Hoje em dia, é comum ver uma grande quantidade de dados no banco de dados de uma empresa, mas dependendo do tamanho, pode ser difícil de gerenciar e o desempenho pode ser afetado durante o tráfego intenso se não o configurarmos ou implementarmos de maneira correta . Em geral, se temos um banco de dados enorme e queremos ter um tempo de resposta baixo, queremos escalá-lo. O PostgreSQL não é exceção a este ponto. Existem muitas abordagens disponíveis para dimensionar o PostgreSQL, mas primeiro, vamos aprender o que é dimensionamento.
Escalabilidade é a propriedade de um sistema/banco de dados para lidar com uma quantidade crescente de demandas adicionando recursos.
As razões para essa quantidade de demandas podem ser temporais, por exemplo, se estamos lançando um desconto em uma venda, ou permanentes, por aumento de clientes ou funcionários. De qualquer forma, devemos poder adicionar ou remover recursos para gerenciar essas mudanças nas demandas ou aumento do tráfego.
Neste blog, veremos como podemos dimensionar nosso banco de dados PostgreSQL e quando precisamos fazê-lo.
Escalonamento horizontal x dimensionamento vertical
Existem duas maneiras principais de dimensionar nosso banco de dados...
- Escalonamento horizontal (escalonamento horizontal):é realizado adicionando mais nós de banco de dados criando ou aumentando um cluster de banco de dados.
- Escalonamento vertical (escalonamento):é realizado adicionando mais recursos de hardware (CPU, memória, disco) a um nó de banco de dados existente.
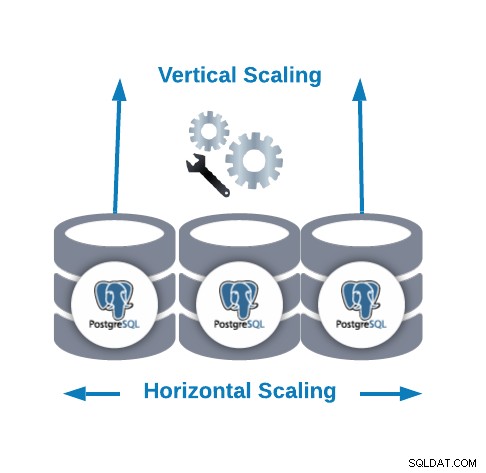
Para Escala Horizontal, podemos adicionar mais nós de banco de dados como nós escravos. Isso pode nos ajudar a melhorar o desempenho de leitura equilibrando o tráfego entre os nós. Nesse caso, precisaremos adicionar um balanceador de carga para distribuir o tráfego para o nó correto, dependendo da política e do estado do nó.
Para evitar um único ponto de falha adicionando apenas um balanceador de carga, devemos considerar adicionar dois ou mais nós do balanceador de carga e usar alguma ferramenta como “Keepalived”, para garantir a disponibilidade.
Como o PostgreSQL não possui suporte multi-mestre nativo, se quisermos implementá-lo para melhorar o desempenho de gravação, precisaremos usar uma ferramenta externa para esta tarefa.
Para Vertical Scaling, pode ser necessário alterar algum parâmetro de configuração para permitir que o PostgreSQL use um recurso de hardware novo ou melhor. Vamos ver alguns desses parâmetros da documentação do PostgreSQL.
- work_mem:especifica a quantidade de memória a ser usada por operações de classificação interna e tabelas de hash antes de gravar em arquivos de disco temporários. Várias sessões em execução podem estar realizando essas operações simultaneamente, portanto, a memória total usada pode ser muitas vezes o valor de work_mem.
- maintenance_work_mem:especifica a quantidade máxima de memória a ser usada pelas operações de manutenção, como VACUUM, CREATE INDEX e ALTER TABLE ADD FOREIGN KEY. Configurações maiores podem melhorar o desempenho de limpeza e restauração de despejos de banco de dados.
- autovacuum_work_mem:especifica a quantidade máxima de memória a ser usada por cada processo de trabalho de autovacuum.
- autovacuum_max_workers:especifica o número máximo de processos de autovacuum que podem estar em execução ao mesmo tempo.
- max_worker_processes:define o número máximo de processos em segundo plano que o sistema pode suportar. Especifique o limite do processo, como limpeza, pontos de verificação e mais trabalhos de manutenção.
