Suas escolhas de tipos de dados do servidor SQL e seus tamanhos são importantes?
A resposta está no resultado que você obteve. Seu banco de dados inchou em pouco tempo? Suas consultas estão lentas? Você teve os resultados errados? E os erros de tempo de execução durante inserções e atualizações?
Não é uma tarefa tão assustadora se você sabe o que está fazendo. Hoje, você aprenderá as 5 piores escolhas que se pode fazer com esses tipos de dados. Se eles se tornaram um hábito seu, isso é o que devemos corrigir para seu próprio bem e de seus usuários.
Muitos tipos de dados em SQL, muita confusão
Quando aprendi pela primeira vez sobre os tipos de dados do SQL Server, as opções eram esmagadoras. Todos os tipos estão misturados em minha mente como esta nuvem de palavras na Figura 1:

No entanto, podemos organizá-lo em categorias:
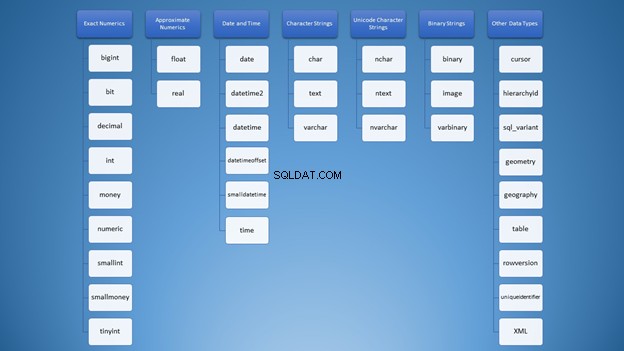
Ainda assim, para usar strings, você tem muitas opções que podem levar ao uso errado. A princípio, pensei que varchar e nvarchar eram exatamente iguais. Além disso, ambos são tipos de cadeia de caracteres. Usando números não é diferente. Como desenvolvedores, precisamos saber qual tipo usar em diferentes situações.
Mas você pode se perguntar, qual é a pior coisa que pode acontecer se eu fizer a escolha errada? Deixe-me dizer-lhe!
1. Escolhendo os tipos de dados SQL errados
Este item usará strings e números inteiros para provar o ponto.
Usando o tipo de dados SQL de string de caracteres incorreto
Primeiro, vamos voltar às cordas. Existe essa coisa chamada strings Unicode e não Unicode. Ambos têm tamanhos de armazenamento diferentes. Você costuma definir isso em colunas e declarações de variáveis.
A sintaxe é varchar (n)/caracter (n) ou nvarchar (n)/nchar (n) onde n é o tamanho.
Observe que n não é o número de caracteres, mas o número de bytes. É um equívoco comum que acontece porque, em varchar , o número de caracteres é igual ao tamanho em bytes. Mas não em nvarchar .
Para provar esse fato, vamos criar 2 tabelas e colocar alguns dados nelas.
CREATE TABLE dbo.VarcharTable
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY CLUSTERED,
someString VARCHAR(4000)
)
GO
CREATE TABLE dbo.NVarcharTable
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY CLUSTERED,
someString NVARCHAR(4000)
)
GO
INSERT INTO VarcharTable (someString)
VALUES (REPLICATE('x',4000))
GO 1000
INSERT INTO NVarcharTable (someString)
VALUES (REPLICATE(N'y',4000))
GO 1000
Agora vamos verificar seus tamanhos de linha usando DATALENGTH.
SET STATISTICS IO ON
SELECT TOP 800 *, DATALENGTH(id) + DATALENGTH(someString) AS RowSize FROM VarcharTable
SELECT TOP 800 *, DATALENGTH(id) + DATALENGTH(someString) AS RowSize FROM NVarcharTable
SET STATISTICS IO OFF
A Figura 3 mostra que a diferença é dupla. Confira abaixo.
