Alta Disponibilidade é um requisito para quase todas as empresas do mundo que usam PostgreSQL É bem conhecido que o PostgreSQL usa Streaming Replication como método de replicação. O PostgreSQL Streaming Replication é assíncrono por padrão, portanto, é possível ter algumas transações confirmadas no nó primário que ainda não foram replicadas para o servidor em espera. Isso significa que existe a possibilidade de alguma perda potencial de dados.
Este atraso no processo de confirmação deve ser muito pequeno... se o servidor em espera for poderoso o suficiente para acompanhar a carga. Se esse pequeno risco de perda de dados não for aceitável na empresa, você também poderá usar a replicação síncrona em vez do padrão.
Na replicação síncrona, cada confirmação de uma transação de gravação aguardará até a confirmação de que a confirmação foi gravada no log de gravação antecipada no disco do servidor primário e de espera.
Este método minimiza a possibilidade de perda de dados. Para que ocorra a perda de dados, você precisa que o primário e o standby falhem ao mesmo tempo.
A desvantagem desse método é a mesma para todos os métodos síncronos, pois com esse método o tempo de resposta para cada transação de gravação aumenta. Isso se deve à necessidade de aguardar até todas as confirmações de que a transação foi confirmada. Felizmente, as transações somente leitura não serão afetadas por isso, mas; apenas as transações de gravação.
Neste blog, você mostra como instalar um cluster PostgreSQL do zero, converter a replicação assíncrona (padrão) em uma síncrona. Também mostrarei como reverter se o tempo de resposta não for aceitável, pois você pode voltar facilmente ao estado anterior. Você verá como implantar, configurar e monitorar uma replicação síncrona do PostgreSQL facilmente usando o ClusterControl usando apenas uma ferramenta para todo o processo.
Instalando um cluster PostgreSQL
Vamos começar a instalar e configurar uma replicação assíncrona do PostgreSQL, que é o modo de replicação usual usado em um cluster PostgreSQL. Usaremos o PostgreSQL 11 no CentOS 7.
Instalação do PostgreSQL
Seguindo o guia de instalação oficial do PostgreSQL, esta tarefa é bem simples.
Primeiro, instale o repositório:
$ yum install https://download.postgresql.org/pub/repos/yum/reporpms/EL-7-x86_64/pgdg-redhat-repo-latest.noarch.rpmInstale os pacotes cliente e servidor PostgreSQL:
$ yum install postgresql11 postgresql11-serverInicialize o banco de dados:
$ /usr/pgsql-11/bin/postgresql-11-setup initdb
$ systemctl enable postgresql-11
$ systemctl start postgresql-11No nó de espera, você pode evitar o último comando (iniciar o serviço de banco de dados), pois restaurará um backup binário para criar a replicação de streaming.
Agora, vamos ver a configuração necessária para uma replicação assíncrona do PostgreSQL.
Configurando a replicação assíncrona do PostgreSQL
Configuração do nó primário
No nó primário do PostgreSQL, você deve usar a seguinte configuração básica para criar uma replicação assíncrona. Os arquivos que serão modificados são postgresql.conf e pg_hba.conf. Em geral, eles estão no diretório de dados (/var/lib/pgsql/11/data/), mas você pode confirmar no lado do banco de dados:
postgres=# SELECT setting FROM pg_settings WHERE name = 'data_directory';
setting
------------------------
/var/lib/pgsql/11/data
(1 row)Postgresql.conf
Altere ou adicione os seguintes parâmetros no arquivo de configuração postgresql.conf.
