Como anunciamos recentemente, o ClusterControl 1.7.4 tem um novo recurso chamado Replicação de cluster para cluster. Ele permite que você tenha uma replicação em execução entre dois clusters autônomos. Para informações mais detalhadas, consulte o anúncio acima mencionado.
Vamos dar uma olhada em como usar esse novo recurso para um cluster PostgreSQL existente. Para esta tarefa, vamos supor que você tenha o ClusterControl instalado e o Cluster Mestre foi implantado usando-o.
Requisitos para o cluster mestre
Existem alguns requisitos para que o cluster mestre funcione:
- PostgreSQL 9.6 ou posterior.
- Deve haver um servidor PostgreSQL com a função ClusterControl 'Master'.
- Ao configurar o cluster escravo, as credenciais de administrador devem ser idênticas às do cluster mestre.
Preparando o cluster mestre
O cluster mestre precisa atender aos requisitos mencionados acima.
Sobre o primeiro requisito, certifique-se de estar usando a versão correta do PostgreSQL no cluster mestre e escolha a mesma para o cluster escravo.
$ psql
postgres=# select version();
PostgreSQL 11.5 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 4.8.5 20150623 (Red Hat 4.8.5-36), 64-bitSe você precisar atribuir a função de mestre a um nó específico, poderá fazê-lo na interface do usuário do ClusterControl. Vá para ClusterControl -> Select Master Cluster -> Nodes -> Select the Node -> Node Actions -> Promote Slave.
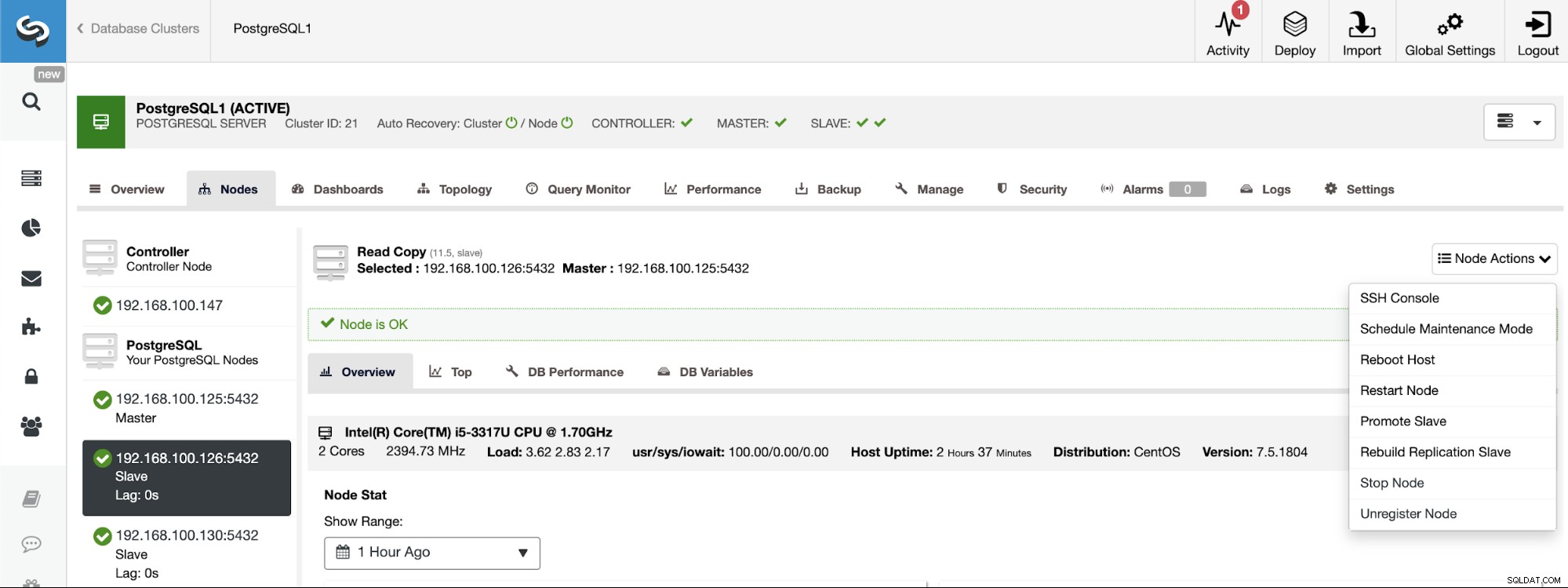
E finalmente, durante a criação do Slave Cluster, você deve usar o mesmo admin credenciais que você está usando atualmente no cluster mestre. Você verá onde adicioná-lo na seção a seguir.