- max_parallel_workers:define o número máximo de trabalhadores que o sistema pode suportar para operações paralelas. Trabalhadores paralelos são retirados do conjunto de processos de trabalho estabelecido pelo parâmetro anterior.
- max_parallel_maintenance_workers:define o número máximo de trabalhadores paralelos que podem ser iniciados por um único comando de utilitário. Atualmente, o único comando de utilitário paralelo que suporta o uso de trabalhadores paralelos é CREATE INDEX e somente ao construir um índice de árvore B.
- effective_cache_size:define a suposição do planejador sobre o tamanho efetivo do cache de disco que está disponível para uma única consulta. Isso é levado em consideração nas estimativas do custo de usar um índice; um valor mais alto torna mais provável que varreduras de índice sejam usadas, um valor mais baixo torna mais provável que varreduras sequenciais sejam usadas.
- shared_buffers:define a quantidade de memória que o servidor de banco de dados usa para buffers de memória compartilhada. Geralmente, são necessárias configurações significativamente mais altas que o mínimo para um bom desempenho.
- temp_buffers:define o número máximo de buffers temporários usados por cada sessão do banco de dados. Esses são buffers de sessão local usados apenas para acesso a tabelas temporárias.
- effective_io_concurrency:Define o número de operações de E/S de disco simultâneas que o PostgreSQL espera que possam ser executadas simultaneamente. Aumentar esse valor aumentará o número de operações de E/S que qualquer sessão individual do PostgreSQL tenta iniciar em paralelo. Atualmente, essa configuração afeta apenas verificações de heap de bitmap.
- max_connections:determina o número máximo de conexões simultâneas com o servidor de banco de dados. Aumentar este parâmetro permite que o PostgreSQL execute mais processos de back-end simultaneamente.
Neste ponto, há uma pergunta que devemos fazer. Como podemos saber se precisamos dimensionar nosso banco de dados e como podemos saber a melhor maneira de fazê-lo?
Monitoramento
Dimensionar nosso banco de dados PostgreSQL é um processo complexo, por isso devemos verificar algumas métricas para poder determinar a melhor estratégia para dimensioná-lo.
Podemos monitorar o uso de CPU, Memória e Disco para determinar se há algum problema de configuração ou se realmente precisamos dimensionar nosso banco de dados. Por exemplo, se estamos vendo uma alta carga do servidor, mas a atividade do banco de dados é baixa, provavelmente não é necessário escaloná-lo, precisamos apenas verificar os parâmetros de configuração para combiná-lo com nossos recursos de hardware.
A verificação do espaço em disco utilizado pelo nodo PostgreSQL por banco de dados pode nos ajudar a confirmar se precisamos de mais disco ou até mesmo de um particionamento de tabela. Para verificar o espaço em disco usado por um banco de dados/tabela podemos usar alguma função do PostgreSQL como pg_database_size ou pg_table_size.
Do lado do banco de dados, devemos verificar
- Quantidade de conexão
- Executando consultas
- Uso do índice
- Inchar
- Atraso de replicação
Essas podem ser métricas claras para confirmar se o dimensionamento do nosso banco de dados é necessário.
ClusterControl como um sistema de dimensionamento e monitoramento
O ClusterControl pode nos ajudar a lidar com as duas formas de dimensionamento que vimos anteriormente e monitorar todas as métricas necessárias para confirmar o requisito de dimensionamento. Vamos ver como...
Se você ainda não está usando o ClusterControl, você pode instalá-lo e implantar ou importar seu banco de dados PostgreSQL atual selecionando a opção “Importar” e seguir os passos, para aproveitar todos os recursos do ClusterControl como backups, failover automático, alertas, monitoramento, e mais.
Escala horizontal
Para dimensionamento horizontal, se formos para ações de cluster e selecionarmos “Add Replication Slave”, podemos criar uma nova réplica do zero ou adicionar um banco de dados PostgreSQL existente como uma réplica.
