Em nossos blogs anteriores da Nuvem Híbrida, costumamos mencionar que uma das principais opções para aproveitar a configuração da topologia da Nuvem Híbrida é usá-la como seu destino de recuperação de desastres. É comum para uma estrutura organizacional que um Plano de Recuperação de Desastres (DRP) seja sempre abordado antes da implementação arquitetônica da configuração do banco de dados, seja na nuvem ou no local. Você pode pensar que tudo vai falhar de forma imprevisível e pode afetar seus negócios tragicamente se não for abordado e entendido corretamente. Superar esses desafios requer um DRP (Plano de Recuperação de Desastres) eficaz, para o qual seu sistema esteja bem configurado de acordo com sua aplicação, infraestrutura e requisitos de negócios. A chave para o sucesso nesses tipos de situações é a rapidez com que podemos corrigir ou recuperar o problema.
Embora o DRP trate das circunstâncias do desastre, a Continuidade de Negócios garantirá que o DRP seja testado e esteja operacional sempre que necessário. Suas opções de recuperação de desastres para seus bancos de dados devem garantir operações contínuas e limites aos limites das expectativas. Ele deve estar alinhado com o RTO e RPO desejados. É imperativo garantir que os bancos de dados de produção estejam disponíveis para os aplicativos mesmo durante desastres; caso contrário, pode acabar sendo um negócio caro. Os DBAs, os Arquitetos, precisam garantir que os ambientes de banco de dados possam suportar desastres e estejam em conformidade com o SLA de recuperação de desastres. As implantações de banco de dados devem ser configuradas corretamente para garantir que os desastres não afetem a disponibilidade do banco de dados e a continuidade dos negócios.
Opções de recuperação de desastres
Seu cluster PostgreSQL deve ser configurado com uma abordagem sistemática que se comprometa com as melhores práticas e seja aceitável para os padrões do setor. Junto com as abordagens sistemáticas, os seguintes processos ou mecanismos ajudam a garantir que seu PostgreSQL implantado em uma nuvem híbrida tenha essas presenças:
-
Failover/Switchover
-
Backup automatizado
-
Altamente disponível
-
Balanceamento de carga
-
Ambiente altamente distribuído
Failover/Switchover
Failover é um processo automatizado caso seu mestre falhe; o servidor em espera ativa ou em espera ativa é promovido à função de principal/mestre. É uma prática recomendada que oferece um ambiente de alta disponibilidade ter pelo menos um nó secundário para atuar como candidato a um nó de failover. Quando o servidor primário falhar, o servidor em espera deve iniciar os procedimentos de failover e, em seguida, o servidor secundário ou em espera deve assumir a função de mestre. Um sistema de failover utiliza um mínimo de dois servidores na prática comum, que servem como primário e reserva. Sua verificação de conectividade é auxiliada por um mecanismo de pulsação que faz verificações ininterruptas e verifica se ambos estão em bom estado e a comunicação está ativa. No entanto, em alguns casos, a conectividade pode dar um alarme falso. Portanto, em algumas configurações e ambientes, a presença de um terceiro sistema, como um nó de monitoramento, está em uma rede ou datacenter separado. Esta é uma opção infalível para evitar failover inadequado ou indesejado. Um nó de verificação infalível pode possuir recursos e verificações extras, o que adiciona complexidade. Essa configuração requer testes completos e rigorosos para garantir que o failover seja feito corretamente quando houver uma alteração na implementação. Além disso, isso é importante para evitar qualquer deterioração do seu PostgreSQL
Digamos que você tenha seu cluster secundário ou em espera em um datacenter diferente com uma configuração de hardware diferente; talvez você não queira fazer o failover abruptamente, especialmente se não for um caso ideal devido apenas a um falso positivo. No entanto, neste cenário, seu nó ou cluster de destino de recuperação de dados deve ter os mesmos recursos e especificações que seu nó ou cluster primário. Se o seu destino de recuperação de dados estiver em uma nuvem pública e o primário estiver no local, certifique-se de que ele já tenha sido coberto em seu planejamento de capacidade e que os recursos tenham quase as mesmas especificações para evitar resultados indesejados.
