Historicamente, a tarefa mais difícil ao trabalhar com o PostgreSQL é lidar com as atualizações. A maneira de atualização mais intuitiva que você pode imaginar é gerar uma réplica em uma nova versão e realizar um failover do aplicativo nela. Com o PostgreSQL, isso simplesmente não era possível de forma nativa. Para realizar atualizações, você precisava pensar em outras maneiras de atualizar, como usar pg_upgrade, despejar e restaurar, ou usar algumas ferramentas de terceiros como Slony ou Bucardo, todas elas com suas próprias ressalvas.
Por que foi isso? Por causa da maneira como o PostgreSQL implementa a replicação.
A replicação de streaming integrada do PostgreSQL é o que chamamos de física:ela replicará as alterações em nível de byte a byte, criando uma cópia idêntica do banco de dados em outro servidor. Esse método tem muitas limitações quando se pensa em um upgrade, pois você simplesmente não pode criar uma réplica em uma versão de servidor diferente ou mesmo em uma arquitetura diferente.
Então, aqui é onde o PostgreSQL 10 se torna um divisor de águas. Com essas novas versões 10 e 11, o PostgreSQL implementa a replicação lógica integrada que, em contraste com a replicação física, você pode replicar entre as diferentes versões principais do PostgreSQL. Isso, é claro, abre uma nova porta para estratégias de atualização.
Neste blog, vamos ver como podemos atualizar nosso PostgreSQL 10 para PostgreSQL 11 com tempo de inatividade zero usando replicação lógica. Em primeiro lugar, vamos passar por uma introdução à replicação lógica.
O que é replicação lógica?
A replicação lógica é um método de replicação de objetos de dados e suas alterações, com base em sua identidade de replicação (geralmente uma chave primária). É baseado em um modo de publicação e assinatura, onde um ou mais assinantes assinam uma ou mais publicações em um nó publicador.
Uma publicação é um conjunto de alterações geradas a partir de uma tabela ou de um grupo de tabelas (também conhecido como conjunto de replicação). O nó onde uma publicação é definida é referido como publicador. Uma assinatura é o lado downstream da replicação lógica. O nó onde uma assinatura é definida é chamado de assinante e define a conexão com outro banco de dados e conjunto de publicações (uma ou mais) que deseja assinar. Os assinantes extraem dados das publicações que assinam.
A replicação lógica é construída com uma arquitetura semelhante à replicação de streaming físico. É implementado pelos processos "walsender" e "apply". O processo walsender inicia a decodificação lógica do WAL e carrega o plug-in de decodificação lógica padrão. O plugin transforma as alterações lidas do WAL para o protocolo de replicação lógica e filtra os dados de acordo com a especificação da publicação. Os dados são então transferidos continuamente usando o protocolo de replicação de streaming para o operador de aplicação, que mapeia os dados para tabelas locais e aplica as alterações individuais à medida que são recebidas, em uma ordem transacional correta.