Aqui você precisa adicionar o(s) endereço(s) IP onde escutar. O valor padrão é 'localhost' e, neste exemplo, usaremos '*' para todos os endereços IP no servidor.
listen_addresses = '*' Defina a porta do servidor onde escutar. Por padrão 5432.
port = 5432 Determine quantas informações são gravadas nos WALs. Os valores possíveis são mínimos, réplicas ou lógicos. O valor hot_standby é mapeado para réplica e é usado para manter a compatibilidade com versões anteriores.
wal_level = hot_standby Defina o número máximo de processos walsender, que gerenciam a conexão com um servidor em espera.
max_wal_senders = 16Defina a quantidade mínima de arquivos WAL a serem mantidos no diretório pg_wal.
wal_keep_segments = 32Alterar esses parâmetros requer uma reinicialização do serviço de banco de dados.
$ systemctl restart postgresql-11Pg_hba.conf
Altere ou adicione os seguintes parâmetros no arquivo de configuração pg_hba.conf.
# TYPE DATABASE USER ADDRESS METHOD
host replication replication_user IP_STANDBY_NODE/32 md5
host replication replication_user IP_PRIMARY_NODE/32 md5Como você pode ver, aqui você precisa adicionar a permissão de acesso do usuário. A primeira coluna é o tipo de conexão, que pode ser host ou local. Em seguida, você precisa especificar o banco de dados (replicação), usuário, endereço IP de origem e método de autenticação. A alteração deste arquivo requer um recarregamento do serviço de banco de dados.
$ systemctl reload postgresql-11Você deve adicionar essa configuração nos nós primário e em espera, pois você precisará dela se o nó em espera for promovido a mestre em caso de falha.
Agora, você deve criar um usuário de replicação.
Função de replicação
O ROLE (usuário) deve ter privilégio REPLICATION para usá-lo na replicação de streaming.
postgres=# CREATE ROLE replication_user WITH LOGIN PASSWORD 'PASSWORD' REPLICATION;
CREATE ROLEApós configurar os arquivos correspondentes e a criação do usuário, você precisa criar um backup consistente do nó primário e restaurá-lo no nó em espera.
Configuração do nó em espera
No nó standby, vá para o diretório /var/lib/pgsql/11/ e mova ou remova o datadir atual:
$ cd /var/lib/pgsql/11/
$ mv data data.bkEm seguida, execute o comando pg_basebackup para obter o datadir primário atual e atribuir o proprietário correto (postgres):
$ pg_basebackup -h 192.168.100.145 -D /var/lib/pgsql/11/data/ -P -U replication_user --wal-method=stream
$ chown -R postgres.postgres dataAgora, você deve usar a seguinte configuração básica para criar uma replicação assíncrona. O arquivo que será modificado é postgresql.conf, e você precisa criar um novo arquivo recovery.conf. Ambos estarão localizados em /var/lib/pgsql/11/.
Recovery.conf
Especifique que este servidor será um servidor em espera. Se estiver ativado, o servidor continuará recuperando buscando novos segmentos WAL quando o fim do WAL arquivado for atingido.
standby_mode = 'on'Especifique uma cadeia de conexão a ser usada para que o servidor em espera se conecte ao nó primário.
primary_conninfo = 'host=IP_PRIMARY_NODE port=5432 user=replication_user password=PASSWORD'Especifique a recuperação em uma linha do tempo específica. O padrão é recuperar na mesma linha do tempo que estava atual quando o backup básico foi feito. Definir isso como "mais recente" recupera a linha do tempo mais recente encontrada no arquivo.
recovery_target_timeline = 'latest'Especifique um arquivo acionador cuja presença finalize a recuperação no modo de espera.
trigger_file = '/tmp/failover_5432.trigger'Postgresql.conf
Altere ou adicione os seguintes parâmetros no arquivo de configuração postgresql.conf.
Determine a quantidade de informações gravadas nos WALs. Os valores possíveis são mínimos, réplicas ou lógicos. O valor hot_standby é mapeado para réplica e é usado para manter a compatibilidade com versões anteriores. Alterar esse valor requer uma reinicialização do serviço.
wal_level = hot_standbyPermitir as consultas durante a recuperação. Alterar esse valor requer uma reinicialização do serviço.
hot_standby = onIniciando nó de espera
Agora que você tem toda a configuração necessária, basta iniciar o serviço de banco de dados no nó de espera.