Criando o cluster escravo a partir da interface do usuário do ClusterControl
Para criar um novo Cluster Slave, vá para ClusterControl -> Select Cluster -> Cluster Actions -> Create Slave Cluster.
O cluster escravo será criado por streaming de dados do cluster mestre atual.
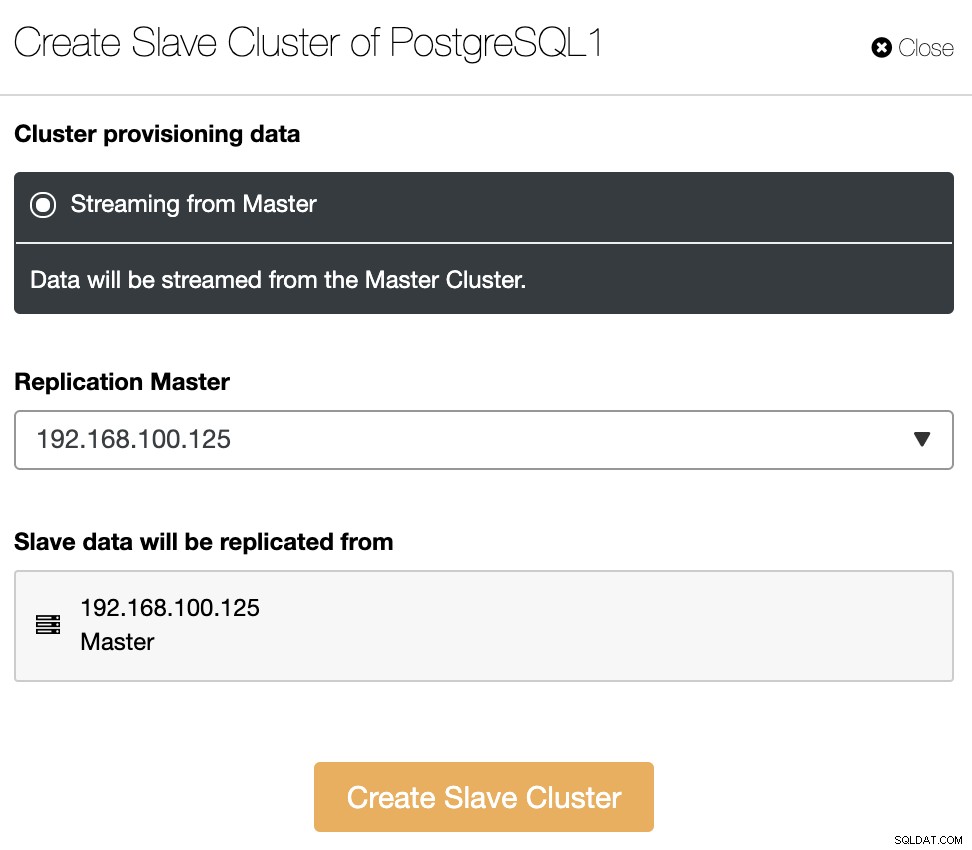
Nesta seção, você também deve escolher o nó mestre do cluster atual a partir do qual os dados serão replicados.