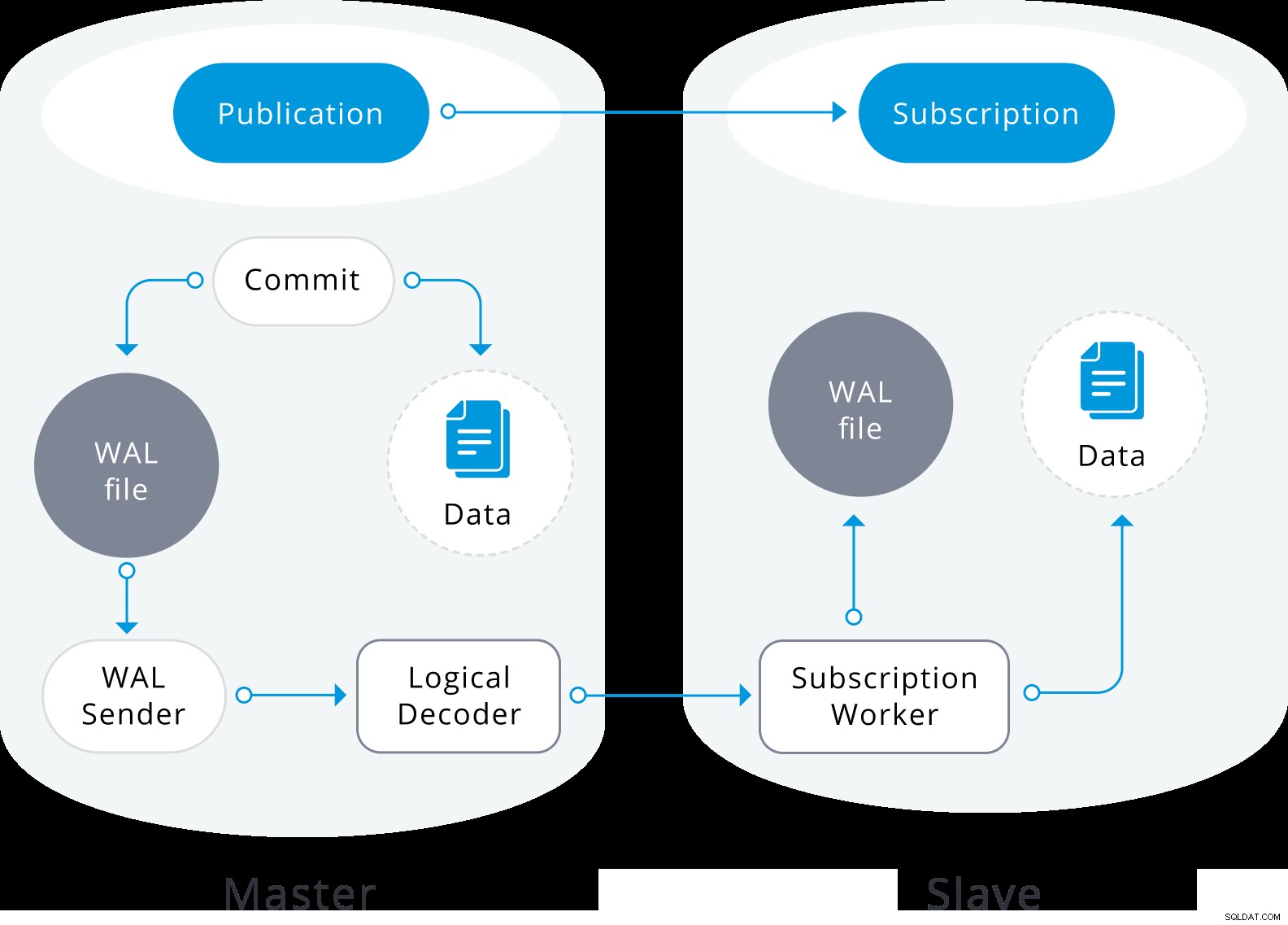 Diagrama de replicação lógica
Diagrama de replicação lógica A replicação lógica começa tirando um instantâneo dos dados no banco de dados do editor e copiando-o para o assinante. Os dados iniciais nas tabelas assinadas existentes são instantâneos e copiados em uma instância paralela de um tipo especial de processo de aplicação. Esse processo criará seu próprio slot de replicação temporário e copiará os dados existentes. Depois que os dados existentes são copiados, o trabalhador entra no modo de sincronização, o que garante que a tabela seja colocada em um estado sincronizado com o processo de aplicação principal, transmitindo todas as alterações ocorridas durante a cópia de dados inicial usando a replicação lógica padrão. Uma vez que a sincronização é feita, o controle da replicação da tabela é devolvido ao processo de aplicação principal onde a replicação continua normalmente. As alterações no editor são enviadas ao assinante à medida que ocorrem em tempo real.
Você pode encontrar mais sobre replicação lógica nos seguintes blogs:
- Uma visão geral da replicação lógica no PostgreSQL
- Replicação de streaming do PostgreSQL versus replicação lógica
Como atualizar o PostgreSQL 10 para o PostgreSQL 11 usando replicação lógica
Então, agora que sabemos do que se trata esse novo recurso, podemos pensar em como podemos usá-lo para resolver o problema de atualização.