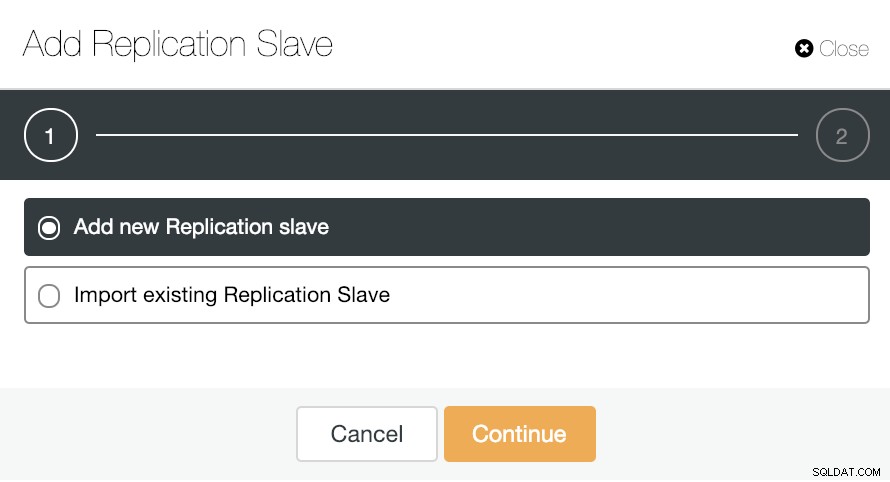
Vamos ver como adicionar um novo slave de replicação pode ser uma tarefa muito fácil.
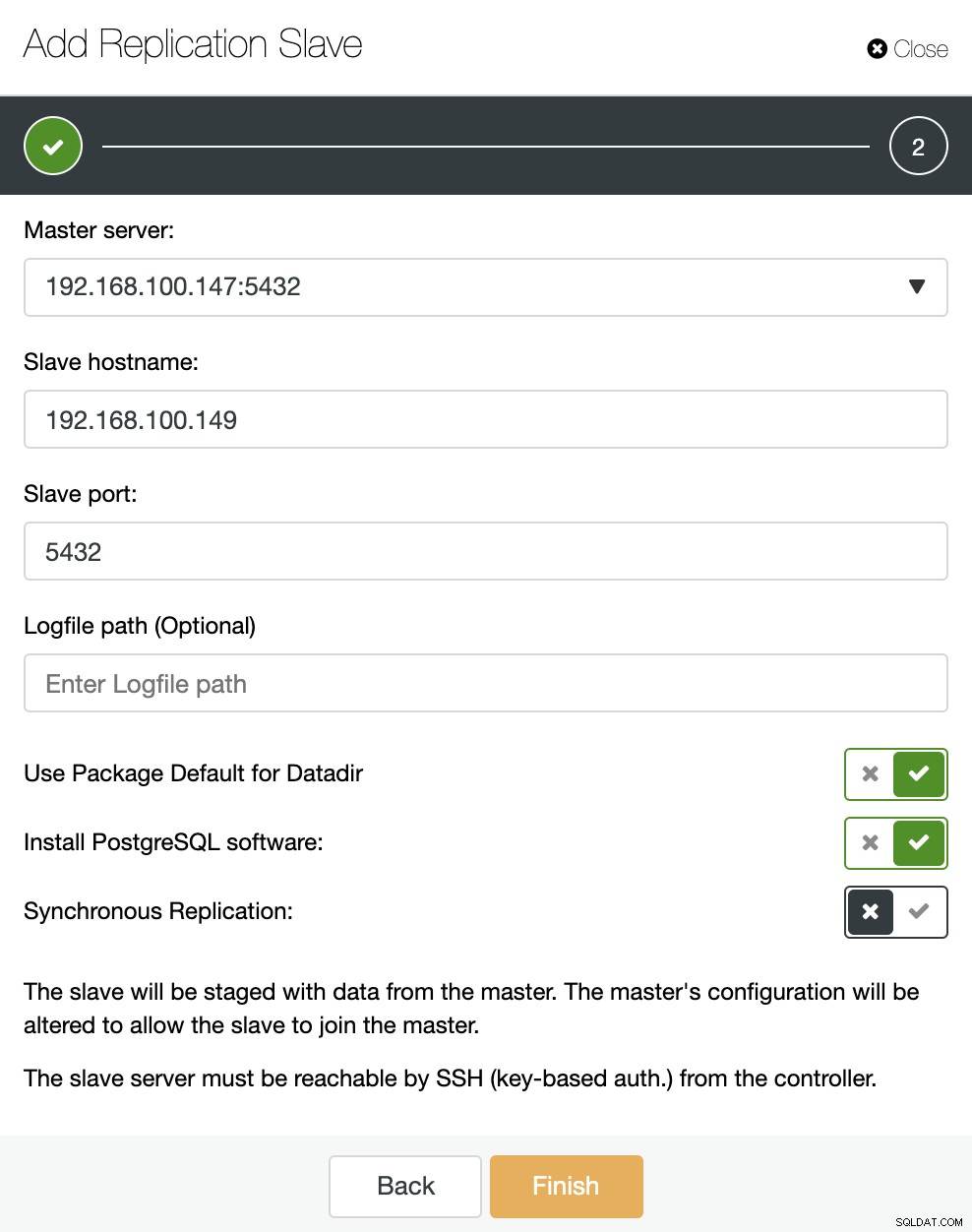
Como você pode ver na imagem, só precisamos escolher nosso servidor Master, inserir o endereço IP do nosso novo servidor slave e a porta do banco de dados. Então, podemos escolher se queremos que o ClusterControl instale o software para nós e se o escravo de replicação deve ser Síncrono ou Assíncrono.