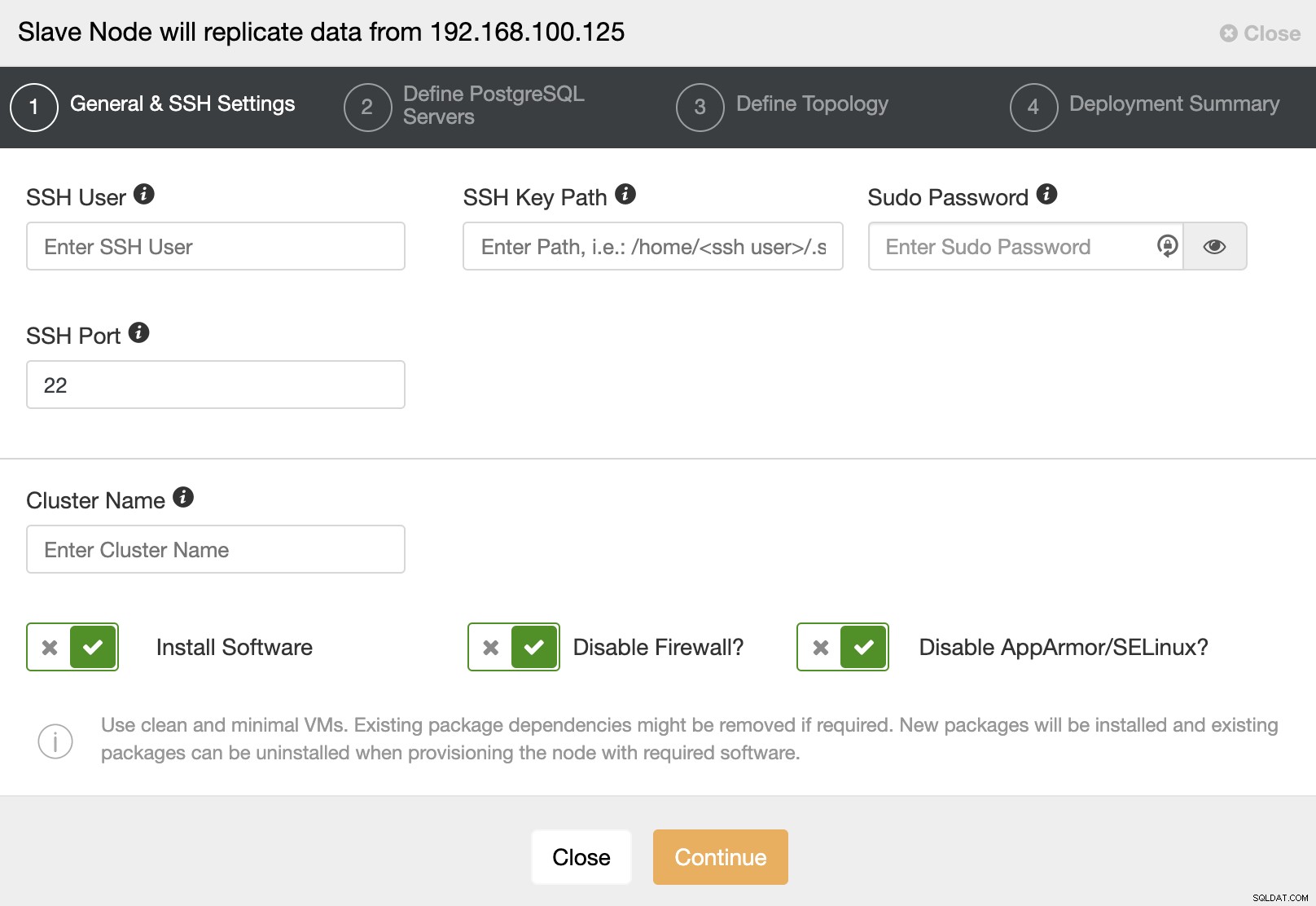
Quando você for para a próxima etapa, você deve especificar User, Key ou Senha e porta para conectar por SSH aos seus servidores. Você também precisa de um nome para o seu Slave Cluster e se quiser que o ClusterControl instale o software e as configurações correspondentes para você.
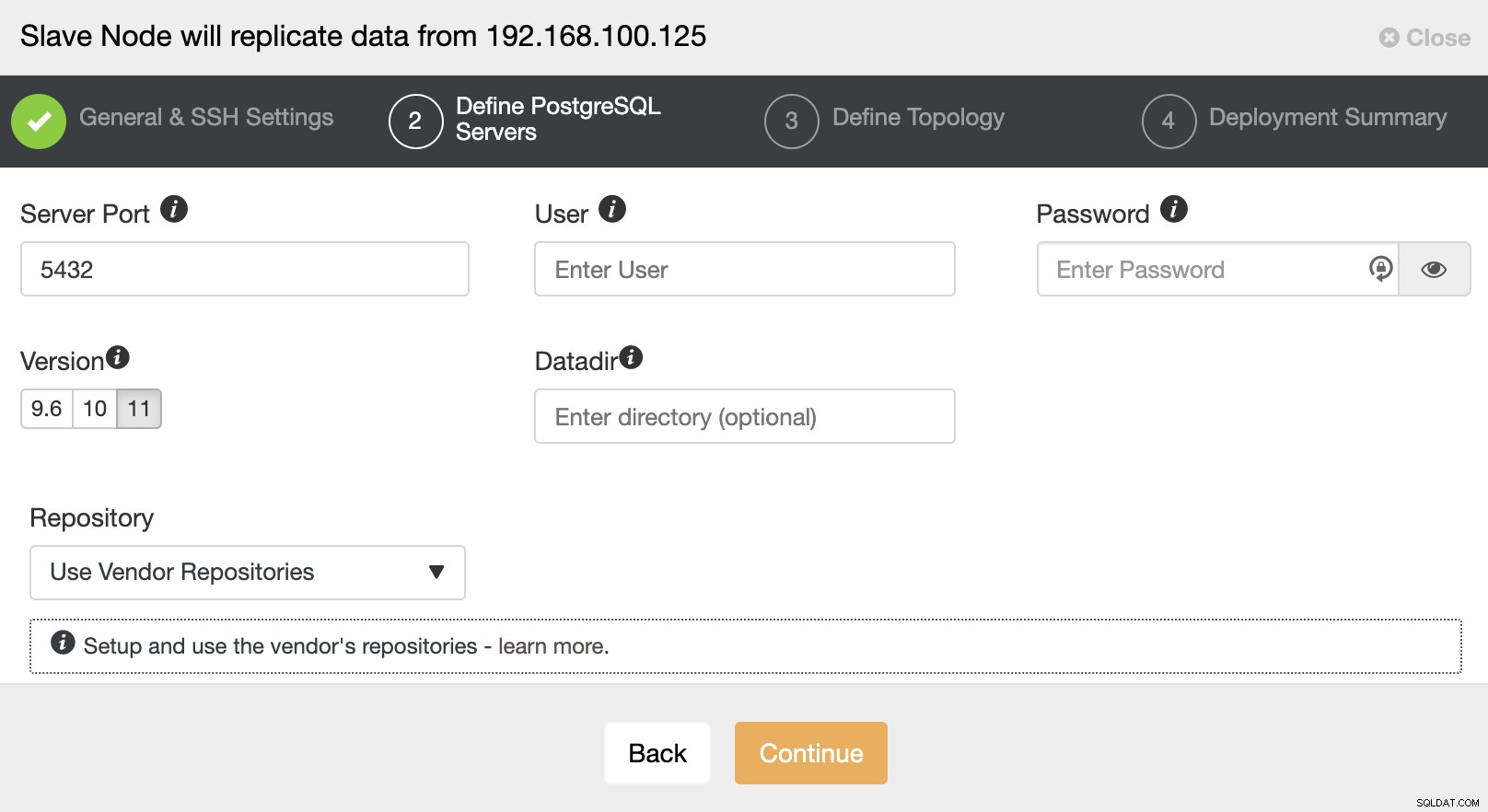
