TeamCity é um servidor de integração e entrega contínuas construído em Java. Ele está disponível como um serviço de nuvem e no local. Como você pode imaginar, as ferramentas de integração e entrega contínuas são cruciais para o desenvolvimento de software e sua disponibilidade não deve ser afetada. Felizmente, o TeamCity pode ser implantado em um modo de alta disponibilidade.
Esta postagem de blog abordará a preparação e implantação de um ambiente altamente disponível para o TeamCity.
O Meio Ambiente
TeamCity consiste em vários elementos. Há um aplicativo Java e um banco de dados que o faz backup. Ele também usa agentes que estão se comunicando com a instância principal do TeamCity. A implantação altamente disponível consiste em várias instâncias do TeamCity, onde uma está atuando como primária e as outras secundárias. Essas instâncias compartilham o acesso ao mesmo banco de dados e ao diretório de dados. O esquema útil está disponível na página de documentação do TeamCity, conforme mostrado abaixo:

Como podemos ver, há dois elementos compartilhados — o diretório de dados e o banco de dados. Devemos garantir que eles também estejam altamente disponíveis. Existem diferentes opções que você pode usar para criar uma montagem compartilhada. no entanto, usaremos o GlusterFS. Quanto ao banco de dados, usaremos um dos sistemas de gerenciamento de banco de dados relacional suportados — PostgreSQL, e usaremos o ClusterControl para criar uma pilha de alta disponibilidade com base nele.
Como configurar o GlusterFS
Vamos começar com o básico. Queremos configurar nomes de host e /etc/hosts em nossos nós TeamCity, onde também implantaremos o GlusterFS. Para fazer isso, precisamos configurar o repositório para os pacotes mais recentes do GlusterFS em todos eles:
sudo add-apt-repository ppa:gluster/glusterfs-7
sudo apt updateEntão podemos instalar o GlusterFS em todos os nossos nós TeamCity:
sudo apt install glusterfs-server
sudo systemctl enable glusterd.service
example@sqldat.com:~# sudo systemctl start glusterd.service
example@sqldat.com:~# sudo systemctl status glusterd.service
● glusterd.service - GlusterFS, a clustered file-system server
Loaded: loaded (/lib/systemd/system/glusterd.service; enabled; vendor preset: enabled)
Active: active (running) since Mon 2022-02-21 11:42:35 UTC; 7s ago
Docs: man:glusterd(8)
Process: 48918 ExecStart=/usr/sbin/glusterd -p /var/run/glusterd.pid --log-level $LOG_LEVEL $GLUSTERD_OPTIONS (code=exited, status=0/SUCCESS)
Main PID: 48919 (glusterd)
Tasks: 9 (limit: 4616)
Memory: 4.8M
CGroup: /system.slice/glusterd.service
└─48919 /usr/sbin/glusterd -p /var/run/glusterd.pid --log-level INFO
Feb 21 11:42:34 node1 systemd[1]: Starting GlusterFS, a clustered file-system server...
Feb 21 11:42:35 node1 systemd[1]: Started GlusterFS, a clustered file-system server.O GlusterFS usa a porta 24007 para conectividade entre os nós; devemos ter certeza de que está aberto e acessível por todos os nós.
Uma vez que a conectividade esteja estabelecida, podemos criar um cluster GlusterFS executando a partir de um nó:
example@sqldat.com:~# gluster peer probe node2
peer probe: success.
example@sqldat.com:~# gluster peer probe node3
peer probe: success.Agora, podemos testar como o status se parece:
example@sqldat.com:~# gluster peer status
Number of Peers: 2
Hostname: node2
Uuid: e0f6bc53-d47d-4db6-843b-9feea111a713
State: Peer in Cluster (Connected)
Hostname: node3
Uuid: c7d285d1-bcc8-477f-a3d7-7e56ff6bfd1a
State: Peer in Cluster (Connected)Parece que tudo está bem e a conectividade está funcionando.
Em seguida, devemos preparar um dispositivo de bloco para ser usado pelo GlusterFS. Isso deve ser executado em todos os nós. Primeiro, crie uma partição:
example@sqldat.com:~# echo 'type=83' | sudo sfdisk /dev/sdb
Checking that no-one is using this disk right now ... OK
Disk /dev/sdb: 30 GiB, 32212254720 bytes, 62914560 sectors
Disk model: VBOX HARDDISK
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
>>> Created a new DOS disklabel with disk identifier 0xbcf862ff.
/dev/sdb1: Created a new partition 1 of type 'Linux' and of size 30 GiB.
/dev/sdb2: Done.
New situation:
Disklabel type: dos
Disk identifier: 0xbcf862ff
Device Boot Start End Sectors Size Id Type
/dev/sdb1 2048 62914559 62912512 30G 83 Linux