Dessa forma, podemos adicionar quantas réplicas quisermos e distribuir o tráfego de leitura entre elas usando um balanceador de carga, que também podemos implementar com o ClusterControl.
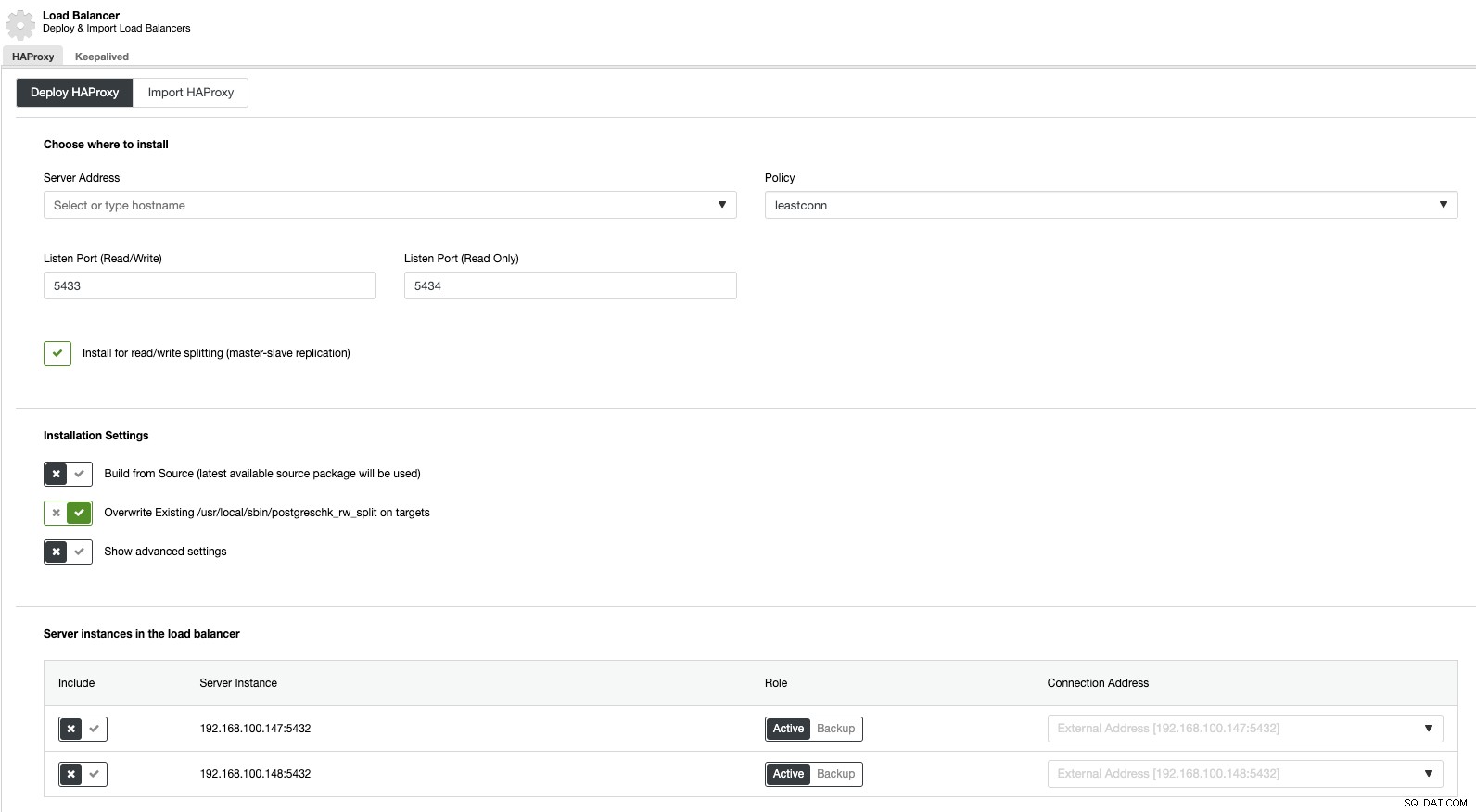
Agora, se formos para ações de cluster e selecionarmos “Add Load Balancer”, podemos implantar um novo HAProxy Load Balancer ou adicionar um existente.
