Observação:esta postagem foi publicada originalmente apenas em nosso eBook, Técnicas de alto desempenho para SQL Server, Volume 2. Você pode descobrir mais sobre nossos eBooks aqui.
Resumo:Este artigo examina alguns comportamentos surpreendentes dos gatilhos INSTEAD OF e revela um sério bug de estimativa de cardinalidade no SQL Server 2014.
Triggers e controle de versão de linha
Somente os gatilhos DML AFTER usam controle de versão de linha (no SQL Server 2005 em diante) para fornecer o inserido e excluído pseudo-tabelas dentro de um procedimento de gatilho. Este ponto não é claramente feito em grande parte da documentação oficial. Na maioria dos lugares, a documentação simplesmente diz que o versionamento de linha é usado para construir o arquivo inserido e excluído tabelas em triggers sem qualificação (exemplos abaixo):
Uso de recursos de controle de versão de linha
Compreendendo os níveis de isolamento baseados em controle de versão de linha
Controlando a execução do acionador ao importar dados em massa
Presumivelmente, as versões originais dessas entradas foram escritas antes que os gatilhos INSTEAD OF fossem adicionados ao produto e nunca atualizados. Ou isso, ou é um simples (mas repetido) descuido.
De qualquer forma, a maneira como o versionamento de linha funciona com os gatilhos AFTER é bastante intuitivo. Esses acionadores são disparados depois as modificações em questão foram executadas, então é fácil ver como manter as versões das linhas modificadas permite que o mecanismo de banco de dados forneça o inserido e excluído pseudo-tabelas. O excluído pseudo-tabela é construída a partir de versões das linhas afetadas antes das modificações ocorrerem; o inserido pseudo-tabela é formada a partir das versões das linhas afetadas no momento em que o procedimento de disparo foi iniciado.
Em vez de gatilhos
Os gatilhos INSTEAD OF são diferentes porque esse tipo de gatilho DML substitui completamente a ação desencadeada. O inserido e excluído pseudo-tabelas agora representam mudanças que teriam foi feito, teve a instrução de disparo realmente executada. O controle de versão de linha não pode ser usado para esses gatilhos porque nenhuma modificação ocorreu, por definição. Então, se não estiver usando versões de linha, como o SQL Server faz isso?
A resposta é que o SQL Server modifica o plano de execução para a instrução DML de acionamento quando existe um gatilho INSTEAD OF. Em vez de modificar as tabelas afetadas diretamente, o plano de execução grava informações sobre as alterações em uma tabela de trabalho oculta. Esta tabela de trabalho contém todos os dados necessários para realizar as alterações originais, o tipo de modificação a ser executada em cada linha (excluir ou inserir), bem como qualquer informação necessária no gatilho para uma cláusula OUTPUT.
Plano de execução sem gatilho
Para ver tudo isso em ação, primeiro executaremos um teste simples sem um gatilho INSTEAD OF presente:
CREATE TABLE Test
(
RowID integer NOT NULL,
Data integer NOT NULL,
CONSTRAINT PK_Test_RowID
PRIMARY KEY CLUSTERED (RowID)
);
GO
INSERT dbo.Test
(RowID, Data)
VALUES
(1, 100),
(2, 200),
(3, 300);
GO
DELETE dbo.Test;
GO
DROP TABLE dbo.Test; O plano de execução para a exclusão é muito simples:
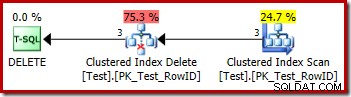
Cada linha qualificada é passada diretamente para um operador Clustered Index Delete, que a exclui. Fácil.