$ systemctl start postgresql-11E verifique os logs do banco de dados em /var/lib/pgsql/11/data/log/. Você deve ter algo assim:
2019-11-18 20:23:57.440 UTC [1131] LOG: entering standby mode
2019-11-18 20:23:57.447 UTC [1131] LOG: redo starts at 0/3000028
2019-11-18 20:23:57.449 UTC [1131] LOG: consistent recovery state reached at 0/30000F8
2019-11-18 20:23:57.449 UTC [1129] LOG: database system is ready to accept read only connections
2019-11-18 20:23:57.457 UTC [1135] LOG: started streaming WAL from primary at 0/4000000 on timeline 1Você também pode verificar o status de replicação no nó primário executando a seguinte consulta:
postgres=# SELECT pid,usename,application_name,state,sync_state FROM pg_stat_replication;
pid | usename | application_name | state | sync_state
------+------------------+------------------+-----------+------------
1467 | replication_user | walreceiver | streaming | async
(1 row)Como você pode ver, estamos usando uma replicação assíncrona.
Conversão de replicação assíncrona do PostgreSQL em replicação síncrona
Agora, é hora de converter essa replicação assíncrona em uma sincronizada e, para isso, você precisará configurar o nó principal e o nó de espera.
Nó primário
No nó primário do PostgreSQL, você deve usar essa configuração básica além da configuração assíncrona anterior.
Postgresql.conf
Especifique uma lista de servidores em espera que podem dar suporte à replicação síncrona. Esse nome de servidor em espera é a configuração application_name no arquivo recovery.conf do standby.
synchronous_standby_names = 'pgsql_0_node_0'synchronous_standby_names = 'pgsql_0_node_0'Especifica se a confirmação da transação aguardará que os registros WAL sejam gravados no disco antes que o comando retorne uma indicação de “sucesso” ao cliente. Os valores válidos são on, remote_apply, remote_write, local e off. O valor padrão está ativado.
synchronous_commit = onConfiguração do nó em espera
No nó standby do PostgreSQL, você precisa alterar o arquivo recovery.conf adicionando o valor 'application_name no parâmetro primary_conninfo.
Recovery.conf
standby_mode = 'on'
primary_conninfo = 'application_name=pgsql_0_node_0 host=IP_PRIMARY_NODE port=5432 user=replication_user password=PASSWORD'
recovery_target_timeline = 'latest'
trigger_file = '/tmp/failover_5432.trigger'Reinicie o serviço de banco de dados nos nós primário e em espera:
$ service postgresql-11 restartAgora, você deve ter sua replicação de streaming de sincronização funcionando:
postgres=# SELECT pid,usename,application_name,state,sync_state FROM pg_stat_replication;
pid | usename | application_name | state | sync_state
------+------------------+------------------+-----------+------------
1561 | replication_user | pgsql_0_node_0 | streaming | sync
(1 row)Reversão de replicação síncrona para assíncrona do PostgreSQL
Se você precisar voltar para a replicação assíncrona do PostgreSQL, basta reverter as alterações realizadas no arquivo postgresql.conf no nó primário:
Postgresql.conf
#synchronous_standby_names = 'pgsql_0_node_0'
#synchronous_commit = onE reinicie o serviço de banco de dados.
$ service postgresql-11 restartAgora, você deve ter a replicação assíncrona novamente.
postgres=# SELECT pid,usename,application_name,state,sync_state FROM pg_stat_replication;
pid | usename | application_name | state | sync_state
------+------------------+------------------+-----------+------------
1625 | replication_user | pgsql_0_node_0 | streaming | async
(1 row)Como implantar uma replicação síncrona do PostgreSQL usando o ClusterControl
Com o ClusterControl, você pode executar as tarefas de implantação, configuração e monitoramento tudo em um a partir do mesmo trabalho e poderá gerenciá-lo a partir da mesma interface do usuário.
