Assim que vi o recurso SQL 2016 AT TIME ZONE, sobre o qual escrevi aqui em sqlperformance.com a alguns meses atrás, lembrei-me de um relatório que precisava desse recurso. Este post forma um estudo de caso sobre como eu vi isso funcionar, que se encaixa no T-SQL terça-feira deste mês hospedado por Matt Gordon (@sqlatspeed). (É a 87ª terça-feira do T-SQL, e eu realmente preciso escrever mais postagens no blog, principalmente sobre coisas que não são solicitadas pelas terças-feiras do T-SQL.)
Assim que vi o recurso SQL 2016 AT TIME ZONE, sobre o qual escrevi aqui em sqlperformance.com a alguns meses atrás, lembrei-me de um relatório que precisava desse recurso. Este post forma um estudo de caso sobre como eu vi isso funcionar, que se encaixa no T-SQL terça-feira deste mês hospedado por Matt Gordon (@sqlatspeed). (É a 87ª terça-feira do T-SQL, e eu realmente preciso escrever mais postagens no blog, principalmente sobre coisas que não são solicitadas pelas terças-feiras do T-SQL.) A situação era essa, e isso pode soar familiar se você ler esse meu post anterior.
Muito antes de existirem as soluções LobsterPot, eu precisava produzir um relatório sobre os incidentes ocorridos e, em particular, mostrar o número de vezes que as respostas foram feitas dentro do SLA e o número de vezes que o SLA foi perdido. Por exemplo, um incidente Sev2 que ocorreu às 16h30 em um dia da semana precisaria ter uma resposta em 1 hora, enquanto um incidente Sev2 que ocorreu às 17h30 em um dia da semana precisaria ter uma resposta em 3 horas. Ou algo assim – esqueço os números envolvidos, mas lembro que os funcionários do helpdesk davam um suspiro de alívio quando chegavam as 17h, porque não precisariam responder às coisas tão rapidamente. Os alertas Sev1 de 15 minutos subitamente se estendiam para uma hora, e a urgência desaparecia.
Mas um problema viria sempre que o horário de verão começasse ou terminasse.
Tenho certeza que se você já lidou com bancos de dados, você saberá a dor que é o horário de verão. Supostamente, Ben Franklin teve a ideia – e para isso ele deveria ser atingido por um raio ou algo assim. A Austrália Ocidental tentou por alguns anos recentemente, e sensatamente o abandonou. E o consenso geral é armazenar dados de data/hora em UTC.
Se você não armazenar dados em UTC, corre o risco de um evento começar às 2h45 e terminar às 2h15 depois que os relógios voltarem. Ou ter um incidente de SLA que começa às 1h59, pouco antes de os relógios avançarem. Agora, esses horários são bons se você armazenar o fuso horário em que estão, mas no horário UTC funciona conforme o esperado.
…exceto para relatórios.
Porque como vou saber se uma determinada data foi antes do início do horário de verão ou depois? Eu posso saber que um incidente ocorreu às 6h30 em UTC, mas são 16h30 em Melbourne ou 17h30? Obviamente, posso considerar em qual mês está, porque sei que Melbourne observa o horário de verão do primeiro domingo de outubro ao primeiro domingo de abril, mas se houver clientes em Brisbane, Auckland, Los Angeles e Phoenix, e vários lugares dentro de Indiana, as coisas ficam muito mais complicadas.
Para contornar isso, havia muito poucos fusos horários nos quais os SLAs poderiam ser definidos para essa empresa. Foi considerado muito difícil atender a mais do que isso. Um relatório poderia então ser personalizado para dizer “Considere que em uma determinada data o fuso horário mudou de X para Y”. Parecia confuso, mas funcionou. Não havia necessidade de nada para procurar o registro do Windows, e basicamente funcionou.
Mas hoje em dia, eu teria feito diferente.
Agora, eu teria usado AT TIME ZONE.