Plano de execução com um gatilho INSTEAD OF
Agora vamos modificar o teste para incluir um gatilho INSTEAD OF DELETE (um que apenas executa a mesma ação de exclusão para simplificar):
CREATE TABLE Test
(
RowID integer NOT NULL,
Data integer NOT NULL,
CONSTRAINT PK_Test_RowID
PRIMARY KEY CLUSTERED (RowID)
);
GO
INSERT dbo.Test
(RowID, Data)
VALUES
(1, 100),
(2, 200),
(3, 300);
GO
CREATE TRIGGER dbo_Test_IOD
ON dbo.Test
INSTEAD OF DELETE
AS
BEGIN
SET NOCOUNT ON;
DELETE FROM dbo.Test
WHERE EXISTS
(
SELECT * FROM Deleted
WHERE Deleted.RowID = dbo.Test.RowID
);
END;
GO
DELETE dbo.Test;
GO
DROP TABLE dbo.Test; O plano de execução do DELETE agora é bem diferente:
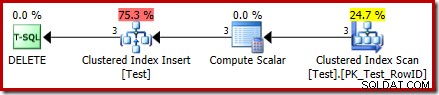
O operador Clustered Index Delete foi substituído por um Clustered Index Insert . Esta é a inserção na tabela de trabalho oculta, que é renomeada (na representação do plano de execução pública) para o nome da tabela base afetada pela exclusão. A renomeação ocorre quando o plano de exibição XML é gerado a partir da representação do plano de execução interno, portanto, não há uma maneira documentada de ver a tabela de trabalho oculta.
Como resultado dessa alteração, o plano parece executar uma inserir para a tabela base para excluir fileiras dele. Isso é confuso, mas pelo menos revela a presença de um gatilho INSTEAD OF. Substituir o operador Insert por um Delete pode ser ainda mais confuso. Talvez o ideal seria um novo ícone gráfico para uma mesa de trabalho INSTEAD OF trigger? De qualquer forma, é o que é.
O novo operador Compute Scalar define o tipo de ação executada em cada linha. Este código de ação é um número inteiro, com os seguintes significados:
- 3 =EXCLUIR
- 4 =INSERIR
- 259 =EXCLUIR em um plano MERGE
- 260 =INSERIR em um plano MERGE
Para esta consulta, a ação é uma constante 3, o que significa que cada linha deve ser excluída :
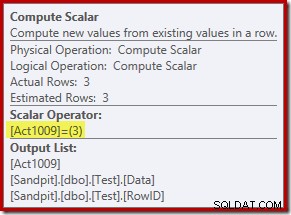
Atualizar ações
Como um aparte, um plano de execução INSTEAD OF UPDATE substitui um único operador Update por dois Inserções de índice clusterizado para a mesma tabela de trabalho oculta – uma para o inserido linhas de pseudo-tabela e uma para as excluídas linhas de pseudo-tabela. Um exemplo de plano de execução:

Um MERGE que executa um UPDATE também produz um plano de execução com duas inserções na mesma tabela base por motivos semelhantes:

O Plano de Execução do Acionador
O plano de execução do corpo do gatilho também possui alguns recursos interessantes:
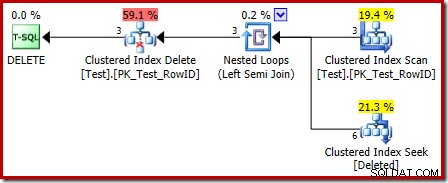
A primeira coisa a notar é que o ícone gráfico usado para a tabela excluída não é o mesmo que o ícone usado nos planos de gatilho AFTER:
A representação no plano de gatilho INSTEAD OF é uma Busca de Índice Agrupado. O objeto subjacente é a mesma tabela de trabalho interna que vimos anteriormente, embora aqui seja chamado de excluído em vez de receber o nome da tabela base, presumivelmente para algum tipo de consistência com os gatilhos AFTER.
A operação de busca no excluído table pode não ser o que você esperava (se você esperava uma busca no RowID):
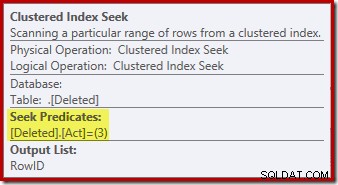
Este 'seek' retorna todas as linhas da tabela de trabalho que possuem um código de ação de 3 (excluir), tornando-o exatamente equivalente ao Digitalização excluída operador visto nos planos de gatilho AFTER. A mesma tabela de trabalho interna é usada para armazenar linhas para inseridos e excluído pseudo-tabelas em gatilhos INSTEAD OF. O equivalente a uma varredura inserida é uma busca no código de ação 4 (que é possível em um excluir trigger, mas o resultado sempre estará vazio). Não há índices na tabela de trabalho interna além do índice clusterizado não exclusivo na ação coluna sozinha. Além disso, não há estatísticas associadas a esse índice interno.