Ao utilizar e preparar seu mecanismo de failover em seu cluster PostgreSQL dentro de uma nuvem híbrida, você deve certificar-se de que sua ferramenta é perfeita para realizar o trabalho que deve ser realizado. Existem ferramentas de terceiros que não são empacotadas no PostgreSQL com relação ao failover avançado. Por exemplo, há ClusterControl, pg_auto_failover da CitusData (c/o Microsoft), Pgpool-II, Bucardo e outros. Essas ferramentas de utilitário avançadas fornecem cerca de nó ou conhecida como STONITH (atirar o outro nó na cabeça). Isso garante que seu nó primário ou mestre com falha evite aceitar gravações ou voltar a ficar online como seu estado anterior para atender a transações normais. Esse problema é comumente conhecido como cenário de cérebro dividido. Ele perde a sincronização de dados devido a uma falha (nível de hardware ou recurso), mas ainda assim seus servidores primários, que supostamente são apenas um servidor primário, agem como se estivessem fazendo os destinatários normais de solicitações de gravação de dados, causando corrupção de dados em todo o cluster.
Backup automatizado
Os backups sempre oferecem alta garantia e proteção contra perda de dados. O backup maximiza seu RPO, pois ajuda a minimizar a perda de dados quando ocorre um desastre. O que você deve considerar e preparar para seu backup automatizado abrange seu dispositivo/hardware de backup, redundância de dados de backup, segurança, desempenho, velocidade e armazenamento de dados.
Aparelho de backup
Você deve ter a melhor escolha para seu dispositivo de backup aqui. Velocidade, volume de armazenamento significativo e alta disponibilidade podem ser a escolha desejada. Alguns contam com armazenamento SAN ou NAS ou distribuem seus dados para outros provedores de armazenamento de backup de terceiros. É essencial que seu dispositivo de backup ofereça velocidade para gravação e leitura de dados, especialmente se você aplicar compactação e criptografia para seus dados em repouso. A descompactação e a descriptografia exigem recursos, portanto, você deve considerar quando usar a recuperação de dados. Durante esse estado, você deve determinar que precisa atingir seu RPO máximo e comprometer o SLA alcançável (Acordo de nível de serviço) para seus clientes. Também é ideal que você precise isolar seu backup de sua rede local ou armazená-lo em um local remoto. Uma abordagem alternativa é se envolver com fornecedores terceirizados. Por exemplo, armazenar seu backup na nuvem pode ser uma opção, e sua instalação é altamente sofisticada e atende às suas necessidades.
Redundância de dados de backup
Distribuir seus dados em vários locais é a solução ideal. Isso fortalece suas chances de recuperação de dados, por exemplo, um erro humano ou um erro de lógica de software fazendo com que você exclua cópias antigas de backup, mas exclua erroneamente todas as cópias de backup cruciais. Em alguns ambientes sofisticados, como o armazenamento em um ambiente de nuvem como Amazon S3, Cloud Storage by Google ou Azure Blob Storage oferece replicação de seu arquivo armazenado. Isso fornece mais redundância e pode ser configurado de maneira flexível que atenda às suas necessidades.
Altamente disponível
Um cluster PostgreSQL altamente disponível em uma nuvem híbrida sempre garante que a comunicação do banco de dados garanta o tempo de atividade. O caso ideal de alta disponibilidade depende da medição de sua disponibilidade. Nesse caso, uma configuração comum para um PostgreSQL implantado em uma nuvem híbrida pode ser seu banco de dados hospedado em uma nuvem pública ou seu cluster secundário atuando como seu cluster de recuperação de dados caso o cluster primário falhe ou sofra um desastre de rede e possa levar muito tempo de inatividade. Em algumas configurações, é possível que o cluster secundário localizado na nuvem pública não seja exatamente tão sofisticado quanto o primário, digamos que esta seja sua nuvem local ou privada. Seu aplicativo pode brincar para limitar os visitantes ou o tráfego que pode se conectar ao seu banco de dados. Esse tipo de cenário pode diminuir seu custo de configuração, mas é claro que isso depende apenas de seus requisitos. Se o seu tipo de aplicativo for massivo e precisar receber continuamente situações de tráfego normal a ocupado, certifique-se de que seus recursos de cluster secundários sejam tão poderosos quanto os primários para garantir alta disponibilidade, ou seja, 99,9999999%.