The partition table has been altered.
Calling ioctl() to re-read partition table.
Syncing disks.Em seguida, formate essa partição:
example@sqldat.com:~# mkfs.xfs -i size=512 /dev/sdb1
meta-data=/dev/sdb1 isize=512 agcount=4, agsize=1966016 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=1, sparse=1, rmapbt=0
= reflink=1
data = bsize=4096 blocks=7864064, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0, ftype=1
log =internal log bsize=4096 blocks=3839, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0Por fim, em todos os nós, precisamos criar um diretório que será usado para montar a partição e editar o fstab para garantir que ele seja montado na inicialização:
example@sqldat.com:~# mkdir -p /data/brick1
echo '/dev/sdb1 /data/brick1 xfs defaults 1 2' >> /etc/fstabVamos verificar agora se isso funciona:
example@sqldat.com:~# mount -a && mount | grep brick
/dev/sdb1 on /data/brick1 type xfs (rw,relatime,attr2,inode64,logbufs=8,logbsize=32k,noquota)Agora podemos usar um dos nós para criar e iniciar o volume GlusterFS:
example@sqldat.com:~# sudo gluster volume create teamcity replica 3 node1:/data/brick1 node2:/data/brick1 node3:/data/brick1 force
volume create: teamcity: success: please start the volume to access data
example@sqldat.com:~# sudo gluster volume start teamcity
volume start: teamcity: successObserve que usamos o valor '3' para o número de réplicas. Isso significa que cada volume existirá em três cópias. No nosso caso, cada bloco, cada volume /dev/sdb1 em todos os nós conterá todos os dados.
Depois que os volumes são iniciados, podemos verificar seu status:
example@sqldat.com:~# sudo gluster volume status
Status of volume: teamcity
Gluster process TCP Port RDMA Port Online Pid
------------------------------------------------------------------------------
Brick node1:/data/brick1 49152 0 Y 49139
Brick node2:/data/brick1 49152 0 Y 49001
Brick node3:/data/brick1 49152 0 Y 51733
Self-heal Daemon on localhost N/A N/A Y 49160
Self-heal Daemon on node2 N/A N/A Y 49022
Self-heal Daemon on node3 N/A N/A Y 51754
Task Status of Volume teamcity
------------------------------------------------------------------------------
There are no active volume tasksComo você pode ver, tudo parece bem. O importante é que o GlusterFS escolheu a porta 49152 para acessar esse volume e devemos garantir que ele seja acessível em todos os nós em que o montaremos.
O próximo passo será instalar o pacote cliente GlusterFS. Para este exemplo, precisamos que ele seja instalado nos mesmos nós do servidor GlusterFS:
example@sqldat.com:~# sudo apt install glusterfs-client
Reading package lists... Done
Building dependency tree
Reading state information... Done
glusterfs-client is already the newest version (7.9-ubuntu1~focal1).
glusterfs-client set to manually installed.
0 upgraded, 0 newly installed, 0 to remove and 0 not upgraded.Em seguida, precisamos criar um diretório em todos os nós para ser usado como um diretório de dados compartilhados para o TeamCity. Isso tem que acontecer em todos os nós:
example@sqldat.com:~# sudo mkdir /teamcity-storagePor último, monte o volume GlusterFS em todos os nós:
example@sqldat.com:~# sudo mount -t glusterfs node1:teamcity /teamcity-storage/
example@sqldat.com:~# df | grep teamcity
node1:teamcity 31440900 566768 30874132 2% /teamcity-storageIsso conclui os preparativos do armazenamento compartilhado.
Criando um cluster PostgreSQL altamente disponível
Depois que a configuração de armazenamento compartilhado para TeamCity estiver concluída, agora podemos construir nossa infraestrutura de banco de dados altamente disponível. O TeamCity pode usar diferentes bancos de dados; no entanto, usaremos o PostgreSQL neste blog. Aproveitaremos o ClusterControl para implantar e gerenciar o ambiente de banco de dados.
O guia do TeamCity para criar implantação de vários nós é útil, mas parece deixar de fora a alta disponibilidade de tudo que não seja o TeamCity. O guia do TeamCity sugere um servidor NFS ou SMB para armazenamento de dados, que, por si só, não possui redundância e se tornará um único ponto de falha. Resolvemos isso usando GlusterFS. Eles mencionam um banco de dados compartilhado, pois um único nó de banco de dados obviamente não fornece alta disponibilidade. Temos que construir uma pilha adequada:

