIDOS | HASH (o_orderkey) |
| PARTE | HASH (p_partkey) |
| PARTSUPP | HASH (ps_partkey) |
| CLIENTE | REPLICADO |
| FORNECEDOR | REPLICADO |
| NAÇÃO | REPLICADO |
| REGIÃO | REPLICADO |
Observe que LINEITEM e ORDERS, que são as maiores tabelas no benchmark, geralmente são unidos no ORDERKEY. Portanto, faz muito sentido colocar essas tabelas no ORDERKEY. Da mesma forma, PART e PARTSUPP são frequentemente unidos em PARTKEY e, portanto, são colocados na coluna PARTKEY. O restante das tabelas é replicado para garantir que elas possam ser unidas localmente, quando necessário.
3. Resultados do comparativo de mercado
3.1 Teste de carga
Comparamos os resultados obtidos executando um teste de carga TPC-H de 3 TB no PostgreSQL 9.6 com o cluster Postgres-XL de 16 nós. Os gráficos a seguir demonstram as características de desempenho do Postgres-XL.
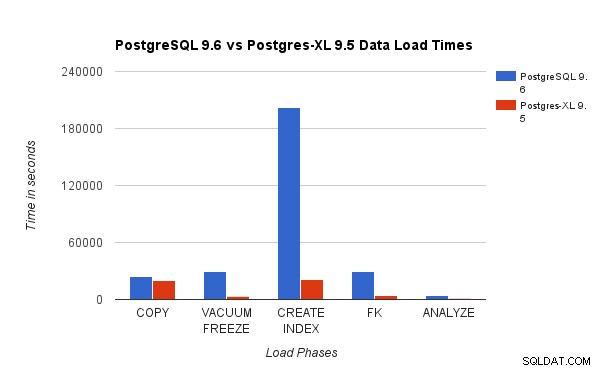 O gráfico acima mostra o tempo necessário para concluir várias fases de um teste de carga com PostgreSQL e Postgres-XL. Como visto, o Postgres-XL funciona um pouco melhor para COPY e muito melhor para todos os outros casos. Observação :Observamos que o coordenador requer muito poder computacional durante a fase COPY, especialmente quando mais de um fluxo COPY está sendo executado simultaneamente. Para resolver isso, o coordenador foi executado em uma instância da AWS otimizada para computação com 16 vCPU. Como alternativa, também poderíamos executar vários coordenadores e distribuir a carga de computação entre eles.
O gráfico acima mostra o tempo necessário para concluir várias fases de um teste de carga com PostgreSQL e Postgres-XL. Como visto, o Postgres-XL funciona um pouco melhor para COPY e muito melhor para todos os outros casos. Observação :Observamos que o coordenador requer muito poder computacional durante a fase COPY, especialmente quando mais de um fluxo COPY está sendo executado simultaneamente. Para resolver isso, o coordenador foi executado em uma instância da AWS otimizada para computação com 16 vCPU. Como alternativa, também poderíamos executar vários coordenadores e distribuir a carga de computação entre eles. 3.2 Teste de potência
Também comparamos os tempos de execução de consulta para benchmark de 3 TB no PostgreSQL 9.6 e no Postgres-XL 9.5. O gráfico a seguir mostra as características de desempenho da execução da consulta nas duas configurações.
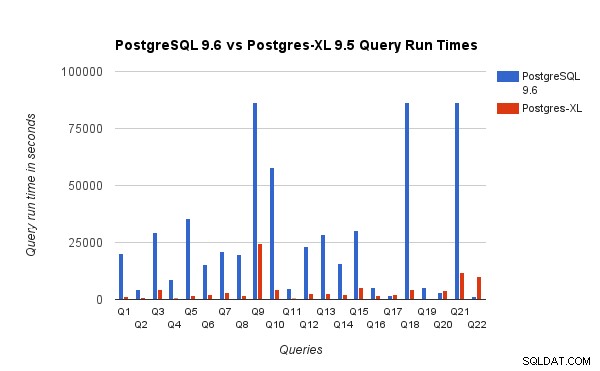 Observamos que, em média, as consultas foram executadas cerca de 6,4 vezes mais rápido no Postgres-XL e pelo menos 25% das consultas mostraram uma melhoria quase linear no desempenho, em outras palavras, eles tiveram um desempenho quase 16 vezes mais rápido neste cluster Postgres-XL de 16 nós. Além disso, pelo menos 50% das consultas mostraram uma melhoria de 10 vezes no desempenho. Analisamos ainda mais o desempenho das consultas e concluímos que as consultas bem particionadas em todos os nós de dados disponíveis, de modo que haja troca mínima de dados entre nós e sem chamadas repetidas de execução remota, escalam muito bem no Postgres-XL. Essas consultas geralmente têm um nó Remote Subquery Scan no topo e a subárvore sob o nó é executada em um ou mais nós em paralelo. Também é comum ter alguns outros nós, como um nó Limite ou um nó Agregado na parte superior do nó Varredura de Subconsulta Remota. Mesmo essas consultas funcionam muito bem no Postgres-XL. A consulta Q1 é um exemplo de consulta que deve ser dimensionada muito bem com o Postgres-XL. Por outro lado, consultas que exigem muita troca de tuplas entre datanode-datanode e/ou coordenador-datanode podem não funcionar bem no Postgres-XL. Da mesma forma, as consultas que exigem muitas conexões entre nós também podem apresentar um desempenho ruim. Por exemplo, você notará que o desempenho do Q22 é ruim em comparação com um servidor PostgreSQL de nó único. Quando analisamos o plano de consulta para Q22, observamos que existem três níveis de nós de Varredura de Subconsulta Remota aninhados no plano de consulta, onde cada nó abre um número igual de conexões com os nós de dados. Além disso, o Nest Loop Anti Join tem uma relação interna com um nó Remote Subquery Scan de nível superior e, portanto, para cada tupla da relação externa, ele deve executar uma subconsulta remota. Isso resulta em desempenho insatisfatório da execução da consulta.