Para obter um cluster PostgreSQL altamente disponível em um ambiente de nuvem híbrida, você precisa ter um mecanismo de failover. No caso de uma falha e um cluster primário ou servidor primário ficar inativo, um servidor secundário ou em espera pode assumir a função de um mestre, qualquer que seja sua localização. O mais importante é a funcionalidade, e o desempenho, especialmente do ponto de vista do aplicativo ou do cliente, não é afetado ou pelo menos é mínimo.
Balanceamento de carga
O mecanismo de balanceamento de carga para seu cluster PostgreSQL auxilia na configuração da nuvem híbrida, que é mais gerenciável e menos arriscada, especialmente quando ocorre uma carga de tráfego intenso. Em muitas situações, um servidor está recebendo uma carga muito alta, fazendo com que o servidor entre em pânico. Isso leva a um estado inutilizável do servidor devido a recursos ocupados consumidos por muitos threads em execução em segundo plano. Essa situação pode ser melhorada corrigindo consultas incorretas e a arquitetura de design do seu banco de dados. Isso deve incluir como você distribui a leitura em relação à carga de gravação e uma compreensão profunda dos requisitos do aplicativo, como configuração mestre-mestre ou apenas um mestre, mas dimensionando-o verticalmente para fornecer recursos de computação e memória mais altos. Há também uma grande seleção de ferramentas de terceiros, como pgbouncer e Pgpool II, para auxiliar na implantação do PostgreSQL em um ambiente de nuvem híbrida.
Ambiente altamente distribuído
Em termos de escalabilidade, ser altamente distribuído em vários locais ou diferentes provedores de nuvem (no local ou nuvem privada e pública) oferece mais flexibilidade e tolerabilidade em um ambiente de nuvem híbrida e isso é ótimo para recuperação de desastres. Ele é flexível quando precisa fazer failover em um local de nuvem específico favorável a desastres naturais ou catástrofes, especialmente se a região designada onde seu cluster principal reside estiver devastada ou afetada por uma causa natural. Esta é uma causa inevitável que você tem que entender e ser confiável da situação atual. Seu aplicativo e clientes precisam ser atendidos continuamente sem parar. Isso serve ao propósito de estar disponível publicamente na nuvem, além de servir em um ambiente privado ou local. Essa configuração adiciona mais alta complexidade e requer conhecimento avançado no lado do banco de dados e segurança e rede. A otimização e o ajuste são cruciais para o sucesso aqui, pois é muito importante que, ao servir uma segurança reforçada para encapsular seus dados enquanto viaja na Internet, o desempenho tenha que se estabilizar e não seja afetado pela configuração implementada.
Devido à complexidade de configuração, ter uma ferramenta é ideal para gerenciar a implantação e facilitar o status geral de seus bancos de dados, supervisionando um aspecto de seu cluster, mas em todo o nível, desde nuvem privada local, e no aspecto de nuvem pública. Todas as configurações devem ser mantidas em um nível gerenciável e direto para que, em caso de alarmes e alertas, seja fácil corrigir e resolver o problema de maneira adequada e oportuna.
ClusterControl para recuperação de desastres em um ambiente de nuvem híbrida
ClusterControl permite que a organização ou empresas gerenciem o banco de dados com flexibilidade e reduzam a complexidade geral da configuração. O ClusterControl oferece failover, backup automatizado, oferece uma configuração altamente disponível, balanceamento de carga e oferece suporte a uma implantação de ambiente distribuído, facilitando a adição de nós em uma nuvem pública ou privada ou local.