No nosso caso. ele consistirá em três nós PostgreSQL, um primário e duas réplicas. Usaremos o HAProxy como um balanceador de carga e usaremos o Keepalived para gerenciar o IP virtual para fornecer um único ponto de extremidade ao qual o aplicativo se conectar. O ClusterControl lidará com falhas monitorando a topologia de replicação e realizando qualquer recuperação necessária conforme necessário, como reiniciar processos com falha ou fazer failover para uma das réplicas se o nó principal ficar inativo.
Para começar, vamos implantar os nós do banco de dados. Lembre-se de que o ClusterControl requer conectividade SSH do nó ClusterControl para todos os nós que ele gerencia.

Então, escolhemos um usuário que usaremos para conectar ao banco de dados, sua senha e a versão do PostgreSQL para implantação:

A seguir, vamos definir quais nós usar para implantar o PostgreSQL :
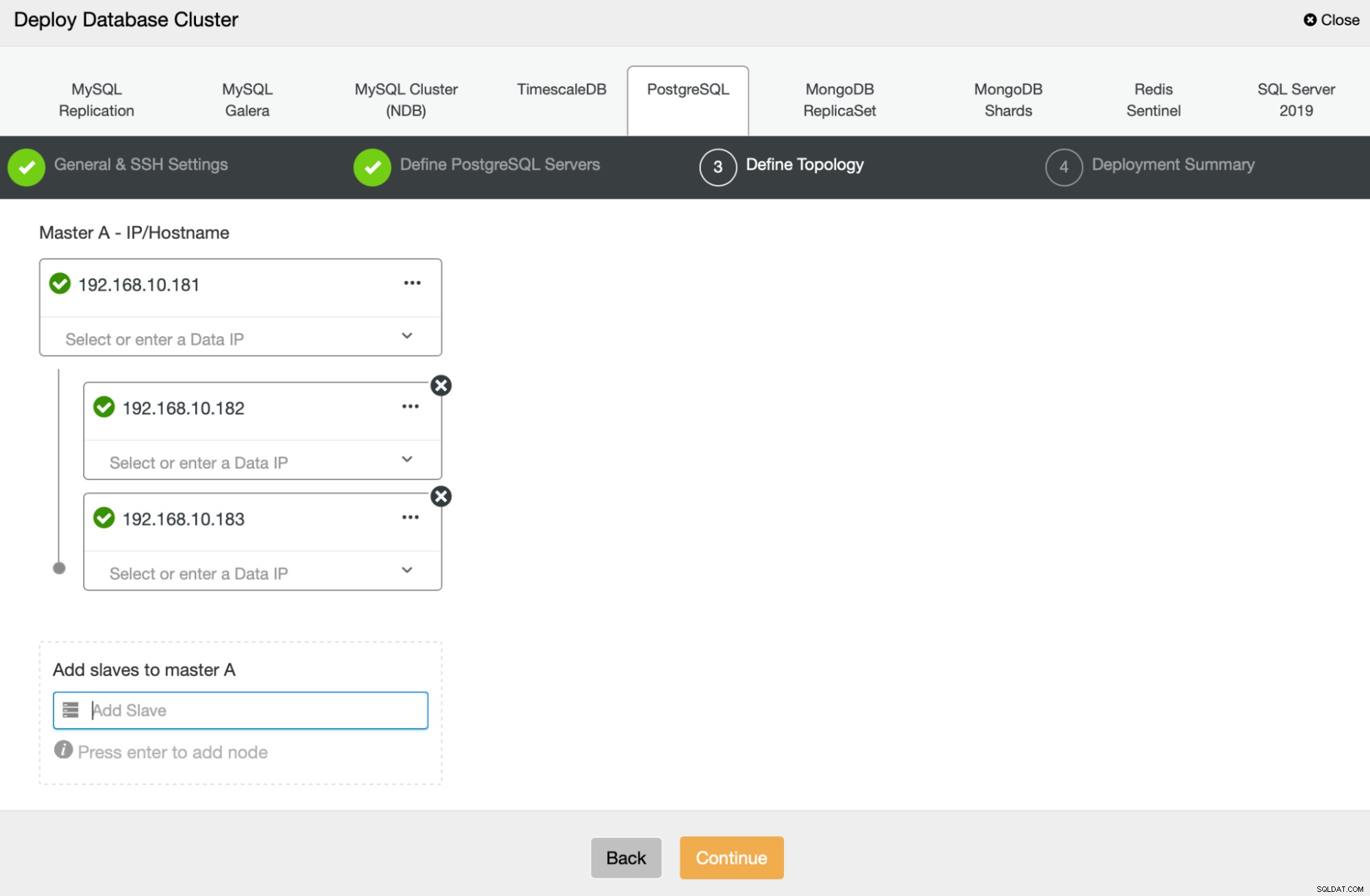
Por fim, podemos definir se os nós devem usar replicação assíncrona ou síncrona. A principal diferença entre esses dois é que a replicação síncrona garante que todas as transações executadas no nó primário sempre sejam replicadas nas réplicas. No entanto, a replicação síncrona também torna a confirmação mais lenta. Recomendamos habilitar a replicação síncrona para obter a melhor durabilidade, mas você deve verificar posteriormente se o desempenho é aceitável.