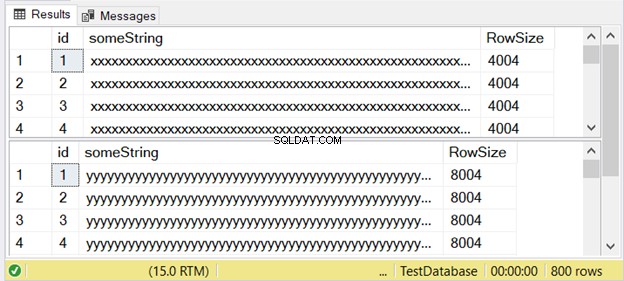
Observe o segundo conjunto de resultados com um tamanho de linha de 8004. Isso usa o nvarchar tipo de dados. Também é quase duas vezes maior que o tamanho da linha do primeiro conjunto de resultados. E isso usa o varchar tipo de dados.
Você vê a implicação no armazenamento e E/S. A Figura 4 mostra as leituras lógicas das 2 consultas.
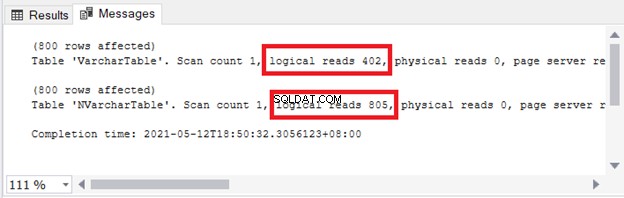
Ver? As leituras lógicas também são duplas ao usar nvarchar comparado a varchar .
Portanto, você não pode simplesmente usar cada um de forma intercambiável. Se você precisar armazenar multilíngue caracteres, use nvarchar . Caso contrário, use varchar .
Isso significa que se você usar nvarchar apenas para caracteres de byte único (como inglês), o tamanho de armazenamento é maior . O desempenho da consulta também é mais lento com leituras lógicas mais altas.
No SQL Server 2019 (e superior), você pode armazenar todo o intervalo de dados de caracteres Unicode usando varchar ou char com qualquer uma das opções de agrupamento UTF-8.
Usando o SQL de tipo de dados numérico incorreto
O mesmo conceito se aplica a bigint vs. int – seus tamanhos podem significar noite e dia. Curta nvarchar e varchar , grande é o dobro do tamanho de int (8 bytes para grande e 4 bytes para int ).
Ainda assim, outro problema é possível. Se você não se importar com os tamanhos, podem ocorrer erros. Se você usar um int coluna e armazenar um número maior que 2.147.483.647, ocorrerá um estouro aritmético:
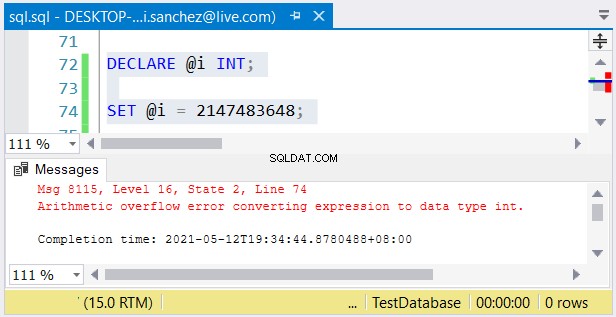
Ao escolher tipos de números inteiros, certifique-se de que os dados com o valor máximo se ajustem . Por exemplo, você pode estar projetando uma tabela com dados históricos. Você planeja usar números inteiros como o valor da chave primária. Você acha que não chegará a 2.147.483.647 linhas? Em seguida, use int em vez de grande como o tipo de coluna de chave primária.
A pior coisa que pode acontecer
Escolher os tipos de dados errados pode afetar o desempenho da consulta ou causar erros de tempo de execução. Assim, escolha o tipo de dados certo para os dados.
2. Criando grandes linhas de tabela usando tipos de Big Data para SQL
Nosso próximo item está relacionado ao primeiro, mas expandirá ainda mais o ponto com exemplos. Além disso, tem algo a ver com páginas e varchar de tamanho grande ou nvarchar colunas.