Vamos supor que você tenha o ClusterControl instalado e ele possa acessar os nós do banco de dados via SSH. Para obter mais informações sobre como configurar o acesso ao ClusterControl, consulte nossa documentação oficial.
Vá para ClusterControl e use a opção “Deploy” para criar um novo cluster PostgreSQL.
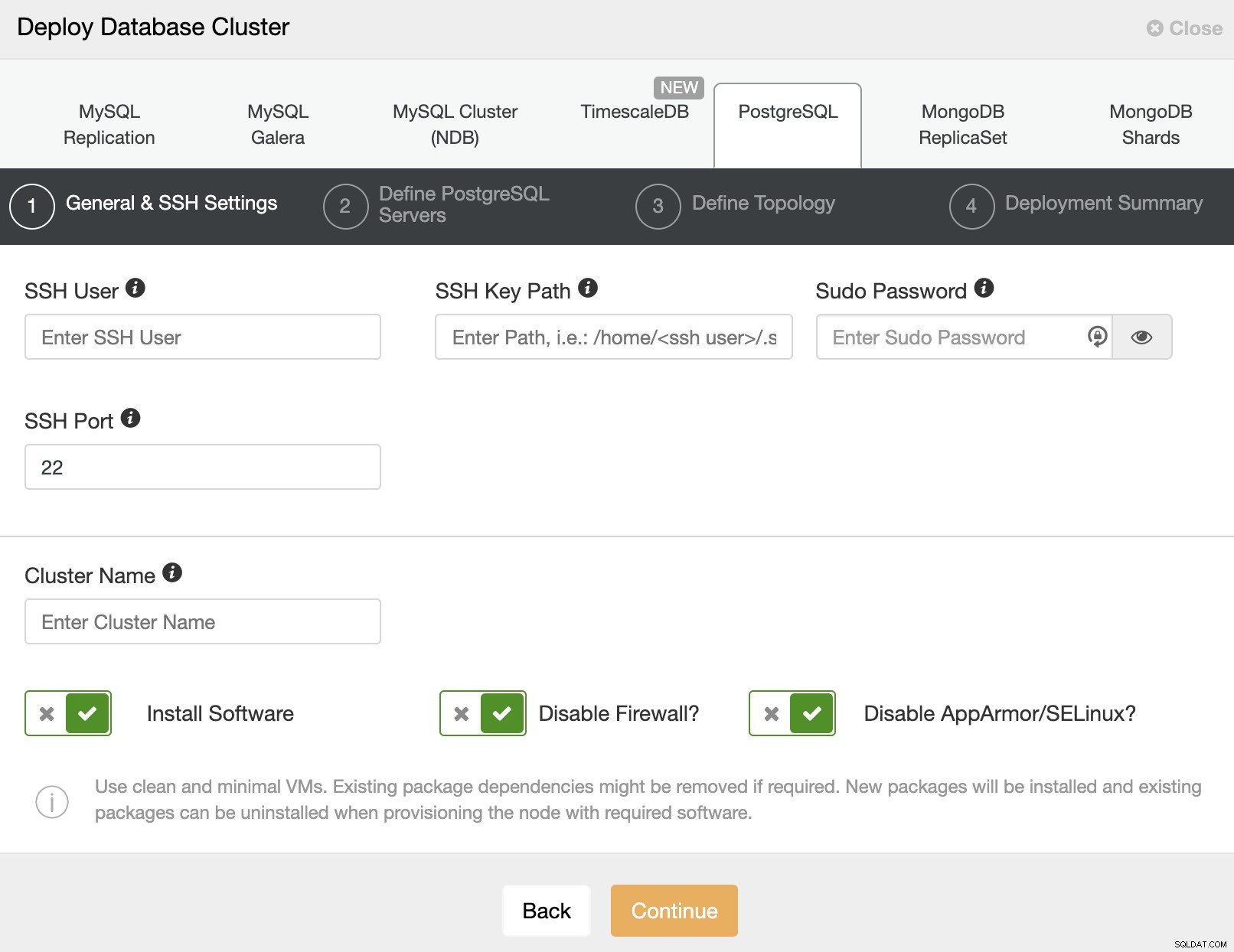
Ao selecionar PostgreSQL, você deve especificar Usuário, Chave ou Senha e um porta para se conectar por SSH aos nossos servidores. Você também precisa de um nome para seu novo cluster e se quiser que o ClusterControl instale o software e as configurações correspondentes para você.