Após configurar as informações de acesso SSH, você deve definir a versão do banco de dados, datadir, porta e credenciais de administrador. Como ele usará a replicação de streaming, certifique-se de usar a mesma versão do banco de dados e, como mencionamos anteriormente, as credenciais devem ser as mesmas usadas pelo Cluster Mestre. Você também pode especificar qual repositório usar.
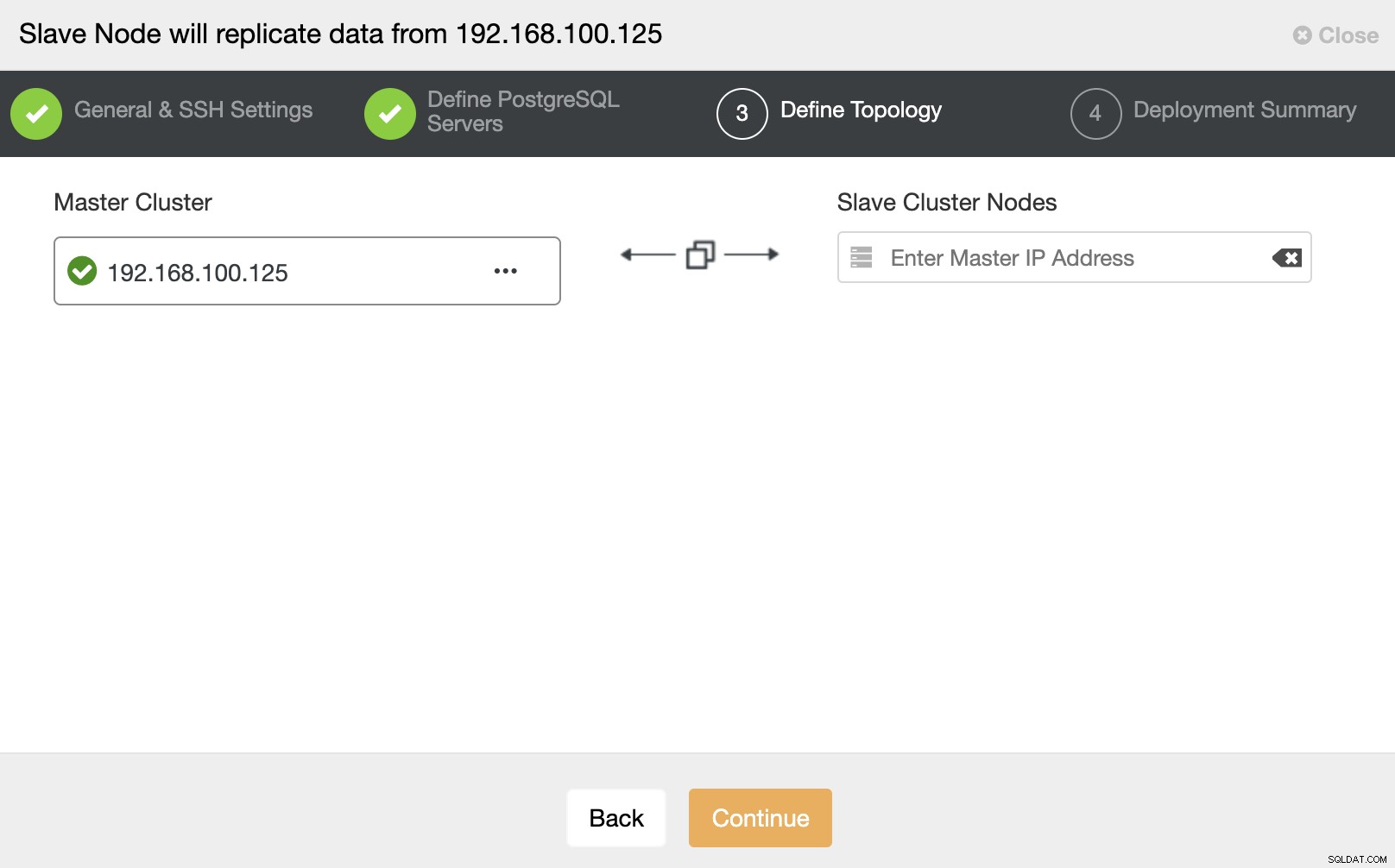