Veja bem, agora eu poderia armazenar as informações de fuso horário do cliente como uma propriedade do cliente. Eu poderia então armazenar cada horário de incidente em UTC, permitindo que eu fizesse os cálculos necessários em torno do número de minutos para responder, resolver e assim por diante, enquanto podia relatar usando o horário local do cliente. Supondo que meu IncidentTime realmente tenha sido armazenado usando datetime, em vez de datetimeoffset, seria simplesmente uma questão de usar um código como:
i.IncidentTime AT TIME ZONE 'UTC' AT TIME ZONE c.tz
…que primeiro coloca o i.IncidentTime sem fuso horário em UTC, antes de convertê-lo no fuso horário do cliente. E este fuso horário pode ser 'Horário Padrão do Leste da AUS', ou 'Horário Padrão das Maurícias', ou qualquer outra coisa. E o SQL Engine é deixado para descobrir qual deslocamento usar para isso.
Nesse ponto, posso facilmente criar um relatório que liste cada incidente em um período de tempo e mostrá-lo no fuso horário local do cliente. Posso converter o valor para o tipo de dados de tempo e, em seguida, relatar quantos incidentes ocorreram dentro do horário comercial ou não.
E tudo isso é muito útil, mas e a indexação para lidar bem com isso? Afinal, AT TIME ZONE é uma função. Mas mudar o fuso horário não muda a ordem em que os incidentes realmente ocorreram, então deve ficar tudo bem.
Para testar isso, criei uma tabela chamada dbo.Incidents e indexei a coluna IncidentTime. Em seguida, executei essa consulta e confirmei que uma busca de índice foi usada.
select i.IncidentTime, itz.LocalTime from dbo.Incidents i cross apply (select i.IncidentTime AT TIME ZONE 'UTC' AT TIME ZONE 'Cen. Australia Standard Time') itz (LocalTime) where i.IncidentTime >= '20170201' and i.IncidentTime < '20170301';
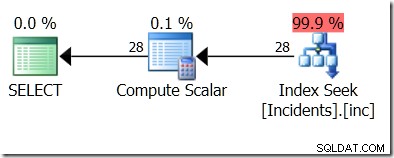
Mas eu quero filtrar em itz.LocalTime…
select i.IncidentTime, itz.LocalTime from dbo.Incidents i cross apply (select i.IncidentTime AT TIME ZONE 'UTC' AT TIME ZONE 'Cen. Australia Standard Time') itz (LocalTime) where itz.LocalTime >= '20170201' and itz.LocalTime < '20170301';
Sem sorte. Não gostou do índice.
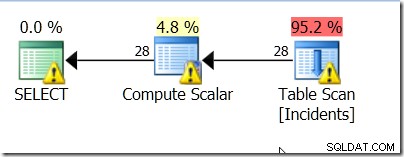
Os avisos são porque ele precisa analisar muito mais do que os dados nos quais estou interessado.
Eu até tentei usar uma tabela com um campo datetimeoffset. Afinal, AT TIME ZONE pode alterar a ordem ao passar de datetime para datetimeoffset, mesmo que a ordem não seja alterada ao passar de datetimeoffset para outro datetimeoffset. Eu até tentei ter certeza de que a coisa que eu estava comparando estava no fuso horário.
select i.IncidentTime, itz.LocalTime
from dbo.IncidentsOffset i
cross apply (select i.IncidentTime AT TIME ZONE 'Cen. Australia Standard Time') itz (LocalTime)
where itz.LocalTime >= cast('20170201' as datetimeoffset)
AT TIME ZONE 'Cen. Australia Standard Time'
and itz.LocalTime < cast('20170301' as datetimeoffset)
AT TIME ZONE 'Cen. Australia Standard Time'; 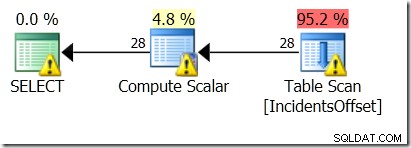
Ainda sem sorte!
Então agora eu tinha duas opções. Uma era armazenar a versão convertida junto com a versão UTC e indexá-la. Eu acho que isso é uma dor. Certamente é muito mais uma mudança de banco de dados do que eu gostaria.
A outra opção era usar o que chamo de predicados auxiliares. Esse é o tipo de coisa que você vê quando usa LIKE. São predicados que podem ser usados como predicados de busca, mas não exatamente o que você está pedindo.