Observamos que, em média, as consultas foram executadas cerca de 6,4 vezes mais rápido no Postgres-XL e pelo menos 25% das consultas mostraram uma melhoria quase linear no desempenho, em outras palavras, eles tiveram um desempenho quase 16 vezes mais rápido neste cluster Postgres-XL de 16 nós. Além disso, pelo menos 50% das consultas mostraram uma melhoria de 10 vezes no desempenho. Analisamos ainda mais o desempenho das consultas e concluímos que as consultas bem particionadas em todos os nós de dados disponíveis, de modo que haja troca mínima de dados entre nós e sem chamadas repetidas de execução remota, escalam muito bem no Postgres-XL. Essas consultas geralmente têm um nó Remote Subquery Scan no topo e a subárvore sob o nó é executada em um ou mais nós em paralelo. Também é comum ter alguns outros nós, como um nó Limite ou um nó Agregado na parte superior do nó Varredura de Subconsulta Remota. Mesmo essas consultas funcionam muito bem no Postgres-XL. A consulta Q1 é um exemplo de consulta que deve ser dimensionada muito bem com o Postgres-XL. Por outro lado, consultas que exigem muita troca de tuplas entre datanode-datanode e/ou coordenador-datanode podem não funcionar bem no Postgres-XL. Da mesma forma, as consultas que exigem muitas conexões entre nós também podem apresentar um desempenho ruim. Por exemplo, você notará que o desempenho do Q22 é ruim em comparação com um servidor PostgreSQL de nó único. Quando analisamos o plano de consulta para Q22, observamos que existem três níveis de nós de Varredura de Subconsulta Remota aninhados no plano de consulta, onde cada nó abre um número igual de conexões com os nós de dados. Além disso, o Nest Loop Anti Join tem uma relação interna com um nó Remote Subquery Scan de nível superior e, portanto, para cada tupla da relação externa, ele deve executar uma subconsulta remota. Isso resulta em desempenho insatisfatório da execução da consulta. 4. Algumas lições da AWS
Ao comparar o Postgres-XL, aprendemos algumas lições sobre como usar a AWS. Achamos que eles serão úteis para quem deseja usar/testar o Postgres-XL na AWS.
- A AWS oferece vários tipos diferentes de instâncias. Você deve avaliar cuidadosamente sua carga de trabalho e a quantidade de armazenamento necessária antes de escolher um tipo de instância específico.
- A maioria das instâncias otimizadas para armazenamento tem discos efêmeros anexados a elas. Você não precisa pagar nada adicional por esses discos, eles são anexados à instância e geralmente têm um desempenho melhor que o EBS. Mas você deve montá-los explicitamente para poder usá-los. No entanto, lembre-se de que os dados armazenados nesses discos não são permanentes e serão eliminados se a instância for interrompida. Portanto, certifique-se de estar preparado para lidar com essa situação. Como estávamos usando a AWS principalmente para benchmarking, decidimos usar esses discos efêmeros.
- Se você estiver usando o EBS, certifique-se de escolher o IOPS provisionado adequado. Um valor muito baixo causará IO muito lenta, mas um valor muito alto pode aumentar substancialmente sua fatura da AWS, especialmente ao lidar com um grande número de nós.
- Certifique-se de iniciar as instâncias na mesma zona para reduzir a latência e melhorar a taxa de transferência das conexões entre elas.
- Certifique-se de configurar as instâncias para que elas usem a rede privada para se comunicarem.
- Veja instâncias pontuais. São relativamente mais baratos. Como a AWS pode encerrar instâncias spot à vontade, por exemplo, se o preço spot for maior que o preço de lance máximo, esteja preparado para isso. O Postgres-XL pode se tornar parcial ou completamente inutilizável dependendo de quais nós são encerrados. A AWS oferece suporte a um conceito de launch_group. Se várias instâncias estiverem agrupadas no mesmo launch_group, se a AWS decidir encerrar uma instância, todas as instâncias serão encerradas.
5. Conclusão
Podemos mostrar, por meio de vários benchmarks, que o Postgres-XL pode ser dimensionado muito bem para um grande conjunto de consultas complexas do mundo real. Esses benchmarks nos ajudam a demonstrar a capacidade do Postgres-XL como uma solução eficaz para cargas de trabalho OLAP. Nossos experimentos também mostram que existem alguns problemas de desempenho com o Postgres-XL, especialmente para clusters muito grandes e quando o planejador faz uma má escolha de um plano. Também observamos que quando há um número muito grande de conexões simultâneas a um datanode, o desempenho piora. Continuaremos a trabalhar nesses problemas de desempenho. Também gostaríamos de testar a capacidade do Postgres-XL como uma solução OLTP usando cargas de trabalho apropriadas.