Nesta etapa, você precisa adicionar o servidor ao novo cluster escravo . Para esta tarefa, você pode inserir o endereço IP ou o nome do host do nó do banco de dados.
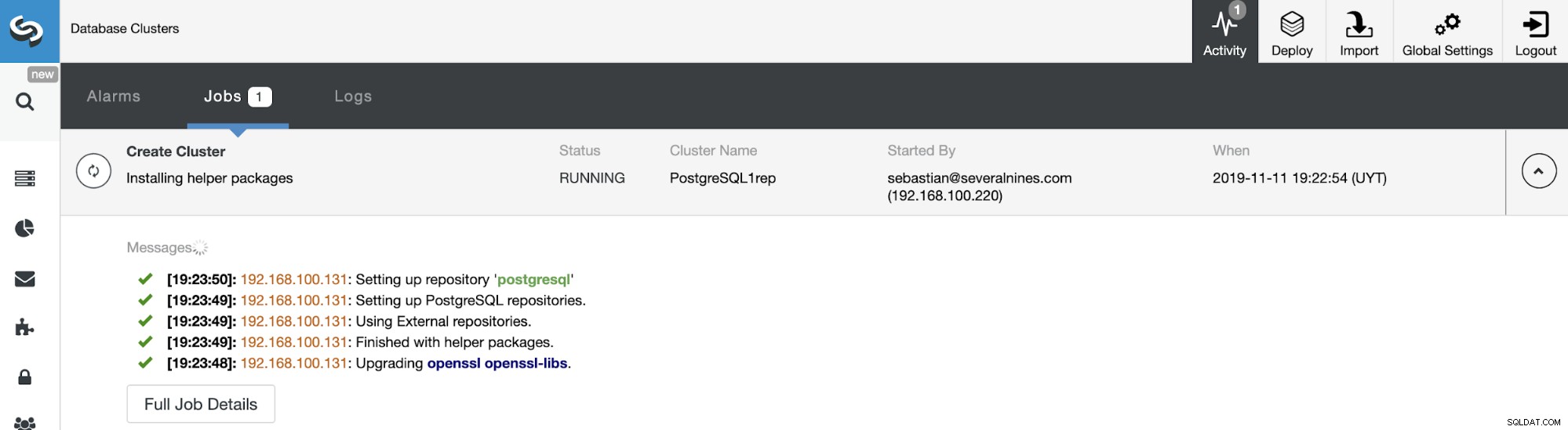
Você pode monitorar o status da criação do seu novo cluster escravo a partir do Monitor de atividade do ClusterControl. Quando a tarefa estiver concluída, você poderá ver o cluster na tela principal do ClusterControl.