Após configurar as informações de acesso SSH, você deve inserir os dados para acessar seu banco de dados. Você também pode especificar qual repositório usar.
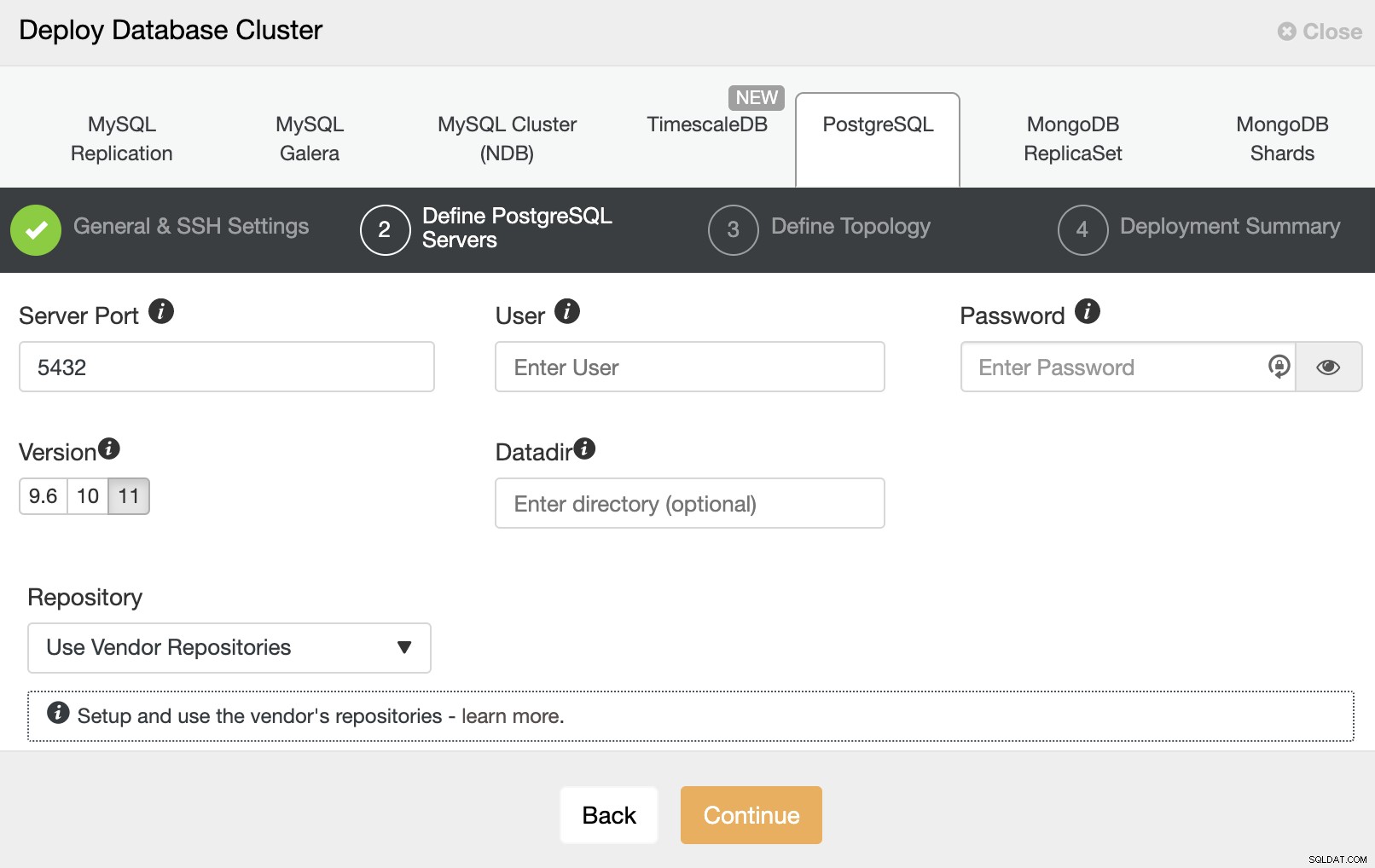
Na próxima etapa, você precisa adicionar seus servidores ao cluster que você vai criar. Ao adicionar seus servidores, você pode inserir o IP ou o nome do host.