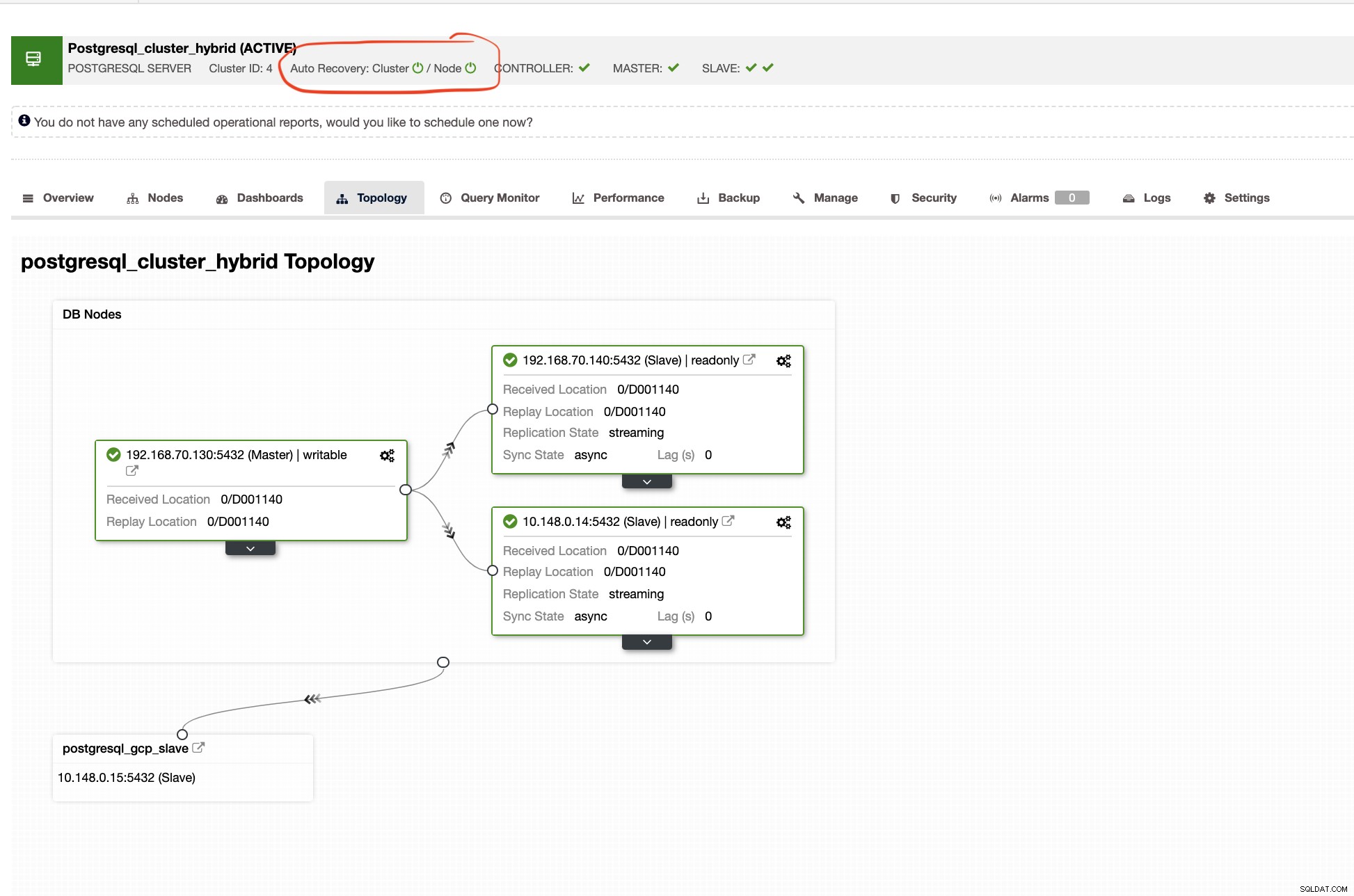
Recuperação automática de controle de cluster
A Recuperação Automática do ClusterControl representa vários mecanismos de failover e características de recuperação, especialmente quando um nó fica inativo ou um cluster entra em um estado degradado. Isso pode ser feito facilmente, conforme mostrado na captura de tela abaixo:
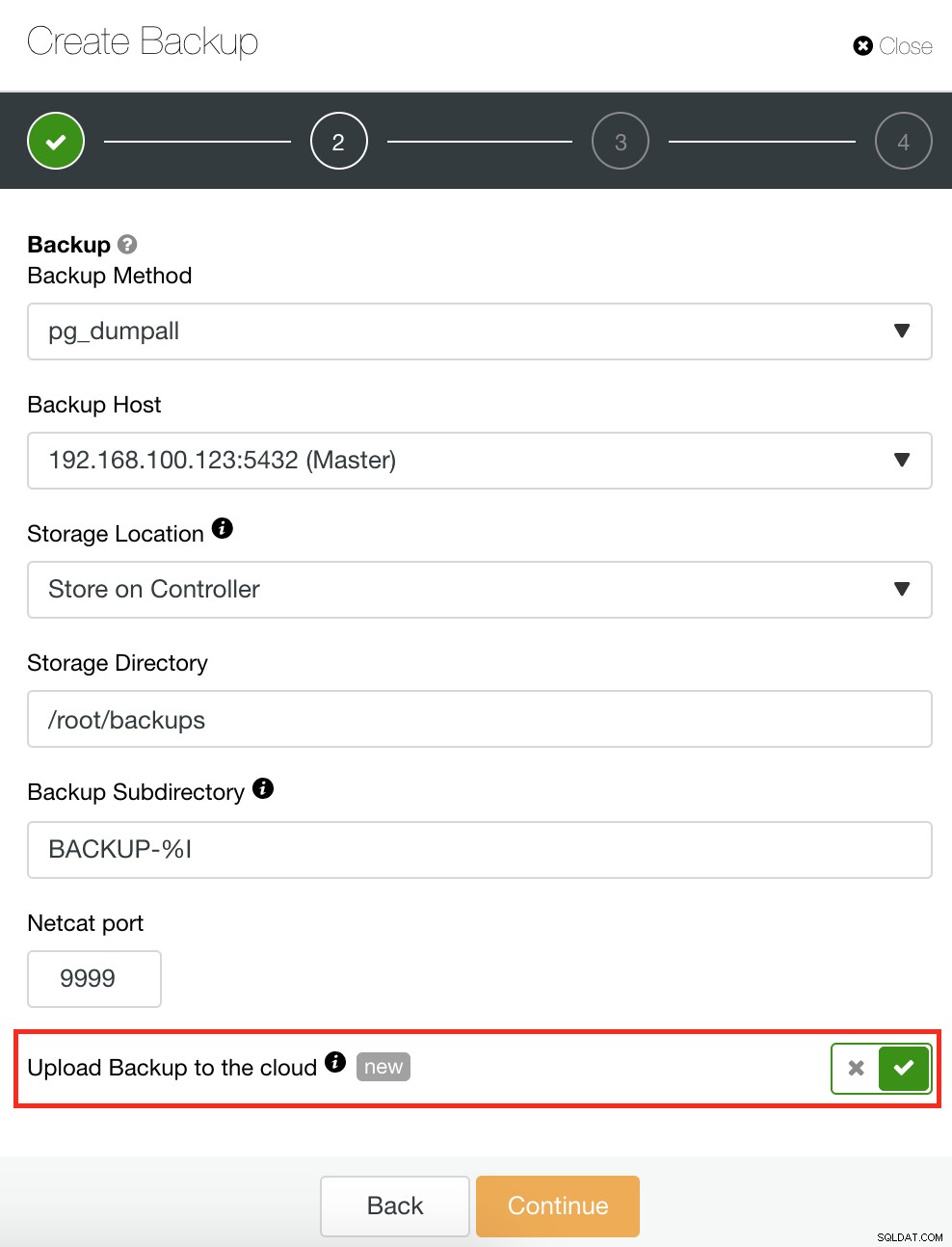
Backup e restauração