Imagino que não importa em qual fuso horário estou interessado, os IncidentTimes com os quais me importo estão dentro de um intervalo muito específico. Esse intervalo não é mais do que um dia maior do que o meu intervalo preferido, em ambos os lados.
Então, vou incluir dois predicados extras.
select i.IncidentTime, itz.LocalTime
from dbo.IncidentsOffset i
cross apply (select i.IncidentTime
AT TIME ZONE 'Cen. Australia Standard Time') itz (LocalTime)
where itz.LocalTime >= cast('20170201' as datetimeoffset)
AT TIME ZONE 'Cen. Australia Standard Time'
and itz.LocalTime < cast('20170301' as datetimeoffset)
AT TIME ZONE 'Cen. Australia Standard Time
and i.IncidentTime >= dateadd(day,-1,'20170201')
and i.IncidentTime < dateadd(day, 1,'20170301'); 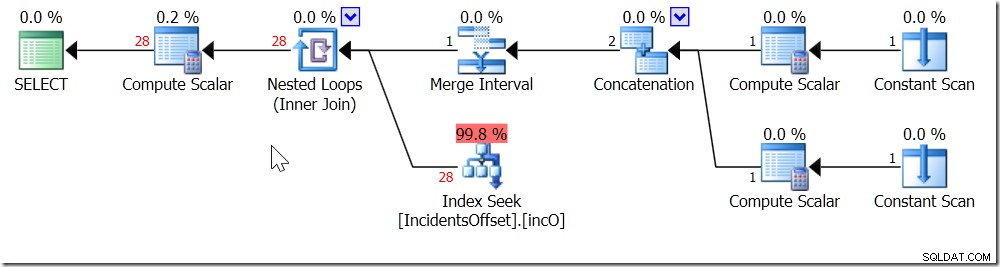
Agora, meu índice pode ser usado. É ter que examinar 30 linhas antes de filtrá-las para as 28 com as quais se importa – mas isso é muito melhor do que digitalizar a coisa toda.
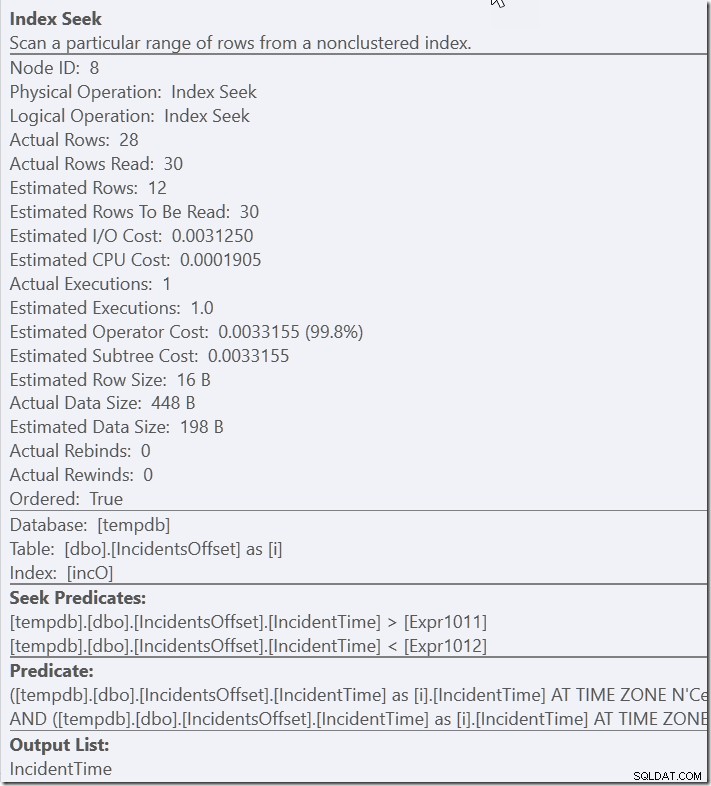
E você sabe – esse é o tipo de comportamento que vejo o tempo todo em consultas regulares, como quando faço CAST(myDateTimeColumns AS DATE) =@SomeDate ou uso LIKE.
Eu estou bem com isso. AT TIME ZONE é ótimo para me permitir lidar com minhas conversões de fuso horário e, considerando o que está acontecendo com minhas consultas, também não preciso sacrificar o desempenho.
@rob_farley