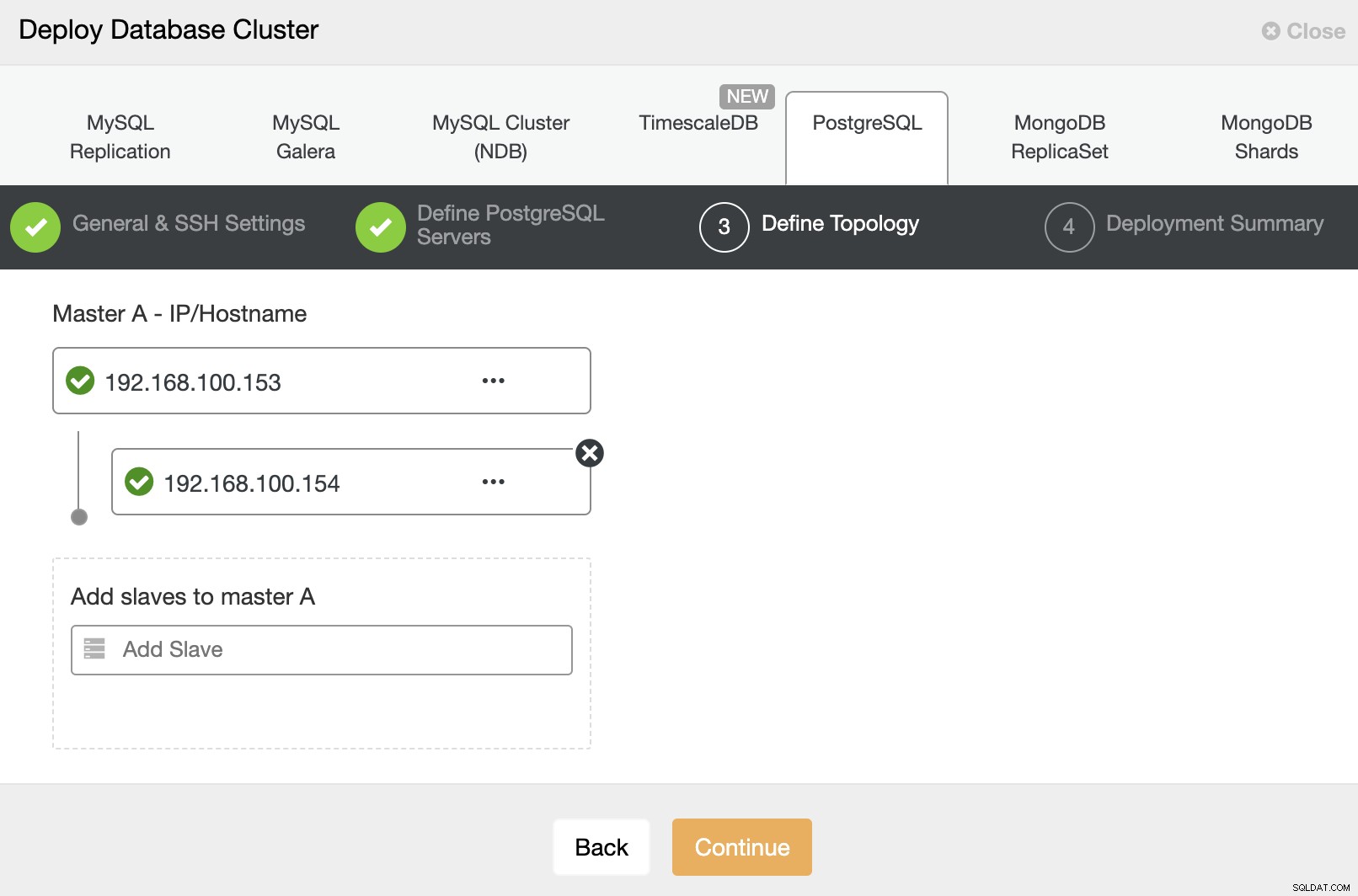
E finalmente, na última etapa, você pode escolher o método de replicação, que pode ser replicação assíncrona ou síncrona.