Vamos configurar a replicação lógica entre duas versões principais diferentes do PostgreSQL (10 e 11) e, claro, depois de ter tudo funcionando, é apenas uma questão de executar um failover de aplicativo no banco de dados com a versão mais recente.
Vamos executar as seguintes etapas para colocar a replicação lógica para funcionar:
- Configure o nó do editor
- Configure o nó do assinante
- Criar o usuário assinante
- Criar uma publicação
- Crie a estrutura da tabela no assinante
- Criar a assinatura
- Verifique o status da replicação
Então vamos começar.
No lado do publicador, vamos configurar os seguintes parâmetros no arquivo postgresql.conf:
- listen_addresses:em quais endereços IP escutar. Usaremos '*' para todos.
- wal_level:determina a quantidade de informações gravadas no WAL. Vamos defini-lo como lógico.
- max_replication_slots:especifica o número máximo de slots de replicação que o servidor pode suportar. Ele deve ser definido para pelo menos o número de assinaturas esperadas para conexão, além de alguma reserva para sincronização de tabela.
- max_wal_senders:Especifica o número máximo de conexões simultâneas de servidores em espera ou clientes de backup de base de streaming. Ele deve ser definido como pelo menos o mesmo que max_replication_slots mais o número de réplicas físicas conectadas ao mesmo tempo.
Lembre-se de que alguns desses parâmetros exigiram a reinicialização do serviço PostgreSQL para serem aplicados.
O arquivo pg_hba.conf também precisa ser ajustado para permitir a replicação. Precisamos permitir que o usuário de replicação se conecte ao banco de dados.
Então, com base nisso, vamos configurar nosso editor (neste caso nosso servidor PostgreSQL 10) da seguinte forma:
- postgresql.conf:
listen_addresses = '*' wal_level = logical max_wal_senders = 8 max_replication_slots = 4 - pg_hba.conf:
# TYPE DATABASE USER ADDRESS METHOD host all rep 192.168.100.144/32 md5
Devemos alterar o usuário (no nosso exemplo rep), que será usado para replicação, e o endereço IP 192.168.100.144/32 para o IP que corresponde ao nosso PostgreSQL 11.
No lado do assinante, também requer que max_replication_slots seja definido. Nesse caso, deve ser definido pelo menos o número de assinaturas que serão adicionadas ao assinante.
Os outros parâmetros que também precisam ser definidos aqui são:
- max_logical_replication_workers:especifica o número máximo de trabalhadores de replicação lógica. Isso inclui os trabalhadores de aplicação e de sincronização de tabela. Os trabalhadores de replicação lógica são obtidos do pool definido por max_worker_processes. Ele deve ser definido para pelo menos o número de assinaturas, novamente mais alguma reserva para a sincronização da tabela.
- max_worker_processes:define o número máximo de processos em segundo plano que o sistema pode suportar. Ele pode precisar ser ajustado para acomodar trabalhadores de replicação, pelo menos max_logical_replication_workers + 1. Este parâmetro requer uma reinicialização do PostgreSQL.
Portanto, devemos configurar nosso assinante (neste caso nosso servidor PostgreSQL 11) da seguinte forma:
- postgresql.conf:
listen_addresses = '*' max_replication_slots = 4 max_logical_replication_workers = 4 max_worker_processes = 8
Como este PostgreSQL 11 será nosso novo mestre em breve, devemos considerar adicionar os parâmetros wal_level e archive_mode nesta etapa, para evitar uma nova reinicialização do serviço posteriormente.
wal_level = logical
archive_mode = onEsses parâmetros serão úteis se quisermos adicionar um novo escravo de replicação ou para usar backups PITR.
No editor, devemos criar o usuário com o qual nosso assinante se conectará:
world=# CREATE ROLE rep WITH LOGIN PASSWORD '*****' REPLICATION;
CREATE ROLEA função usada para a conexão de replicação deve ter o atributo REPLICATION. O acesso para a função deve ser configurado em pg_hba.conf e deve ter o atributo LOGIN.