Depois de clicarmos em "Implantar", um trabalho de implantação será iniciado. Podemos monitorar seu progresso na guia Atividade na interface do usuário do ClusterControl. Eventualmente, veremos que o trabalho foi concluído e o cluster foi implantado com êxito.

Implante instâncias HAProxy acessando Gerenciar -> balanceadores de carga. Selecione HAProxy como o balanceador de carga e preencha o formulário. A escolha mais importante é onde você deseja implantar o HAProxy. Usamos um nó de banco de dados neste caso, mas em um ambiente de produção, você provavelmente deseja separar os balanceadores de carga das instâncias de banco de dados. Em seguida, selecione quais nós do PostgreSQL incluir no HAProxy. Queremos todos eles.

Agora a implantação do HAProxy será iniciada. Queremos repeti-lo pelo menos mais uma vez para criar duas instâncias HAProxy para redundância. Nesta implantação, decidimos usar três balanceadores de carga HAProxy. Abaixo está uma captura de tela da tela de configurações ao configurar a implantação de um segundo HAProxy:
Quando todas as nossas instâncias HAProxy estiverem em funcionamento, podemos implantar Keepalived . A ideia aqui é que o Keepalived seja colocado junto com o HAProxy e monitore o processo do HAProxy. Uma das instâncias com HAProxy funcionando terá o IP virtual atribuído. Esse VIP deve ser usado pelo aplicativo para se conectar ao banco de dados. Keepalived detectará se esse HAProxy se tornar indisponível e passará para outra instância de HAProxy disponível.
O assistente de implantação exige que passemos as instâncias do HAProxy que queremos que o Keepalived monitore. Também precisamos passar o endereço IP e a interface de rede para o VIP.

O último e último passo será criar um banco de dados para TeamCity:

Com isso, concluímos a implantação do cluster PostgreSQL altamente disponível.
Implantando TeamCity como vários nós
A próxima etapa é implantar o TeamCity em um ambiente de vários nós. Usaremos três nós do TeamCity. Primeiro, temos que instalar Java JRE e JDK que correspondam aos requisitos do TeamCity.
apt install default-jre default-jdkAgora, em todos os nós, temos que baixar o TeamCity. Vamos instalar em um diretório local, não compartilhado.
example@sqldat.com:~# cd /var/lib/teamcity-local/
example@sqldat.com:/var/lib/teamcity-local# wget https://download.jetbrains.com/teamcity/TeamCity-2021.2.3.tar.gzEntão podemos iniciar o TeamCity em um dos nós:
example@sqldat.com:~# /var/lib/teamcity-local/TeamCity/bin/runAll.sh start
Spawning TeamCity restarter in separate process
TeamCity restarter running with PID 83162
Starting TeamCity build agent...
Java executable is found: '/usr/lib/jvm/default-java/bin/java'
Starting TeamCity Build Agent Launcher...
Agent home directory is /var/lib/teamcity-local/TeamCity/buildAgent
Agent Launcher Java runtime version is 11
Lock file: /var/lib/teamcity-local/TeamCity/buildAgent/logs/buildAgent.properties.lock
Using no lock
Done [83731], see log at /var/lib/teamcity-local/TeamCity/buildAgent/logs/teamcity-agent.logDepois que o TeamCity for iniciado, podemos acessar a interface do usuário e iniciar a implantação. Inicialmente, temos que passar o local do diretório de dados. Este é o volume compartilhado que criamos no GlusterFS.