O que há com páginas e tamanhos de linha?
O conceito de páginas no SQL Server pode ser comparado com as páginas de um caderno espiral. Cada página em um caderno tem o mesmo tamanho físico. Você escreve palavras e desenha nelas. Se uma página não for suficiente para um conjunto de parágrafos e imagens, você continua na próxima página. Às vezes, você também rasga uma página e começa de novo.
Da mesma forma, dados de tabela, entradas de índice e imagens no SQL Server são armazenados em páginas.
Uma página tem o mesmo tamanho de 8 KB. Se uma linha de dados for muito grande, ela não caberá na página de 8 KB. Uma ou mais colunas serão gravadas em outra página na unidade de alocação ROW_OVERFLOW_DATA. Ele contém um ponteiro para a linha original na página na unidade de alocação IN_ROW_DATA.
Com base nisso, você não pode simplesmente encaixar muitas colunas em uma tabela durante o design do banco de dados. Haverá consequências na E/S. Além disso, se você consultar muito esses dados de estouro de linha, o tempo de execução será mais lento . Isso pode ser um pesadelo.
Um problema surge quando você maximiza todas as colunas de tamanhos variados. Em seguida, os dados passarão para a próxima página em ROW_OVERFLOW_DATA. atualize as colunas com dados de tamanho menor e ele precisa ser removido nessa página. A nova linha de dados menor será gravada na página em IN_ROW_DATA junto com as outras colunas. Imagine a E/S envolvida aqui.
Exemplo de linha grande
Vamos preparar nossos dados primeiro. Usaremos tipos de dados de cadeia de caracteres com tamanhos grandes.
CREATE TABLE [dbo].[LargeTable](
[id] [int] IDENTITY(1,1) NOT NULL,
[SomeString] [varchar](15) NOT NULL,
[LargeString] [nvarchar](3980) NOT NULL,
[AnotherString] [varchar](8000) NULL,
CONSTRAINT [PK_LargeTable] PRIMARY KEY CLUSTERED
(
[id] ASC
))
GO
INSERT INTO LargeTable
(SomeString, LargeString, AnotherString)
VALUES(REPLICATE('x',15),REPLICATE('y',500),NULL)
GO 100
INSERT INTO LargeTable
(SomeString, LargeString, AnotherString)
VALUES(REPLICATE('x',15),REPLICATE('y',3980),NULL)
GO 100
INSERT INTO LargeTable
(SomeString, LargeString, AnotherString)
VALUES(REPLICATE('x',15),REPLICATE('y',3980),REPLICATE('z',50))
GO 100
INSERT INTO LargeTable
(SomeString, LargeString, AnotherString)
VALUES(REPLICATE('x',15),REPLICATE('y',3980),REPLICATE('z',8000))
GO 100
Como obter o tamanho da linha
A partir dos dados gerados, vamos inspecionar os tamanhos das linhas com base em DATALENGTH.
SELECT *, DATALENGTH(id)
+ DATALENGTH(SomeString)
+ DATALENGTH(LargeString)
+ DATALENGTH(ISNULL(AnotherString,0)) AS RowSize
FROM LargeTable
Os primeiros 300 registros caberão nas páginas IN_ROW_DATA porque cada linha tem menos de 8060 bytes ou 8 KB. Mas as últimas 100 linhas são muito grandes. Confira o conjunto de resultados na Figura 6.
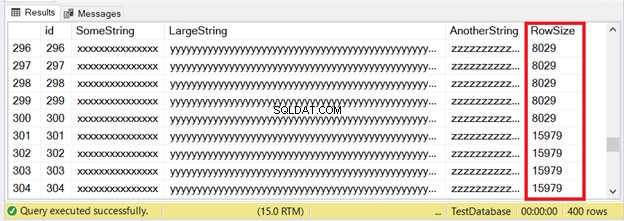
Você vê parte das primeiras 300 linhas. Os próximos 100 excedem o limite de tamanho da página. Como sabemos que as últimas 100 linhas estão na unidade de alocação ROW_OVERFLOW_DATA?