Para poder copiar os dados iniciais, a função usada para a conexão de replicação deve ter o privilégio SELECT em uma tabela publicada.
world=# GRANT SELECT ON ALL TABLES IN SCHEMA public to rep;
GRANTCriaremos a publicação pub1 no nó do editor, para todas as tabelas:
world=# CREATE PUBLICATION pub1 FOR ALL TABLES;
CREATE PUBLICATIONO usuário que irá criar uma publicação deve ter o privilégio CREATE no banco de dados, mas para criar uma publicação que publique todas as tabelas automaticamente, o usuário deve ser um superusuário.
Para confirmar a publicação criada vamos utilizar o catálogo pg_publication. Este catálogo contém informações sobre todas as publicações criadas no banco de dados.
world=# SELECT * FROM pg_publication;
-[ RECORD 1 ]+------
pubname | pub1
pubowner | 16384
puballtables | t
pubinsert | t
pubupdate | t
pubdelete | tDescrições das colunas:
- pubname:nome da publicação.
- pubowner:proprietário da publicação.
- pubballtables:se verdadeiro, esta publicação inclui automaticamente todas as tabelas do banco de dados, incluindo as que serão criadas no futuro.
- pubinsert:se true, as operações INSERT são replicadas para tabelas na publicação.
- pubupdate:se true, as operações UPDATE são replicadas para as tabelas na publicação.
- pubdelete:se true, as operações DELETE são replicadas para tabelas na publicação.
Como o esquema não é replicado, devemos fazer um backup no PostgreSQL 10 e restaurá-lo em nosso PostgreSQL 11. O backup será feito apenas para o esquema, pois as informações serão replicadas na transferência inicial.
No PostgreSQL 10:
$ pg_dumpall -s > schema.sqlNo PostgreSQL 11:
$ psql -d postgres -f schema.sqlUma vez que temos nosso esquema no PostgreSQL 11, criamos a assinatura, substituindo os valores de host, dbname, user e password por aqueles que correspondem ao nosso ambiente.
PostgreSQL 11:
world=# CREATE SUBSCRIPTION sub1 CONNECTION 'host=192.168.100.143 dbname=world user=rep password=*****' PUBLICATION pub1;
NOTICE: created replication slot "sub1" on publisher
CREATE SUBSCRIPTIONO procedimento acima iniciará o processo de replicação, que sincroniza o conteúdo da tabela inicial das tabelas na publicação e, em seguida, inicia a replicação de alterações incrementais nessas tabelas.
O usuário que cria uma assinatura deve ser um superusuário. O processo de aplicação de assinatura será executado no banco de dados local com os privilégios de um superusuário.
Para verificar a assinatura criada, podemos usar o catálogo pg_stat_subscription. Essa exibição conterá uma linha por assinatura para o trabalhador principal (com PID nulo se o trabalhador não estiver em execução) e linhas adicionais para trabalhadores que manipulam a cópia de dados inicial das tabelas inscritas.
world=# SELECT * FROM pg_stat_subscription;
-[ RECORD 1 ]---------+------------------------------
subid | 16428
subname | sub1
pid | 1111
relid |
received_lsn | 0/172AF90
last_msg_send_time | 2018-12-05 22:11:45.195963+00
last_msg_receipt_time | 2018-12-05 22:11:45.196065+00
latest_end_lsn | 0/172AF90
latest_end_time | 2018-12-05 22:11:45.195963+00Descrições das colunas:
- subid:OID da assinatura.
- subname:nome da assinatura.
- pid:ID do processo do trabalhador de assinatura.
- relid:OID da relação que o trabalhador está sincronizando; null para o principal trabalhador de aplicação.
- received_lsn:último local de registro write-ahead recebido, o valor inicial deste campo é 0.
- last_msg_send_time:hora de envio da última mensagem recebida do remetente WAL de origem.
- last_msg_receipt_time:hora de recebimento da última mensagem recebida do remetente WAL de origem.