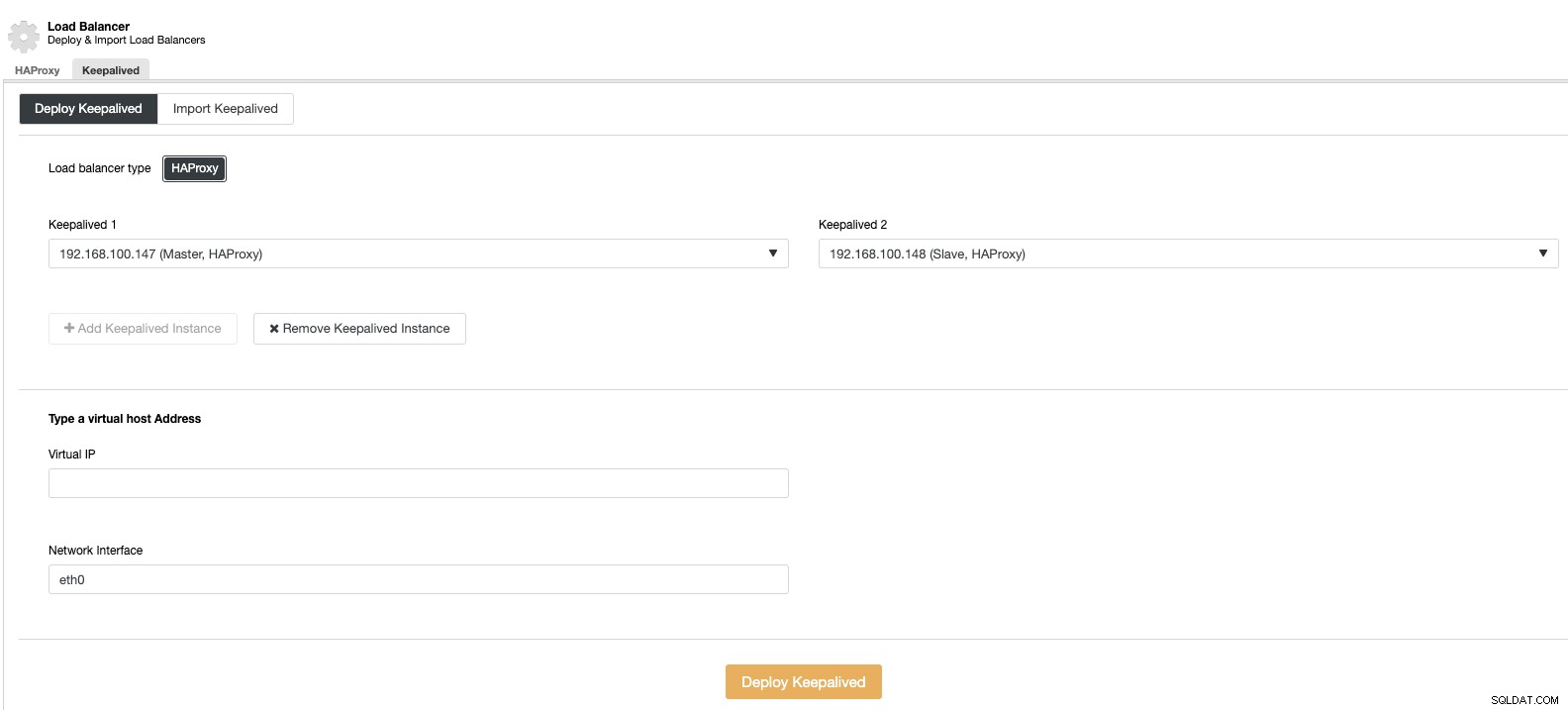
E então, na mesma seção do balanceador de carga, podemos adicionar um serviço Keepalived em execução nos nós do balanceador de carga para melhorar nosso ambiente de alta disponibilidade.