Inspecionando o ROW_OVERFLOW_DATA
Usaremos sys.dm_db_index_physical_stats . Ele retorna informações de página sobre entradas de tabela e índice.
SELECT
ps.index_id
,[Index] = i.[name]
,ps.index_type_desc
,ps.alloc_unit_type_desc
,ps.index_depth
,ps.index_level
,ps.page_count
,ps.record_count
FROM sys.dm_db_index_physical_stats(DB_ID(),
OBJECT_ID('dbo.LargeTable'), NULL, NULL, 'DETAILED') AS ps
INNER JOIN sys.indexes AS i ON ps.index_id = i.index_id
AND ps.object_id = i.object_id;
O conjunto de resultados está na Figura 7.

Aí está. A Figura 7 mostra 100 linhas em ROW_OVERFLOW_DATA. Isso é consistente com a Figura 6 quando existem grandes linhas começando com as linhas 301 a 400.
A próxima pergunta é quantas leituras lógicas obtemos quando consultamos essas 100 linhas. Vamos tentar.
SELECT * FROM LargeTable
WHERE id BETWEEN 301 AND 400
ORDER BY AnotherString DESC

Vemos 102 leituras lógicas e 100 leituras lógicas lob de LargeTable . Deixe esses números por enquanto - vamos compará-los mais tarde.
Agora, vamos ver o que acontece se atualizarmos as 100 linhas com dados menores.
UPDATE LargeTable
SET AnotherString = 'updated',LargeString='updated'
WHERE id BETWEEN 301 AND 400
Essa instrução de atualização usou as mesmas leituras lógicas e leituras lógicas de lob da Figura 8. A partir disso, sabemos que algo maior aconteceu devido às leituras lógicas de lob de 100 páginas.
Mas para ter certeza, vamos verificar com sys.dm_db_index_physical_stats como fizemos anteriormente. A Figura 9 mostra o resultado:

Se foi! As páginas e linhas de ROW_OVERFLOW_DATA tornaram-se zero após a atualização de 100 linhas com dados menores. Agora sabemos que a movimentação de dados de ROW_OVERFLOW_DATA para IN_ROW_DATA acontece quando linhas grandes são reduzidas. Imagine se isso acontecer muito para milhares ou até milhões de registros. Louco, não é?
Na Figura 8, vimos leituras lógicas de 100 lob. Agora, veja a Figura 10 depois de executar novamente a consulta:

Ficou zero!
A pior coisa que pode acontecer
O desempenho de consulta lento é o subproduto dos dados de estouro de linha. Considere mover a(s) coluna(s) de tamanho grande para outra tabela para evitá-la. Ou, se aplicável, reduza o tamanho do varchar ou nvarchar coluna.
3. Usando cegamente a conversão implícita
SQL não nos permite usar dados sem especificar o tipo. Mas é perdoar se fizermos uma escolha errada. Ele tenta converter o valor para o tipo esperado, mas com uma penalidade. Isso pode acontecer em uma cláusula WHERE ou JOIN.
USE AdventureWorks2017
GO
SET STATISTICS IO ON
SELECT
CardNumber
,CardType
,ExpMonth
,ExpYear
FROM Sales.CreditCard
WHERE CardNumber = 77775294979396 -- this will trigger an implicit conversion
SELECT
CardNumber
,CardType
,ExpMonth
,ExpYear
FROM Sales.CreditCard
WHERE CardNumber = '77775294979396'
SET STATISTICS IO OFF
O Número do Cartão coluna não é um tipo numérico. É nvarchar . Assim, o primeiro SELECT causará uma conversão implícita. No entanto, ambos funcionarão bem e produzirão o mesmo conjunto de resultados.
Vamos verificar o plano de execução na Figura 11.