A análise até agora pode deixar você imaginando onde a junção entre as colunas RowID é executada. Essa comparação ocorre no operador Nested Loops Left Semi Join como um predicado residual:
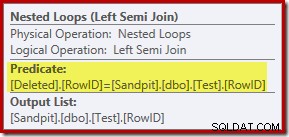
Agora que sabemos que 'procurar' é efetivamente uma verificação completa dos arquivos excluídos tabela, o plano de execução escolhido pelo otimizador de consulta parece bastante ineficiente. O fluxo geral do plano de execução é que cada linha da tabela de teste é potencialmente comparada com todo o conjunto de excluídos linhas, que soa muito como um produto cartesiano.
A graça salvadora é que a junção é uma semijunção, o que significa que o processo de comparação é interrompido para uma determinada linha de teste assim que a primeira excluída linha satisfaz o predicado residual. No entanto, a estratégia parece curiosa. Talvez o plano de execução fosse melhor se a tabela Test contivesse mais linhas?
Teste de gatilho com 1.000 linhas
O script a seguir pode ser usado para testar o gatilho com um número maior de linhas. Começaremos com 1.000:
CREATE TABLE Test
(
RowID integer NOT NULL,
Data integer NOT NULL,
CONSTRAINT PK_Test_RowID
PRIMARY KEY CLUSTERED (RowID)
);
GO
SET STATISTICS XML OFF;
SET NOCOUNT ON;
GO
DECLARE @i integer = 1;
WHILE @i <= 1000
BEGIN
INSERT dbo.Test (RowID, Data)
VALUES (@i, @i * 100);
SET @i += 1;
END;
GO
CREATE TRIGGER dbo_Test_IOD
ON dbo.Test
INSTEAD OF DELETE
AS
BEGIN
SET NOCOUNT ON;
DELETE FROM dbo.Test
WHERE EXISTS
(
SELECT * FROM Deleted
WHERE Deleted.RowID = dbo.Test.RowID
);
END;
GO
SET STATISTICS XML ON;
GO
DELETE dbo.Test;
GO
DROP TABLE dbo.Test; O plano de execução para o corpo do gatilho agora é:
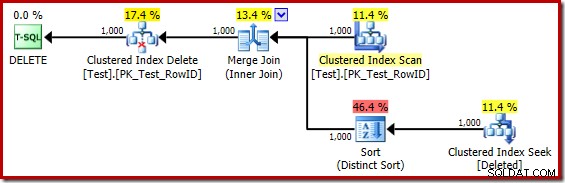
Substituindo mentalmente o (enganoso) Clustered Index Seek por um Deleted Scan, o plano geralmente parece muito bom. O otimizador escolheu um Merge Join de um para muitos em vez de um Nested Loops Semi Join, o que parece razoável. O Distinct Sort é uma adição curiosa:
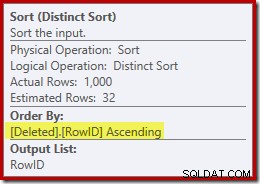
Este tipo está executando duas funções. Primeiro, está fornecendo a junção de mesclagem com a entrada classificada de que precisa, o que é justo o suficiente porque não há índice na tabela de trabalho interna para fornecer a ordem necessária. A segunda coisa que a classificação está fazendo é distinguir em RowID. Isso pode parecer estranho, porque RowID é a chave primária da tabela base.
O problema é que as linhas no excluído table são simplesmente linhas candidatas que a consulta DELETE original identificou. Ao contrário de um gatilho AFTER, essas linhas ainda não foram verificadas quanto a restrições ou violações de chave, portanto, o processador de consulta não tem garantia de que elas sejam de fato exclusivas.