Em seguida, escolha o banco de dados. Vamos usar um cluster PostgreSQL que já criamos.

Baixe e instale o driver JDBC:

Em seguida, preencha os detalhes de acesso. Usaremos o IP virtual fornecido pelo Keepalived. Observe que usamos a porta 5433. Esta é a porta usada para o backend de leitura/gravação do HAProxy; ele sempre apontará para o nó primário ativo. Em seguida, escolha um usuário e o banco de dados para usar com o TeamCity.

Uma vez feito isso, o TeamCity começará a inicializar a estrutura do banco de dados.

Concordo com o Contrato de Licença:

Finalmente, crie um usuário para TeamCity:

É isso aí! Agora devemos ser capazes de ver a GUI do TeamCity:

Agora, temos que configurar o TeamCity no modo multi-nó. Primeiro, temos que editar os scripts de inicialização em todos os nós:
example@sqldat.com:~# vim /var/lib/teamcity-local/TeamCity/bin/runAll.shTemos que garantir que as duas variáveis a seguir sejam exportadas. Verifique se você usa o nome de host, o IP e os diretórios corretos para armazenamento local e compartilhado:
export TEAMCITY_SERVER_OPTS="-Dteamcity.server.nodeId=node1 -Dteamcity.server.rootURL=https://192.168.10.221 -Dteamcity.data.path=/teamcity-storage -Dteamcity.node.data.path=/var/lib/teamcity-local"
export TEAMCITY_DATA_PATH="/teamcity-storage"Uma vez feito isso, você pode iniciar os nós restantes:
example@sqldat.com:~# /var/lib/teamcity-local/TeamCity/bin/runAll.sh startVocê deve ver a seguinte saída em Administração -> Configuração de nós:Um nó principal e dois nós de espera.

Lembre-se de que o failover no TeamCity não é automatizado. Se o nó principal parar de funcionar, você deverá se conectar a um dos nós secundários. Para fazer isso, acesse "Configuração de nós" e promova-o ao nó "Principal". Na tela de login, você verá uma indicação clara de que este é um nó secundário:

Na "Configuração de nós", você verá que um nó tem retirado do cluster:

Você receberá uma mensagem informando que não pode gravar neste nó. Não se preocupe; a gravação necessária para promover este nó ao status “principal” funcionará bem:

Clique em "Ativar" e promovemos um nó TimeCity secundário:

Quando o node1 estiver disponível e o TeamCity for iniciado novamente nesse node, nós iremos veja-o se juntar ao cluster:

Se quiser melhorar ainda mais o desempenho, você pode implantar o HAProxy + Keepalived na frente da interface do usuário do TeamCity para fornecer um único ponto de entrada para a GUI. Você pode encontrar detalhes sobre como configurar o HAProxy for TeamCity na documentação.
Encerrando
Como você pode ver, a implantação do TeamCity para alta disponibilidade não é tão difícil — a maior parte disso foi abordada detalhadamente na documentação. Se você estiver procurando maneiras de automatizar parte disso e adicionar um back-end de banco de dados altamente disponível, considere avaliar o ClusterControl gratuitamente por 30 dias. O ClusterControl pode implantar e monitorar rapidamente o back-end, fornecendo failover automatizado, recuperação, monitoramento, gerenciamento de backup e muito mais.
Para obter mais dicas sobre ferramentas de desenvolvimento de software e práticas recomendadas, confira como apoiar sua equipe de DevOps com suas necessidades de banco de dados.
Para obter as últimas notícias e práticas recomendadas para gerenciar sua infraestrutura de banco de dados baseada em código aberto, não se esqueça de nos seguir no Twitter ou LinkedIn e assinar nosso boletim informativo. Vejo você em breve!