O ClusterControl também tem um recurso Backup e restauração que permite gerenciar seu backup, criar um backup, agendar um backup e restaurar um backup. Gerenciar seu backup é muito simples e criar ou agendar um backup é simples, mas também oferece opções avançadas. Ele também oferece opções de backup em nuvem que permitem que você tenha redundância de dados de backup, fortalecendo suas opções de recuperação de desastres. Ver abaixo:
Conforme mostrado abaixo, o gerenciamento de seu backup fornece uma interface de usuário simples para você selecionar qual backup deseja restaurar ou pode ser necessário descartar. O backup do ClusterControl permite que você escolha um período de retenção, portanto, caso você tenha uma lista longa, alguns deles podem ser excluídos quando atingir seu período de retenção. 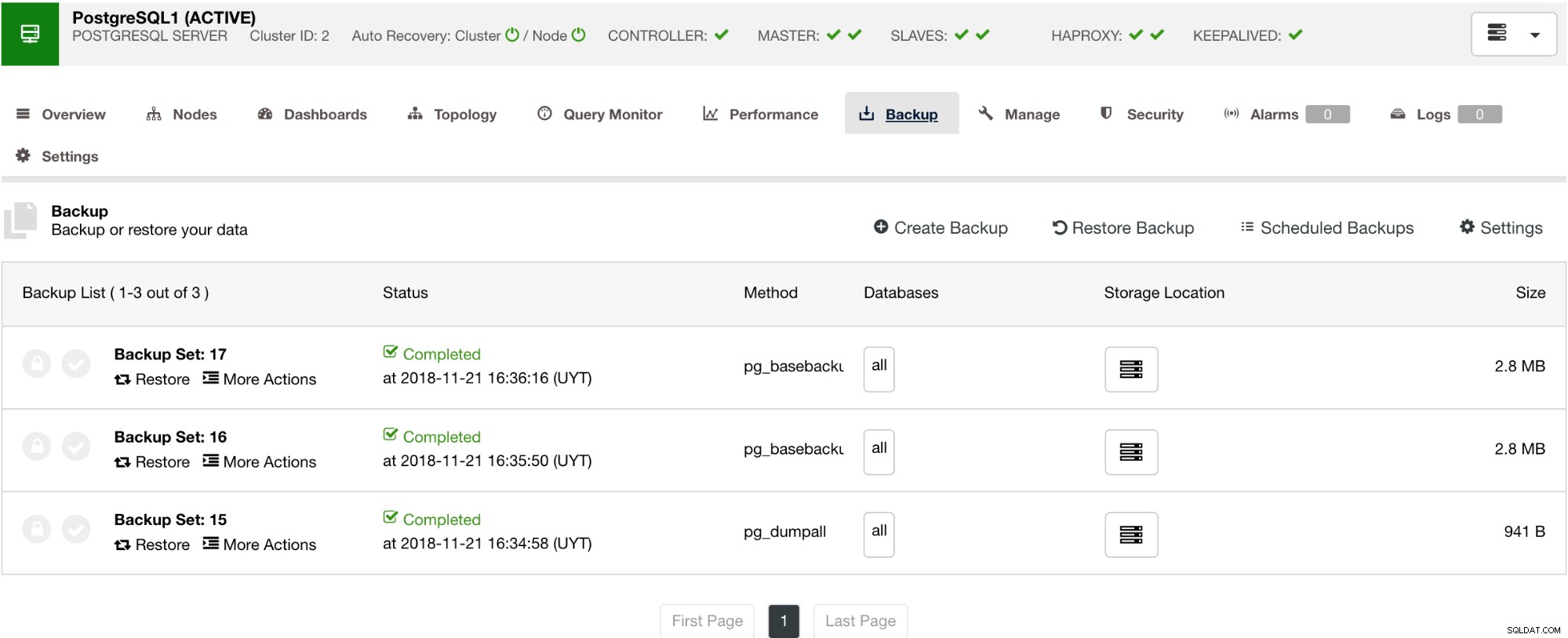
Suporta mecanismos de alta disponibilidade (HA) e balanceamento de carga (LB)