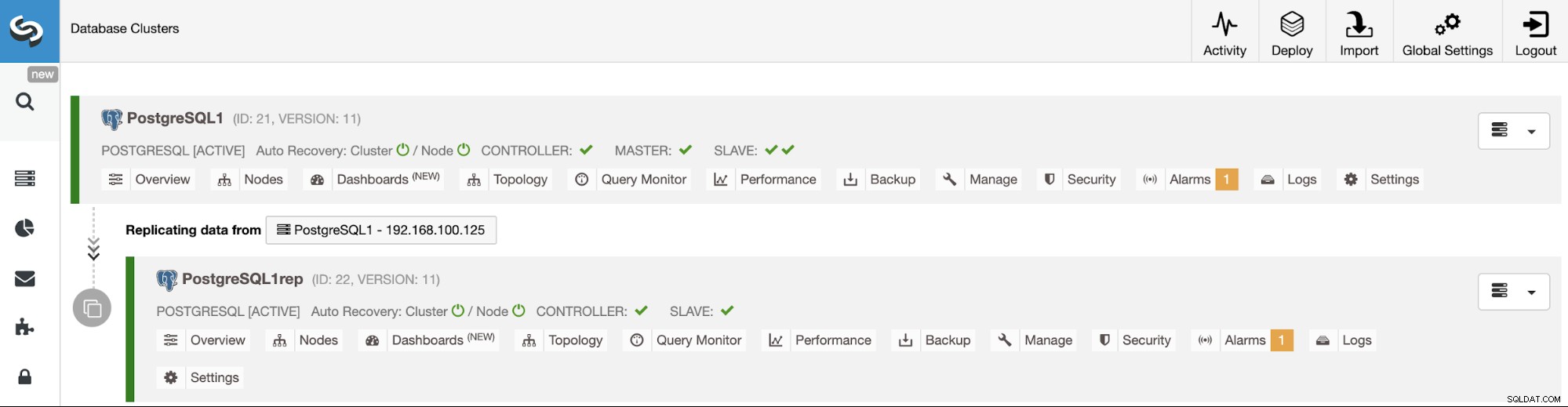
Gerenciando a replicação de cluster para cluster usando a interface do usuário do ClusterControl
Agora que você tem sua replicação de cluster para cluster em execução, há diferentes ações a serem executadas nessa topologia usando o ClusterControl.
Reconstruindo um cluster escravo
Para reconstruir um Cluster Slave, vá para ClusterControl -> Select Slave Cluster -> Nodes -> Escolha o Node conectado ao Master Cluster -> Node Actions -> Rebuild Replication Slave.
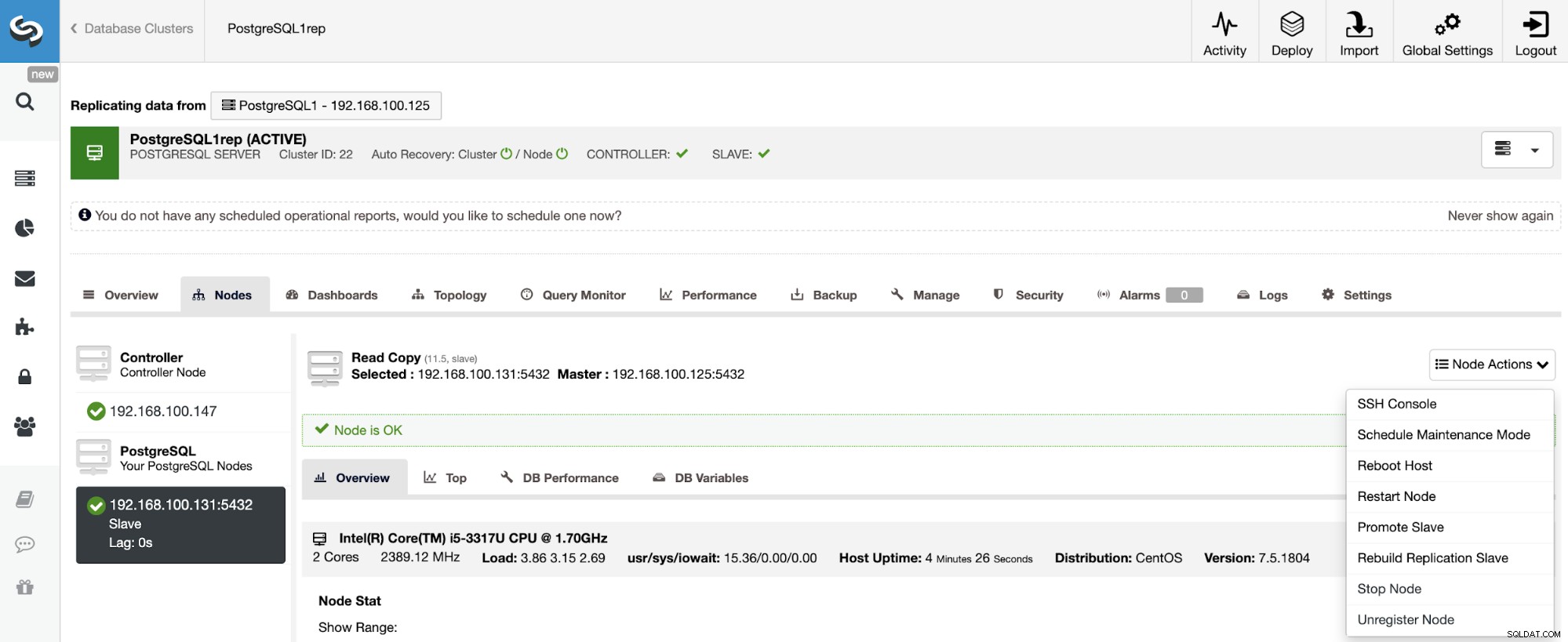
ClusterControl executará as seguintes etapas:
- Parar o servidor PostgreSQL
- Remover conteúdo de seu diretório de dados
- Transmita um backup do mestre para o escravo usando pg_basebackup
- Iniciar o escravo
Parar/Iniciar Escravo de Replicação
Parar e iniciar a replicação no PostgreSQL significa pausar e retomar, mas usamos esses termos para ser consistente com outras tecnologias de banco de dados que suportamos.
Esta função estará disponível para uso na interface do usuário do ClusterControl em breve. Esta ação usará as funções pg_wal_replay_pause e pg_wal_replay_resume do PostgreSQL para realizar esta tarefa.
Enquanto isso, você pode usar uma solução alternativa para parar e iniciar o escravo de replicação parando e iniciando o nó do banco de dados de maneira fácil usando o ClusterControl.
Vá para ClusterControl -> Select Slave Cluster -> Nodes -> Escolha o Nó -> Ações do Nó -> Parar Nó/Iniciar Nó. Esta ação irá parar/iniciar o serviço de banco de dados diretamente.
Gerenciando a replicação de cluster para cluster usando a CLI do ClusterControl
Na seção anterior, você viu como gerenciar uma replicação de cluster para cluster usando a interface do usuário do ClusterControl. Agora, vamos ver como fazer isso usando a linha de comando.
Observação:como mencionamos no início deste blog, presumiremos que você tenha o ClusterControl instalado e o cluster mestre foi implantado usando-o.