Geralmente, este é um ponto muito importante a ter em mente com os gatilhos INSTEAD OF:não há garantia de que as linhas fornecidas atendam a qualquer uma das restrições na tabela base (incluindo NOT NULL). Isso não é importante apenas para o autor do gatilho lembrar; também limita as simplificações e transformações que o otimizador de consulta pode realizar.
Um segundo problema mostrado nas propriedades de classificação acima, mas não destacado, é que a estimativa de saída é de apenas 32 linhas. A tabela de trabalho interna não tem estatísticas associadas a ela, então o otimizador supõe no efeito da operação Distinct. Nós 'sabemos' que os valores RowID são únicos, mas sem nenhuma informação concreta para continuar, o otimizador faz uma estimativa ruim. Esse problema voltará a nos assombrar no próximo teste.
Teste de gatilho com 5.000 linhas
Agora modifique o script de teste para gerar 5.000 linhas:
CREATE TABLE Test
(
RowID integer NOT NULL,
Data integer NOT NULL,
CONSTRAINT PK_Test_RowID
PRIMARY KEY CLUSTERED (RowID)
);
GO
SET STATISTICS XML OFF;
SET NOCOUNT ON;
GO
DECLARE @i integer = 1;
WHILE @i <= 5000
BEGIN
INSERT dbo.Test (RowID, Data)
VALUES (@i, @i * 100);
SET @i += 1;
END;
GO
CREATE TRIGGER dbo_Test_IOD
ON dbo.Test
INSTEAD OF DELETE
AS
BEGIN
SET NOCOUNT ON;
DELETE FROM dbo.Test
WHERE EXISTS
(
SELECT * FROM Deleted
WHERE Deleted.RowID = dbo.Test.RowID
);
END;
GO
SET STATISTICS XML ON;
GO
DELETE dbo.Test;
GO
DROP TABLE dbo.Test; O plano de execução do gatilho é:
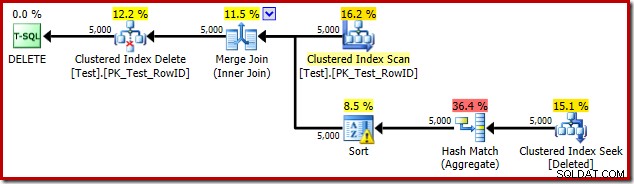
Desta vez, o otimizador decidiu dividir as operações distintas e de classificação. A distinção em RowID é realizada pelo operador Hash Match (Aggregate):
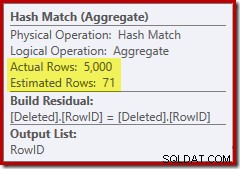
Observe que a estimativa do otimizador para a saída é de 71 linhas. Na verdade, todas as 5.000 linhas sobrevivem ao distinto porque RowID é exclusivo. A estimativa imprecisa significa que uma fração inadequada da concessão de memória de consulta é alocada para o Sort, que acaba sendo derramado para tempdb :
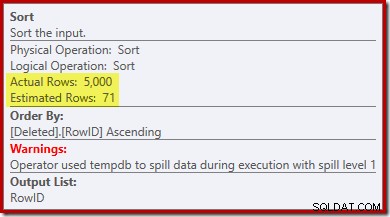
Este teste deve ser executado no SQL Server 2012 ou superior para ver o aviso de classificação no plano de execução. Em versões anteriores, o plano não contém informações sobre spills – um rastreamento do Profiler no evento Sort Warnings seria necessário para revelá-lo (e você precisaria correlacionar isso de volta à consulta de origem de alguma forma).