- latest_end_lsn:último local de registro de gravação antecipada relatado ao remetente WAL de origem.
- latest_end_time:hora do último local de registro de gravação antecipada relatado ao remetente WAL de origem.
Para verificar o status da replicação no mestre podemos usar pg_stat_replication:
world=# SELECT * FROM pg_stat_replication;
-[ RECORD 1 ]----+------------------------------
pid | 1178
usesysid | 16427
usename | rep
application_name | sub1
client_addr | 192.168.100.144
client_hostname |
client_port | 58270
backend_start | 2018-12-05 22:11:45.097539+00
backend_xmin |
state | streaming
sent_lsn | 0/172AF90
write_lsn | 0/172AF90
flush_lsn | 0/172AF90
replay_lsn | 0/172AF90
write_lag |
flush_lag |
replay_lag |
sync_priority | 0
sync_state | asyncDescrições das colunas:
- pid:ID do processo de um processo do remetente WAL.
- usesysid:OID do usuário conectado a este processo do remetente WAL.
- usename:nome do usuário conectado a este processo de remetente WAL.
- application_name:nome do aplicativo que está conectado a este remetente WAL.
- client_addr:endereço IP do cliente conectado a este remetente WAL. Se este campo for nulo, indica que o cliente está conectado através de um soquete Unix na máquina do servidor.
- client_hostname:nome de host do cliente conectado, conforme relatado por uma pesquisa de DNS reversa de client_addr. Este campo só será não nulo para conexões IP e somente quando log_hostname estiver ativado.
- client_port:número da porta TCP que o cliente está usando para comunicação com este remetente WAL ou -1 se um soquete Unix for usado.
- backend_start:hora em que este processo foi iniciado.
- backend_xmin:o horizonte xmin deste standby relatado por hot_standby_feedback.
- estado:estado atual do remetente WAL. Os valores possíveis são:startup, catchup, streaming, backup e stop.
- sent_lsn:último local de registro de gravação antecipada enviado nesta conexão.
- write_lsn:último local de registro de gravação antecipada gravado no disco por este servidor em espera.
- flush_lsn:último local de registro de gravação antecipada liberado para o disco por este servidor em espera.
- replay_lsn:o último local de log de gravação antecipada reproduzido no banco de dados neste servidor em espera.
- write_lag:tempo decorrido entre a liberação do WAL recente localmente e o recebimento da notificação de que este servidor em espera o gravou (mas ainda não o liberou ou aplicou).
- flush_lag:tempo decorrido entre a liberação do WAL recente localmente e o recebimento da notificação de que este servidor em espera o gravou e liberou (mas ainda não o aplicou).
- replay_lag:tempo decorrido entre a liberação do WAL recente localmente e o recebimento da notificação de que este servidor em espera o gravou, liberou e aplicou.
- sync_priority:prioridade deste servidor em espera para ser escolhido como espera síncrona em uma replicação síncrona baseada em prioridade.
- sync_state:estado síncrono deste servidor em espera. Os valores possíveis são assíncrono, potencial, sincronização, quorum.
Para verificar quando a transferência inicial é concluída, podemos ver o log do PostgreSQL no assinante:
2018-12-05 22:11:45.096 UTC [1111] LOG: logical replication apply worker for subscription "sub1" has started
2018-12-05 22:11:45.103 UTC [1112] LOG: logical replication table synchronization worker for subscription "sub1", table "city" has started
2018-12-05 22:11:45.114 UTC [1113] LOG: logical replication table synchronization worker for subscription "sub1", table "country" has started
2018-12-05 22:11:45.156 UTC [1112] LOG: logical replication table synchronization worker for subscription "sub1", table "city" has finished
2018-12-05 22:11:45.162 UTC [1114] LOG: logical replication table synchronization worker for subscription "sub1", table "countrylanguage" has started
2018-12-05 22:11:45.168 UTC [1113] LOG: logical replication table synchronization worker for subscription "sub1", table "country" has finished
2018-12-05 22:11:45.206 UTC [1114] LOG: logical replication table synchronization worker for subscription "sub1", table "countrylanguage" has finishedOu verificando a variável srsubstate no catálogo pg_subscription_rel. Este catálogo contém o estado de cada relação replicada em cada assinatura.