Você não precisa configurar manualmente ou mesmo pesquisar algumas maneiras de adicionar alta disponibilidade em seu cluster PostgreSQL. Existe uma maneira fácil e conveniente de fazer o trabalho com o ClusterControl. Se você puder ver a captura de tela de exemplo, ela tem uma configuração HAProxy e Keepalived. Veja a captura de tela abaixo:
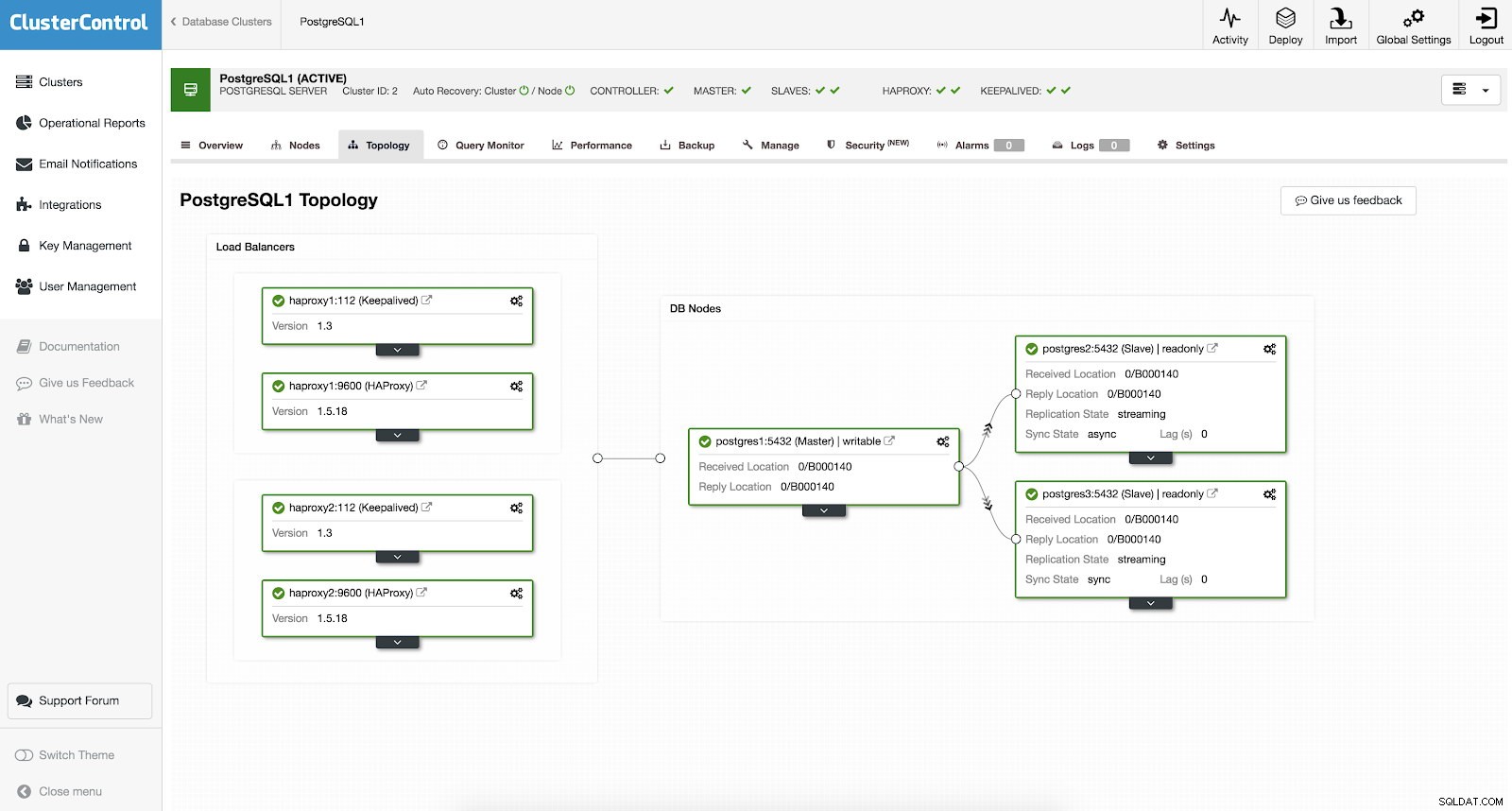
Configurar uma alta disponibilidade com ClusterControl pode ser feito acessando