Teste de gatilho com 5.000 linhas no SQL Server 2014
Se o teste anterior for repetido no SQL Server 2014, em um banco de dados definido com nível de compatibilidade 120 para que o novo estimador de cardinalidade (CE) seja usado, o plano de execução do gatilho será diferente novamente:
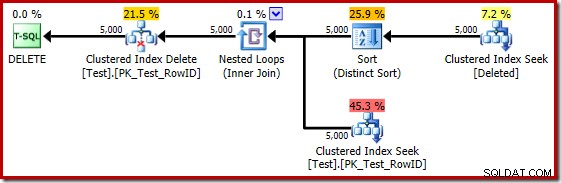
De certa forma, esse plano de execução parece uma melhoria. O (desnecessário) Distinct Sort ainda está lá, mas a estratégia geral parece mais natural:para cada RowID candidato distinto no excluído table, junte-se à tabela base (para verificar se a linha candidata realmente existe) e exclua-a.
Infelizmente, o plano de 2014 é baseado em estimativas de cardinalidade piores do que vimos no SQL Server 2012. Alternando o SQL Sentry Plan Explorer para exibir o estimado a contagem de linhas mostra o problema claramente:
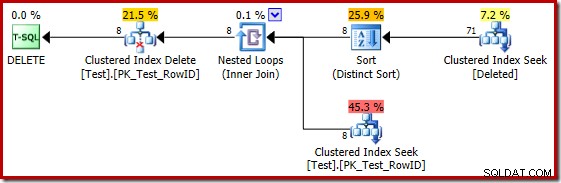
O otimizador escolheu uma estratégia de loops aninhados para a junção porque esperava um número muito pequeno de linhas em sua entrada superior. O primeiro problema ocorre no Clustered Index Seek. O otimizador sabe que a tabela excluída contém 5.000 linhas neste ponto, como podemos ver alternando para a visualização Plan Tree e adicionando a coluna opcional Table Cardinality (que eu gostaria que fosse incluída por padrão):
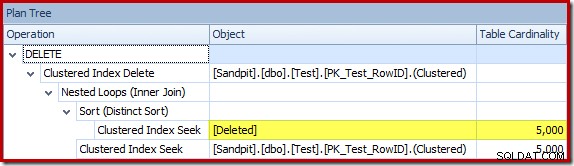
O estimador de cardinalidade 'antigo' no SQL Server 2012 e anteriores é inteligente o suficiente para saber que a 'busca' na tabela de trabalho interna retornaria todas as 5.000 linhas (portanto, ele escolheu uma junção de mesclagem). O novo CE não é tão inteligente. Ele vê a tabela de trabalho como uma 'caixa preta' e adivinha o efeito da busca no código de ação =3:
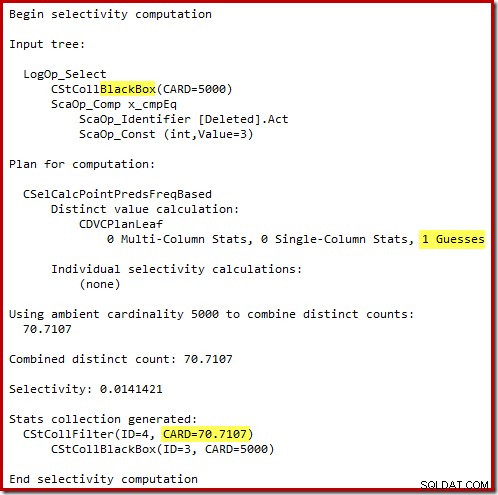
A estimativa de 71 linhas (arredondadas para cima) é um resultado bastante infeliz, mas o erro é agravado quando o novo CE estima as linhas para a operação distinta nessas 71 linhas:
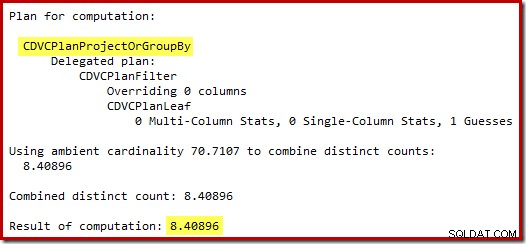
Com base nas 8 linhas esperadas, o otimizador escolhe a estratégia Nested Loops. Outra maneira de ver esses erros de estimativa é adicionar a seguinte instrução ao corpo do acionador (somente para fins de teste):
SELECT COUNT_BIG(DISTINCT RowID) FROM Deleted;
O plano estimado mostra claramente os erros de estimativa:
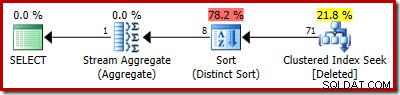
O plano real ainda mostra 5.000 linhas, é claro:
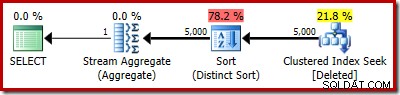
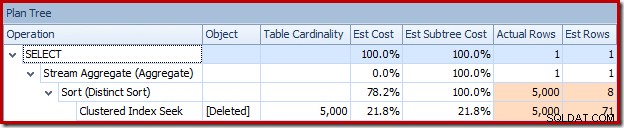
Ou você pode comparar a estimativa versus a real ao mesmo tempo na visualização em árvore de planta:
Um milhão de linhas…
As estimativas insatisfatórias ao usar o estimador de cardinalidade de 2014 fazem com que o otimizador selecione uma estratégia de loops aninhados mesmo quando a tabela de teste contém um milhão de linhas. O novo CE de 2014 estimado plano para esse teste é:
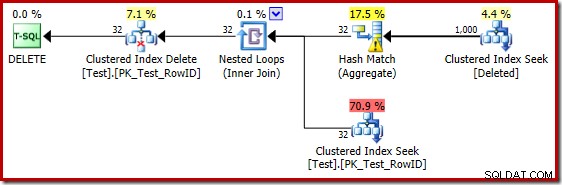
A 'busca' estima 1.000 linhas da cardinalidade conhecida de 1.000.000 e a estimativa distinta é de 32 linhas. O plano pós-execução revela o efeito na memória reservada para o Hash Match:
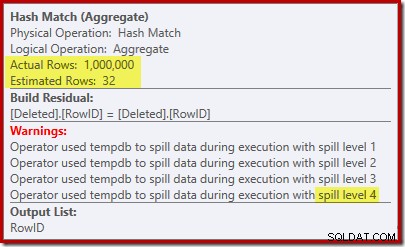
Esperando apenas 32 linhas, o Hash Match entra em problemas reais, derramando recursivamente sua tabela de hash antes de ser concluído.
Considerações finais
Embora seja verdade que um gatilho nunca deve ser escrito para fazer algo que possa ser alcançado com integridade referencial declarativa, também é verdade que um bem escrito gatilho que usa um eficiente plano de execução pode ser comparável em desempenho ao custo de manutenção de um índice extra não clusterizado.
Há dois problemas práticos com a afirmação acima. Primeiro (e com a melhor vontade do mundo) as pessoas nem sempre escrevem um bom código de gatilho. Segundo, obter um bom plano de execução do otimizador de consulta em todas as circunstâncias pode ser difícil. A natureza dos gatilhos é que eles são chamados com uma ampla variedade de cardinalidades de entrada e distribuições de dados.
Mesmo para gatilhos AFTER, a falta de índices e estatísticas sobre os excluídos e inserido pseudo-tabelas significa que a seleção de planos geralmente é baseada em suposições ou desinformação. Mesmo quando um bom plano é selecionado inicialmente, execuções posteriores podem reutilizar o mesmo plano quando uma recompilação teria sido uma escolha melhor. Existem maneiras de contornar as limitações, principalmente por meio do uso de tabelas temporárias e índices/estatísticas explícitas, mas mesmo assim é necessário muito cuidado (já que os gatilhos são uma forma de procedimento armazenado).
Com gatilhos INSTEAD OF, os riscos podem ser ainda maiores porque o conteúdo do inserido e excluído as tabelas são candidatas não verificadas – o otimizador de consulta não pode usar restrições na tabela base para simplificar e refinar seu plano de execução. O novo estimador de cardinalidade no SQL Server 2014 também representa um verdadeiro retrocesso quando se trata de planos de gatilho INSTEAD OF. Adivinhar o efeito de uma operação de busca que o motor se introduziu é um descuido surpreendente e indesejável.