world=# SELECT * FROM pg_subscription_rel;
-[ RECORD 1 ]---------
srsubid | 16428
srrelid | 16387
srsubstate | r
srsublsn | 0/172AF20
-[ RECORD 2 ]---------
srsubid | 16428
srrelid | 16393
srsubstate | r
srsublsn | 0/172AF58
-[ RECORD 3 ]---------
srsubid | 16428
srrelid | 16400
srsubstate | r
srsublsn | 0/172AF90Descrições das colunas:
- srsubid:referência à assinatura.
- srrelid:referência à relação.
- srsubstate:Código de estado:i =inicializar, d =dados estão sendo copiados, s =sincronizado, r =pronto (replicação normal).
- srsublsn:termina o LSN para os estados s e r.
Podemos inserir alguns registros de teste em nosso PostgreSQL 10 e validar que os temos em nosso PostgreSQL 11:
PostgreSQL 10:
world=# INSERT INTO city (id,name,countrycode,district,population) VALUES (5001,'city1','USA','District1',10000);
INSERT 0 1
world=# INSERT INTO city (id,name,countrycode,district,population) VALUES (5002,'city2','ITA','District2',20000);
INSERT 0 1
world=# INSERT INTO city (id,name,countrycode,district,population) VALUES (5003,'city3','CHN','District3',30000);
INSERT 0 1PostgreSQL 11:
world=# SELECT * FROM city WHERE id>5000;
id | name | countrycode | district | population
------+-------+-------------+-----------+------------
5001 | city1 | USA | District1 | 10000
5002 | city2 | ITA | District2 | 20000
5003 | city3 | CHN | District3 | 30000
(3 rows)Neste ponto, temos tudo pronto para apontar nossa aplicação para o nosso PostgreSQL 11.
Para isso, antes de tudo, precisamos confirmar que não temos lag de replicação.
No mestre:
world=# SELECT application_name, pg_wal_lsn_diff(pg_current_wal_lsn(), replay_lsn) lag FROM pg_stat_replication;
-[ RECORD 1 ]----+-----
application_name | sub1
lag | 0E agora, precisamos apenas alterar nosso endpoint de nosso aplicativo ou balanceador de carga (se tivermos um) para o novo servidor PostgreSQL 11.
Se tivermos um load balancer como o HAProxy, podemos configurá-lo usando o PostgreSQL 10 como ativo e o PostgreSQL 11 como backup, desta forma:
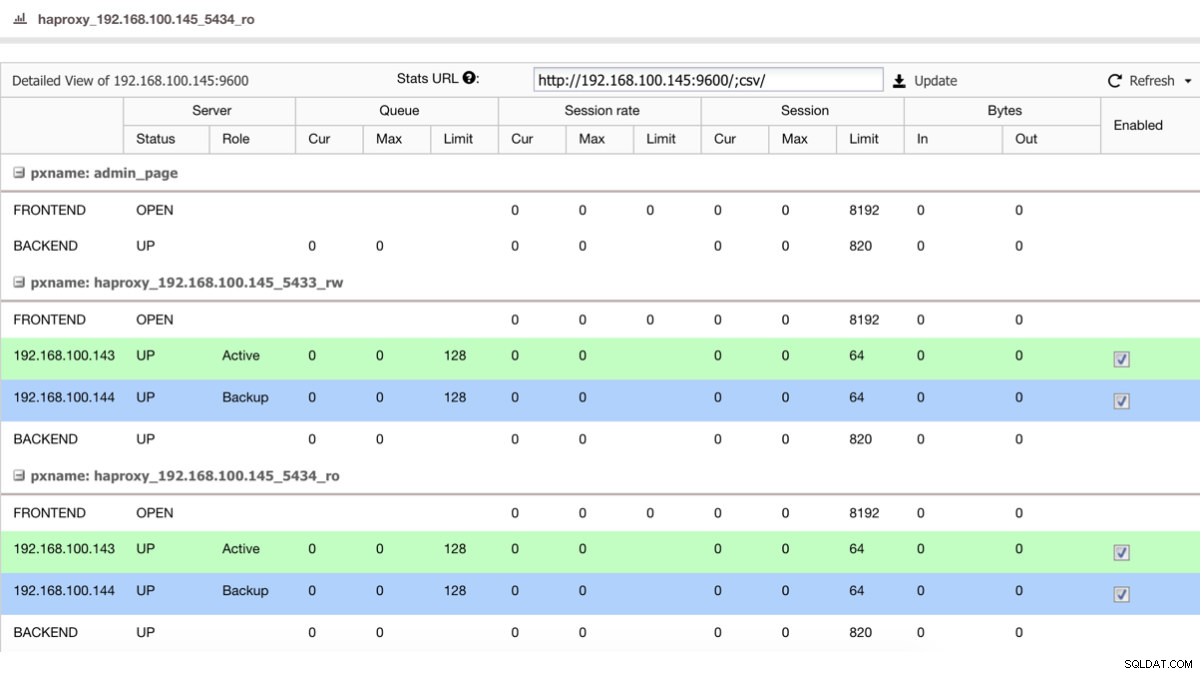 Visualização de status do HAProxy
Visualização de status do HAProxy Então, se você acabou de desligar o master no PostgreSQL 10, o servidor de backup, neste caso no PostgreSQL 11, passa a receber o tráfego de forma transparente para o usuário/aplicativo.