Escala Vertical
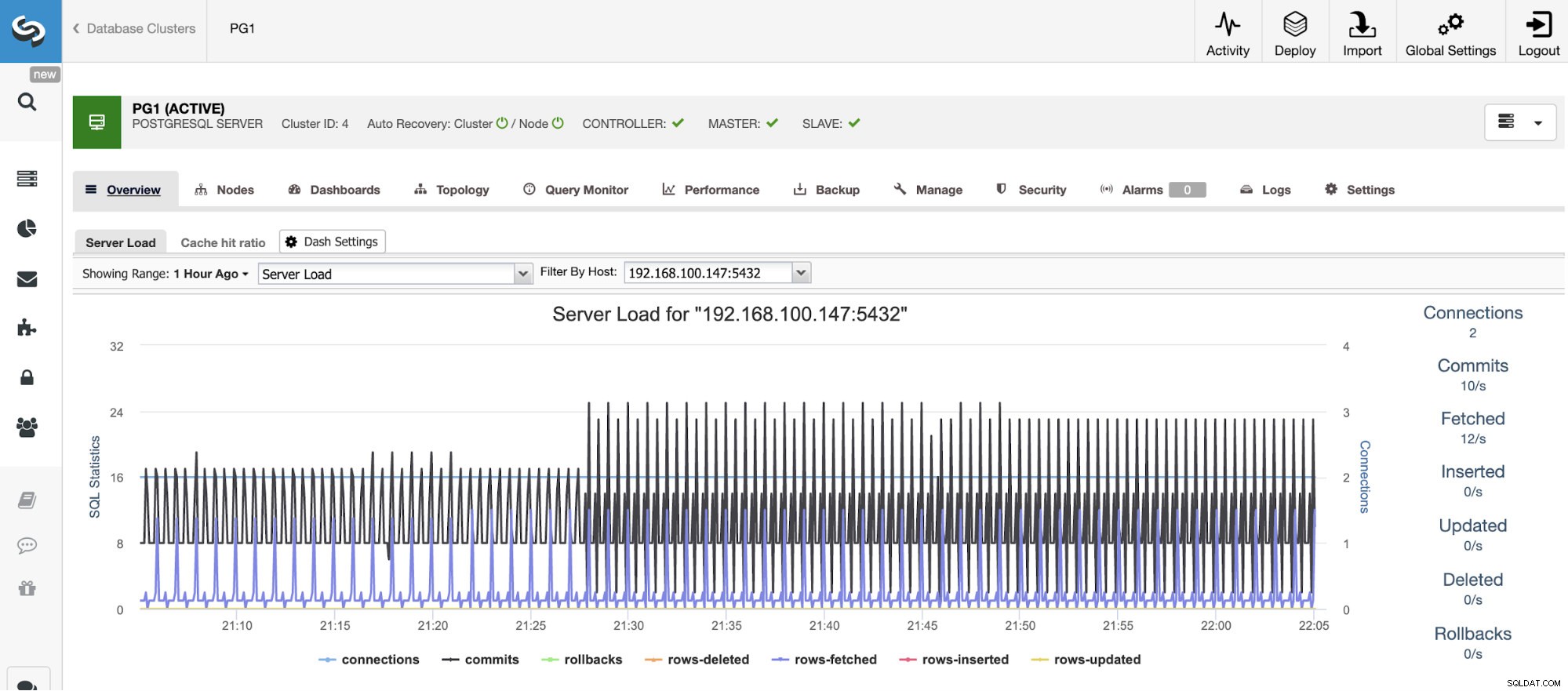
Para dimensionamento vertical, com o ClusterControl podemos monitorar nossos nós de banco de dados tanto do sistema operacional quanto do lado do banco de dados. Podemos verificar algumas métricas como uso de CPU, memória, conexões, principais consultas, consultas em execução e muito mais. Também podemos habilitar a seção Dashboard, que nos permite ver as métricas de forma mais detalhada e de forma mais amigável nossas métricas.