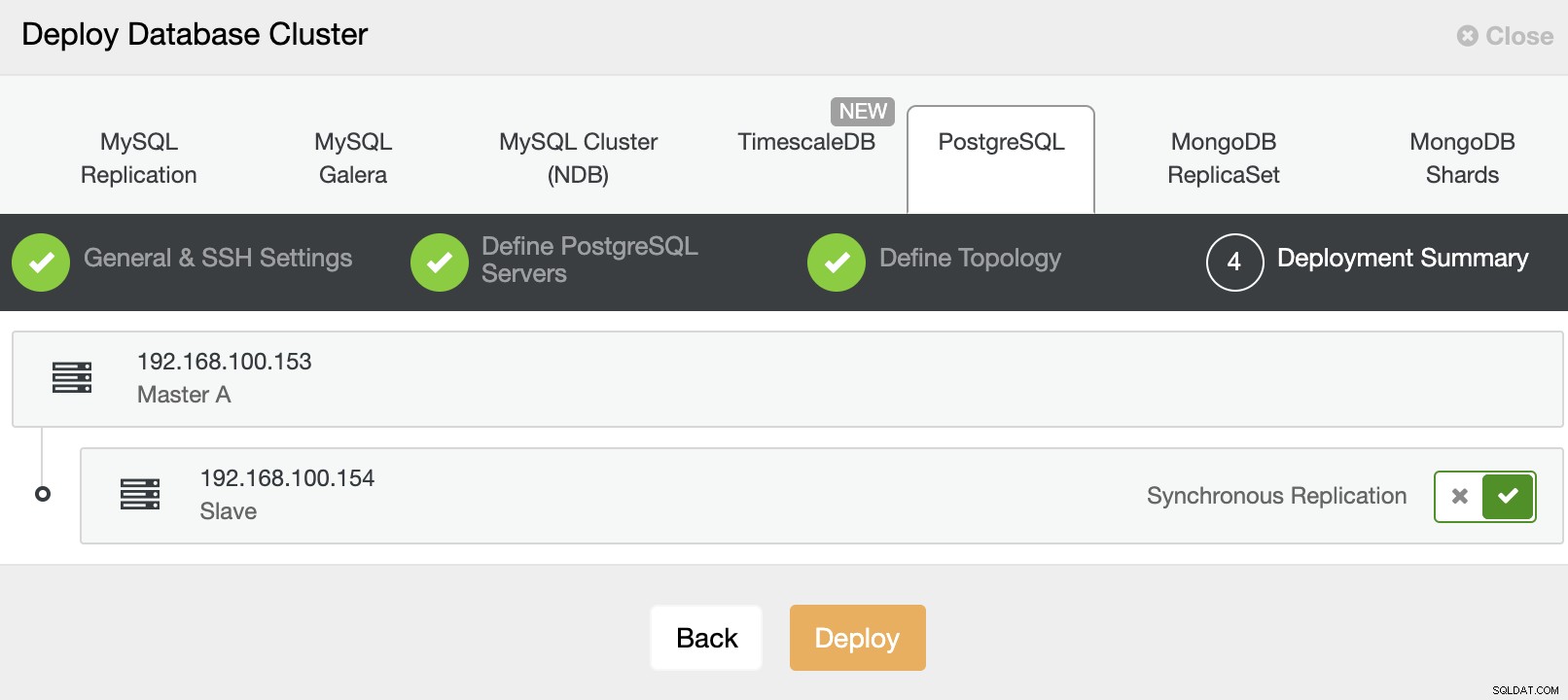
É isso. Você pode monitorar o status do trabalho na seção de atividade do ClusterControl.