Ao final da migração, podemos excluir a assinatura em nosso novo mestre no PostgreSQL 11:
world=# DROP SUBSCRIPTION sub1;
NOTICE: dropped replication slot "sub1" on publisher
DROP SUBSCRIPTIONE verifique se ele foi removido corretamente:
world=# SELECT * FROM pg_subscription_rel;
(0 rows)
world=# SELECT * FROM pg_stat_subscription;
(0 rows)Limitações
Antes de usar a replicação lógica, lembre-se das seguintes limitações:
- O esquema do banco de dados e os comandos DDL não são replicados. O esquema inicial pode ser copiado usando pg_dump --schema-only.
- Os dados de sequência não são replicados. Os dados em colunas seriais ou de identidade apoiados por sequências serão replicados como parte da tabela, mas a própria sequência ainda mostrará o valor inicial no assinante.
- A replicação de comandos TRUNCATE é suportada, mas alguns cuidados devem ser tomados ao truncar grupos de tabelas conectadas por chaves estrangeiras. Ao replicar uma ação de truncar, o assinante truncará o mesmo grupo de tabelas que foi truncado no publicador, especificado explicitamente ou coletado implicitamente via CASCADE, menos as tabelas que não fazem parte da assinatura. Isso funcionará corretamente se todas as tabelas afetadas fizerem parte da mesma assinatura. Mas se algumas tabelas a serem truncadas no assinante tiverem links de chave estrangeira para tabelas que não fazem parte da mesma (ou de nenhuma) assinatura, a aplicação da ação truncar no assinante falhará.
- Os objetos grandes não são replicados. Não há solução para isso, além de armazenar dados em tabelas normais.
- A replicação só é possível de tabelas base para tabelas base. Ou seja, as tabelas na publicação e no lado da assinatura devem ser tabelas normais, não exibições, exibições materializadas, tabelas raiz de partição ou tabelas estrangeiras. No caso de partições, você pode replicar uma hierarquia de partição individualmente, mas atualmente não pode replicar para uma configuração particionada de forma diferente.
Conclusão
Manter seu servidor PostgreSQL atualizado através de atualizações regulares foi uma tarefa necessária, mas difícil, até a versão 10 do PostgreSQL.
Neste blog, fizemos uma breve introdução à replicação lógica, um recurso do PostgreSQL introduzido nativamente na versão 10, e mostramos como ele pode ajudá-lo a superar esse desafio com uma estratégia de tempo de inatividade zero.