Criar o cluster escravo
Primeiro, vamos ver um exemplo de comando para criar um cluster escravo usando a CLI do ClusterControl:
$ s9s cluster --create --cluster-name=PostgreSQL1rep --cluster-type=postgresql --provider-version=11 --nodes="192.168.100.133" --os-user=root --os-key-file=/root/.ssh/id_rsa --db-admin=admin --db-admin-passwd=********* --vendor=postgres --remote-cluster-id=21 --logAgora que você tem seu processo de criação escravo em execução, vamos ver cada parâmetro usado:
- Cluster:para listar e manipular clusters.
- Criar:criar e instalar um novo cluster.
- Nome do cluster:o nome do novo cluster escravo.
- Tipo de cluster:o tipo de cluster a ser instalado.
- Versão do provedor:a versão do software.
- Nós:lista dos novos nós no cluster escravo.
- Os-user:o nome de usuário para os comandos SSH.
- Os-key-file:o arquivo de chave a ser usado para conexão SSH.
- Db-admin:o nome de usuário do administrador do banco de dados.
- Db-admin-passwd:a senha para o administrador do banco de dados.
- Remote-cluster-id:ID do cluster mestre para a replicação de cluster para cluster.
- Log:aguarde e monitore as mensagens de trabalho.
Usando o sinalizador --log, você poderá ver os logs em tempo real:
Verifying job parameters.
192.168.100.133: Checking ssh/sudo.
192.168.100.133: Checking if host already exists in another cluster.
Checking job arguments.
Found top level master node: 192.168.100.133
Verifying nodes.
Checking nodes that those aren't in another cluster.
Checking SSH connectivity and sudo.
192.168.100.133: Checking ssh/sudo.
Checking OS system tools.
Installing software.
Detected centos (core 7.5.1804).
Data directory was not specified. Using directory '/var/lib/pgsql/11/data'.
192.168.100.133:5432: Configuring host and installing packages if neccessary.
...
Cluster 26 is running.