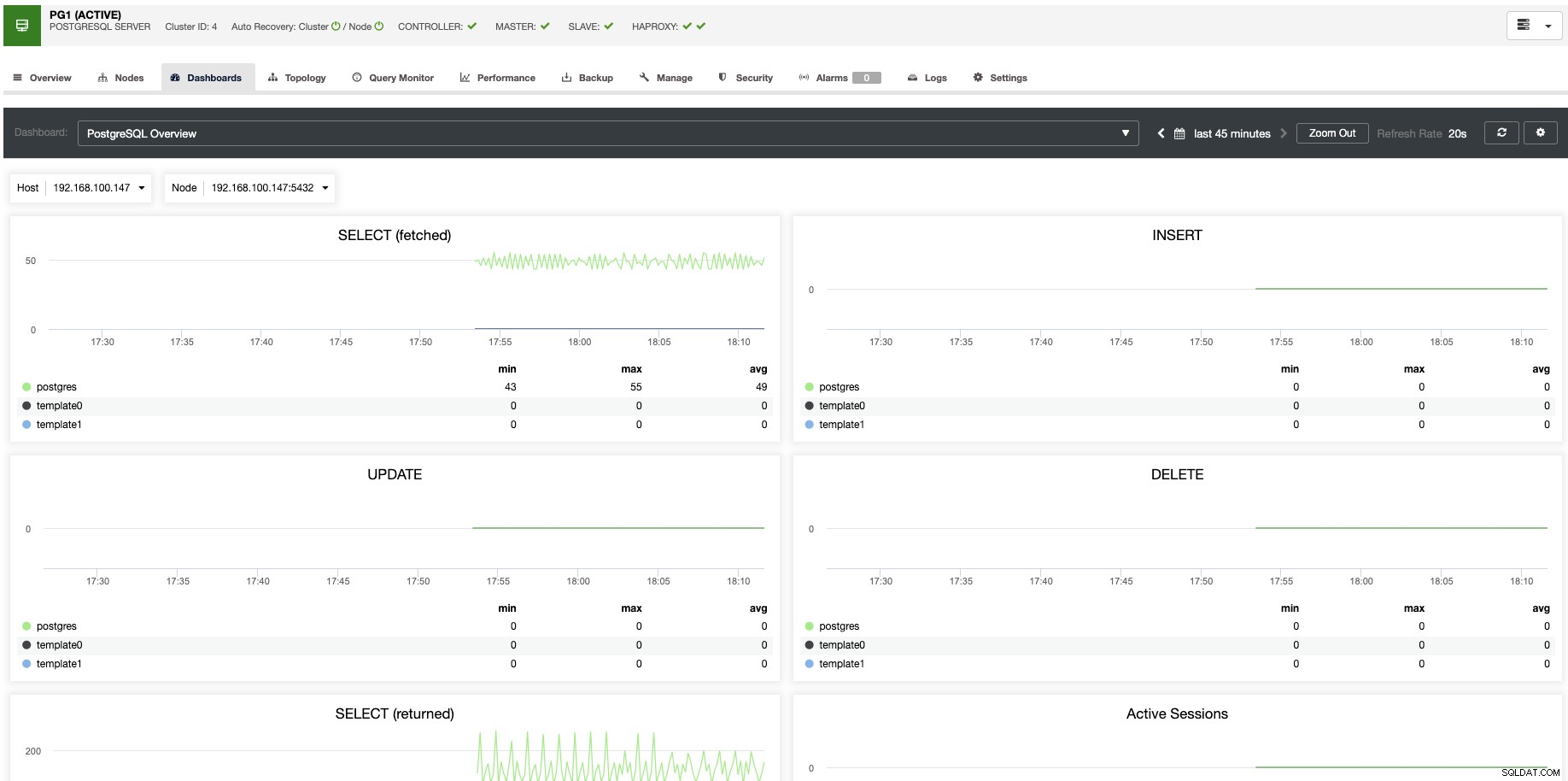
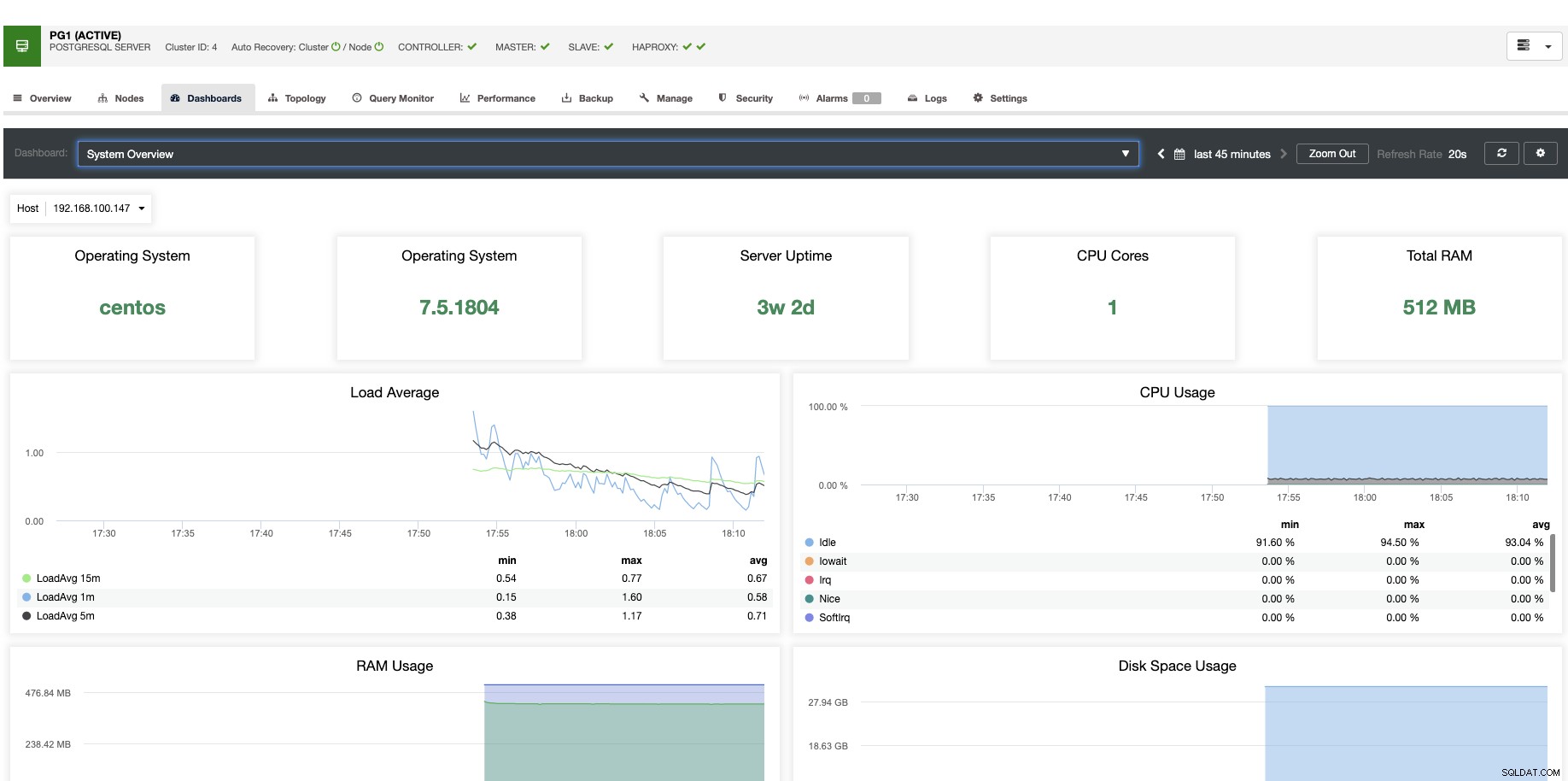
A partir do ClusterControl, você também pode executar diferentes tarefas de gerenciamento como Reboot Host, Rebuild Replication Slave ou Promover Slave, com um clique.
Conclusão
Redimensionar bancos de dados PostgreSQL pode ser uma tarefa demorada. Precisamos saber o que precisamos escalar e qual é a melhor maneira de fazê-lo. Em última análise, gerenciar e dimensionar clusters manualmente torna-se bastante oneroso após um certo ponto, então a maioria recorre a ferramentas como a nossa.
Se você escolher a rota manual, verifique quando considerar adicionar um nó extra ao seu cluster. Quer evitar o incômodo? Avalie o ClusterControl gratuitamente por 30 dias para ver como seus recursos tornam o gerenciamento de código aberto em larga escala simples e eficiente.
No entanto, você deseja gerenciar e dimensionar seus bancos de dados, siga-nos no Twitter ou LinkedIn ou assine nosso boletim informativo para obter as últimas notícias e práticas recomendadas ao gerenciar a infraestrutura de banco de dados baseada em código aberto, e nos vemos em breve!