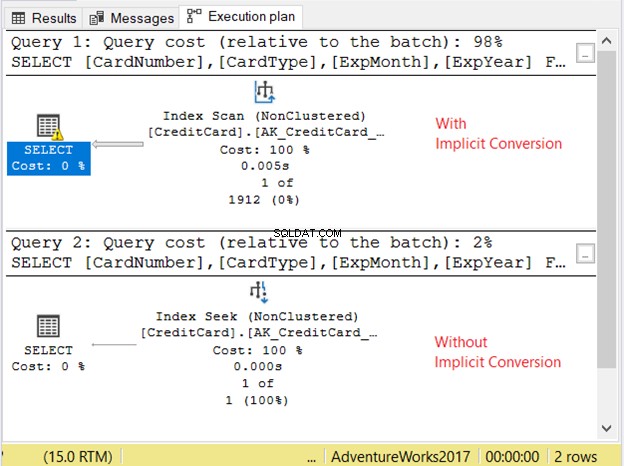
As 2 consultas foram executadas muito rapidamente. Na Figura 11, são zero segundos. Mas olhe para os 2 planos. Aquele com conversão implícita teve uma varredura de índice. Há também um ícone de aviso e uma seta gorda apontando para o operador SELECT. Nos diz que é ruim.
Mas não termina aí. Se você passar o mouse sobre o operador SELECT, verá outra coisa:

O ícone de aviso no operador SELECT é sobre a conversão implícita. Mas quão grande é o impacto? Vamos verificar as leituras lógicas.
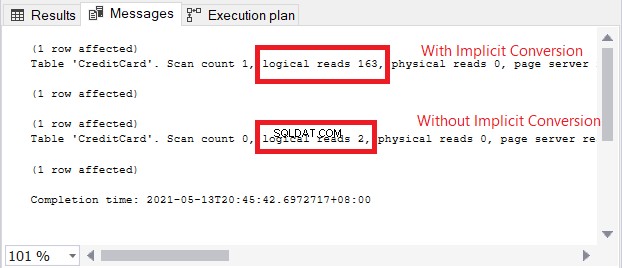
A comparação de leituras lógicas na Figura 13 é como o céu e a terra. Na consulta de informações de cartão de crédito, a conversão implícita causou mais de cem vezes as leituras lógicas. Muito mal!
A pior coisa que pode acontecer
Se uma conversão implícita causou leituras lógicas altas e um plano incorreto, espere um desempenho de consulta lento em grandes conjuntos de resultados. Para evitar isso, use o tipo de dados exato na cláusula WHERE e JOINs na correspondência das colunas que você compara.
4. Usando números aproximados e arredondando
Confira a figura 2 novamente. Os tipos de dados do servidor SQL pertencentes a números aproximados são float e real . Colunas e variáveis feitas delas armazenam uma grande aproximação de um valor numérico. Se você planeja arredondar esses números para cima ou para baixo, poderá ter uma grande surpresa. Eu tenho um artigo que discutiu isso em detalhes aqui. Veja como 1 + 1 resulta em 3 e como você pode lidar com o arredondamento dos números.
A pior coisa que pode acontecer
Arredondando um float ou real pode ter resultados loucos. Se você quiser valores exatos após o arredondamento, use decimal ou numérico em vez de.
5. Definindo tipos de dados de string de tamanho fixo como NULL
Vamos voltar nossa atenção para tipos de dados de tamanho fixo como char e nchar . Além dos espaços preenchidos, defini-los como NULL ainda terá um tamanho de armazenamento igual ao tamanho do char coluna. Então, definindo um char (500) para NULL terá um tamanho de 500, não zero ou 1.
CREATE TABLE dbo.CharNullSample
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY,
col1 CHAR(500) NULL,
col2 CHAR(200) NULL,
col3 CHAR(350) NULL,
col4 VARCHAR(500) NULL,
col5 VARCHAR(200) NULL,
col6 VARCHAR(350) NULL
)
GO
INSERT INTO CharNullSample (col1, col2, col3, col4, col5, col6)
VALUES (REPLICATE('x',500), REPLICATE('y',200), REPLICATE('z',350), REPLICATE('x',500), REPLICATE('y',200), REPLICATE('z',350));
GO 200
No código acima, os dados são maximizados com base no tamanho de char e varchar colunas. Verificar o tamanho da linha usando DATALENGTH também mostrará a soma dos tamanhos de cada coluna. Agora vamos definir as colunas para NULL.