Generated & set RPC authentication token.Reconstruindo um cluster escravo
Você pode reconstruir um cluster escravo usando o seguinte comando:
$ s9s replication --stage --master="192.168.100.125" --slave="192.168.100.133" --cluster-id=26 --remote-cluster-id=21 --logOs parâmetros são:
- Replicação:para monitorar e controlar a replicação de dados.
- Estágio:preparar/reconstruir um escravo de replicação.
- Mestre:o mestre de replicação no cluster mestre.
- Escravo:o escravo de replicação no cluster escravo.
- ID do cluster:o ID do cluster escravo.
- ID do cluster remoto:o ID do cluster mestre.
- Log:aguarde e monitore as mensagens de trabalho.
O log de tarefas deve ser semelhante a este:
Rebuild replication slave 192.168.100.133:5432 from master 192.168.100.125:5432.
Remote cluster id = 21
192.168.100.125: Checking size of '/var/lib/pgsql/11/data'.
192.168.100.125: /var/lib/pgsql/11/data size is 201.13 MiB.
192.168.100.133: Checking free space in '/var/lib/pgsql/11/data'.
192.168.100.133: /var/lib/pgsql/11/data has 28.78 GiB free space.
192.168.100.125:5432(master): Verifying PostgreSQL version.
192.168.100.125: Verifying the timescaledb-postgresql-11 installation.
192.168.100.125: Package timescaledb-postgresql-11 is not installed.
Setting up replication 192.168.100.125:5432->192.168.100.133:5432
Collecting server variables.
192.168.100.125:5432: Using the pg_hba.conf contents for the slave.
192.168.100.125:5432: Will copy the postmaster.opts to the slave.
192.168.100.133:5432: Updating slave configuration.
Writing file '192.168.100.133:/var/lib/pgsql/11/data/postgresql.conf'.
192.168.100.133:5432: GRANT new node on members to do pg_basebackup.
192.168.100.125:5432: granting 192.168.100.133:5432.
192.168.100.133:5432: Stopping slave.
192.168.100.133:5432: Stopping PostgreSQL node.
192.168.100.133: waiting for server to shut down.... done
server stopped
…
192.168.100.133: waiting for server to start....2019-11-12 15:51:11.767 UTC [8005] LOG: listening on IPv4 address "0.0.0.0", port 5432
2019-11-12 15:51:11.767 UTC [8005] LOG: listening on IPv6 address "::", port 5432
2019-11-12 15:51:11.769 UTC [8005] LOG: listening on Unix socket "/var/run/postgresql/.s.PGSQL.5432"
2019-11-12 15:51:11.774 UTC [8005] LOG: listening on Unix socket "/tmp/.s.PGSQL.5432"
2019-11-12 15:51:11.798 UTC [8005] LOG: redirecting log output to logging collector process
2019-11-12 15:51:11.798 UTC [8005] HINT: Future log output will appear in directory "log".
done
server started
192.168.100.133:5432: Grant cluster members on the new node (for failover).
Grant connect access for new host in cluster.
Adding grant on 192.168.100.125:5432.
192.168.100.133:5432: Waiting until the service is started.
Replication slave job finished.Parar/Iniciar Escravo de Replicação
Como mencionamos na seção UI, parar e iniciar a replicação no PostgreSQL significa pausar e retomar, mas usamos esses termos para manter o paralelismo com outras tecnologias.
Você pode parar para replicar os dados do cluster mestre desta forma:
$ s9s replication --stop --slave="192.168.100.133" --cluster-id=26 --logVocê verá isto:
192.168.100.133:5432: Pausing recovery of the slave.
192.168.100.133:5432: Successfully paused recovery on the slave using select pg_wal_replay_pause().E agora, você pode iniciá-lo novamente:
$ s9s replication --start --slave="192.168.100.133" --cluster-id=26 --logEntão, você verá:
192.168.100.133:5432: Resuming recovery on the slave.
192.168.100.133:5432: Collecting replication statistics.
192.168.100.133:5432: Slave resumed recovery successfully using select pg_wal_replay_resume().Agora, vamos verificar os parâmetros usados.
- Replicação:para monitorar e controlar a replicação de dados.
- Parar/Iniciar:Para fazer o escravo parar/iniciar a replicação.
- Escravo:o nó escravo de replicação.
- ID do cluster:o ID do cluster no qual o nó escravo está.
- Log:aguarde e monitore as mensagens de trabalho.
Conclusão
Esse novo recurso ClusterControl permitirá que você configure rapidamente a replicação entre diferentes clusters do PostgreSQL e gerencie a configuração de maneira fácil e amigável. A equipe de desenvolvimento do Multiplenines está trabalhando para melhorar esse recurso, portanto, quaisquer ideias ou sugestões serão muito bem-vindas.