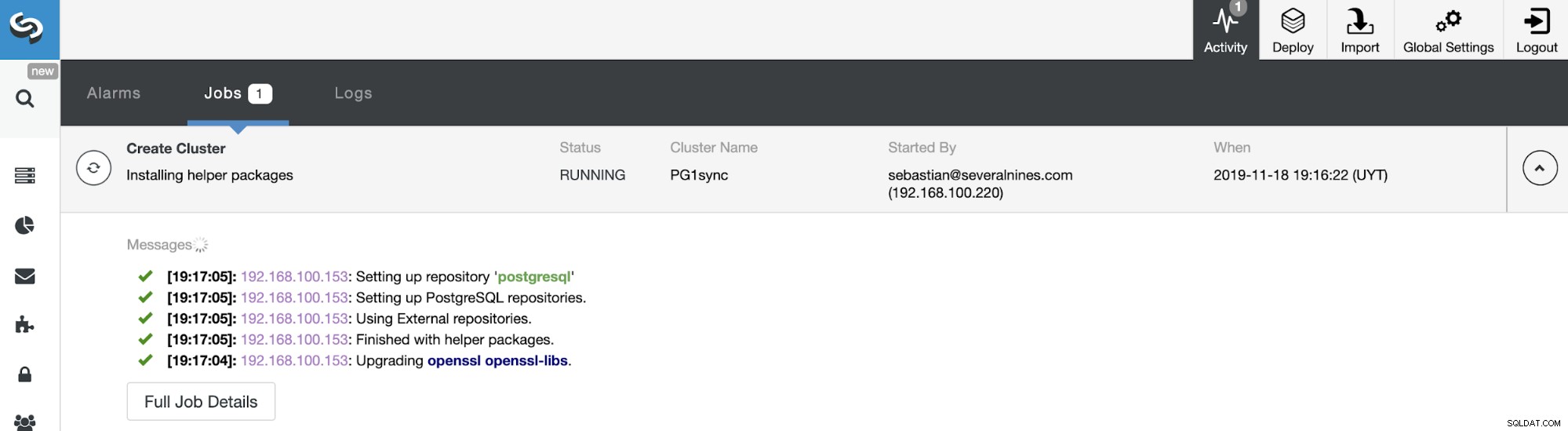
E quando este trabalho terminar, você terá seu cluster síncrono PostgreSQL instalado, configurado e monitorado pelo ClusterControl.
Conclusão
Como mencionamos no início deste blog, a Alta Disponibilidade é um requisito para todas as empresas, portanto, você deve conhecer as opções disponíveis para alcançá-la para cada tecnologia em uso. Para o PostgreSQL, você pode usar a replicação de streaming síncrona como a maneira mais segura de implementá-la, mas esse método não funciona para todos os ambientes e cargas de trabalho.
Cuidado com a latência gerada pela espera da confirmação de cada transação que pode ser um problema ao invés de uma solução de Alta Disponibilidade.