UPDATE CharNullSample
SET col1 = NULL, col2=NULL, col3=NULL, col4=NULL, col5=NULL, col6=NULL
Em seguida, consultamos as linhas usando DATALENGTH:
SELECT
DATALENGTH(ISNULL(col1,0)) AS Col1Size
,DATALENGTH(ISNULL(col2,0)) AS Col2Size
,DATALENGTH(ISNULL(col3,0)) AS Col3Size
,DATALENGTH(ISNULL(col4,0)) AS Col4Size
,DATALENGTH(ISNULL(col5,0)) AS Col5Size
,DATALENGTH(ISNULL(col6,0)) AS Col6Size
FROM CharNullSample
Quais você acha que serão os tamanhos de dados de cada coluna? Confira a Figura 14.
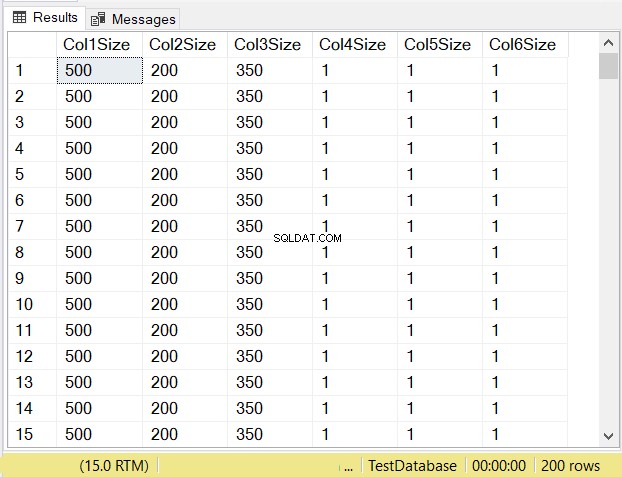
Observe os tamanhos das colunas das 3 primeiras colunas. Em seguida, compare-os com o código acima quando a tabela foi criada. O tamanho dos dados das colunas NULL é igual ao tamanho da coluna. Enquanto isso, o varchar colunas quando NULL tem um tamanho de dados de 1.
A pior coisa que pode acontecer
Durante a criação de tabelas, char anulável colunas, quando definidas como NULL, ainda terão o mesmo tamanho de armazenamento. Eles também consumirão as mesmas páginas e RAM. Se você não preencher a coluna inteira com caracteres, considere usar varchar em vez de.
O que vem a seguir?
Então, suas escolhas nos tipos de dados do SQL Server e seus tamanhos são importantes? Os pontos apresentados aqui devem ser suficientes para fazer um ponto. Então, o que você pode fazer agora?
- Aproveite para revisar o banco de dados que você suporta. Comece com o mais fácil se você tiver vários no seu prato. E sim, ganhe tempo, não encontre tempo. Em nossa linha de trabalho, é quase impossível encontrar tempo.
- Revise as tabelas, procedimentos armazenados e qualquer coisa que lide com tipos de dados. Observe o impacto positivo ao identificar problemas. Você vai precisar dele quando seu chefe perguntar por que você precisa trabalhar nisso.
- Planeje atacar cada uma das áreas problemáticas. Siga quaisquer metodologias ou políticas que sua empresa tenha para lidar com os problemas.
- Quando os problemas acabarem, comemore.
Parece fácil, mas todos sabemos que não é. Também sabemos que há um lado positivo no final da jornada. É por isso que eles são chamados de problemas – porque há uma solução. Então, anime-se.
Você tem algo mais a acrescentar sobre este tópico? Deixe-nos saber na seção de comentários. E se este post lhe deu uma ideia brilhante, compartilhe-o em suas plataformas de mídia social favoritas.