Em meu artigo anterior sobre Bancos de Dados do Sistema SQL Server, aprendemos sobre cada banco de dados do sistema que vem como parte da instalação do SQL Server. O artigo atual se concentrará nos problemas enfrentados com frequência no banco de dados tempdb e em como resolvê-los corretamente.
SQL Server TempDB
Como o nome deste banco de dados do sistema indica, tempdb contém objetos temporários criado pelo SQL Server. Eles estão relacionados a várias operações e atuam como uma área de trabalho global para todos os usuários que se conectam às instâncias do SQL Server.
O banco de dados Tempdb manterá os tipos de objeto abaixo enquanto os usuários realizam suas operações:
- Os objetos temporários são criados explicitamente pelos usuários. Eles podem ser tabelas e índices temporários locais ou globais, variáveis de tabela, tabelas usadas em funções com valor de tabela e cursores.
- Objetos internos criados pelo mecanismo de banco de dados como
- Tabelas de trabalho que armazenam resultados intermediários para spools, cursores, classificações e objetos grandes temporários (LOB).
- Arquivos de trabalho durante a execução de operações de junção de hash ou agregação de hash.
- Resultados de classificação intermediários ao criar ou reconstruir índices se SORT_IN_TEMPDB estiver definido como ON e outras operações como consultas GROUP BY, ORDER BY ou SQL UNION.
- Os armazenamentos de versão que oferecem suporte ao recurso de controle de versão de linha, armazenamento de versão comum ou armazenamento de versão de compilação de índice online usam os arquivos de banco de dados tempdb.
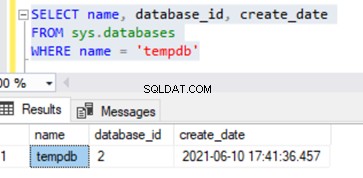
O banco de dados Tempdb é criado sempre que o SQL Server Service é iniciado. Portanto, a hora da criação do banco de dados tempdb pode ser considerada como uma hora aproximada de inicialização do SQL Server Service. Podemos identificá-lo no sys.databases DMV usando a consulta mostrada abaixo:
SELECT name, database_id, create_date
FROM sys.databases
WHERE name = 'tempdb'
No entanto, a inicialização real do SQL Server Service envolve a inicialização de todos os bancos de dados do sistema em uma sequência específica. Isso pode acontecer um pouco antes do tempo de criação do tempdb. Podemos obter o valor usando sys.databases DMV executando a consulta abaixo em sys.dm_os_sys_info DMV .
SELECT ms_ticks, sqlserver_start_time_ms_ticks, sqlserver_start_time
FROM sys.dm_os_sys_info
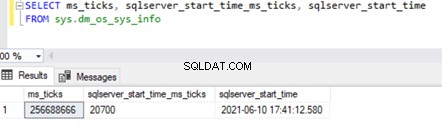
Os ms_ticks coluna especifica o número de milissegundos desde que o computador ou servidor foi iniciado. Os sqlserver_start_time_ms_ticks coluna especifica o número de milissegundos desde o ms_ticks número quando o SQL Server Service foi iniciado.
Podemos encontrar mais informações sobre a ordem dos bancos de dados que foram iniciados ao iniciar os serviços do SQL Server no log de erros do SQL Server.
No SSMS, expanda Gerenciamento > Logs de erros do SQL Server > abra o atual registro de erros. Aplique o Início base de dados filtre e clique em Data para classificá-lo em ordem crescente:
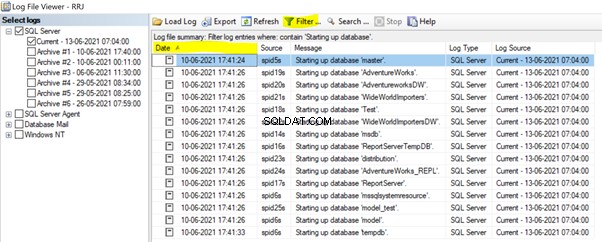
Podemos ver que o banco de dados mestre foi iniciado primeiro ao iniciar o serviço SQL Server. Em seguida, todos os bancos de dados do usuário e todos os outros bancos de dados do sistema seguiram. Finalmente, o tempdb foi iniciado. Você também pode buscar essas informações programaticamente executando o xp_readerrorlog procedimento do sistema:
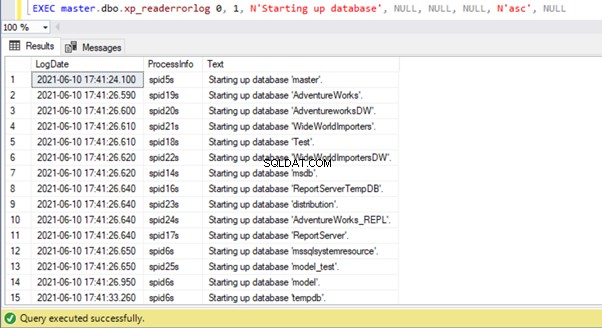
Observação Observação:ambas as abordagens acima podem não mostrar as informações necessárias se o SQL Server Service não foi reiniciado recentemente e o log de erros do SQL Server foi reciclado, o que pode ter enviado logs de erros mais antigos para arquivos mais antigos. Nesse caso, talvez seja necessário verificar os dados nos arquivos de log de erros do SQL Server arquivados.
Problemas frequentes no banco de dados SQL TempDB
Como o tempdb fornece uma área de trabalho global para todas as sessões ou atividades do usuário, ele pode se tornar um gargalo de desempenho para as operações do usuário se não for configurado com cuidado. Em meu artigo anterior, discutimos as melhores práticas recomendadas para implementar no banco de dados tempdb. No entanto, mesmo depois de implementá-los, podemos encontrar problemas com frequência:
- Crescimento desigual de arquivos em arquivos de dados tempdb.
- Os arquivos de dados Tempdb estão ganhando um valor enorme e precisam reduzir o Tempdb.
Crescimento desigual de arquivos em arquivos de dados TempDB
A partir do SQL Server 2000, a recomendação padrão é ter vários arquivos de dados com base na contagem de núcleos lógicos disponíveis no servidor.
Quando temos vários arquivos de dados, por exemplo, 4 arquivos de dados tempdb como na imagem abaixo, o crescimento automático dos arquivos de dados tempdb acontecerá em 64 MB de forma round-robin começando em tempdev> temp2> temp3> temp4> tempdev> e assim por diante.
Se um dos tamanhos de arquivo não puder crescer automaticamente por algum motivo, isso resultará em tamanhos enormes de determinados arquivos em comparação com outros arquivos. Isso leva a uma sobrecarga adicional colocada em arquivos enormes e um impacto negativo no desempenho do banco de dados tempdb.
Precisamos garantir manualmente que todos os arquivos de dados tempdb sejam dimensionados uniformemente a qualquer momento manualmente para evitar problemas de contenção ou desempenho até o SQL Server 2014. A Microsoft alterou esse comportamento a partir do SQL Server 2016 e versões posteriores, implementando alguns recursos que serão discutido mais adiante neste artigo.
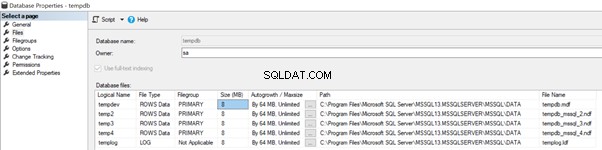
Para superar os problemas de desempenho acima, o SQL Server introduziu 2 sinalizadores de rastreamento chamado 1117 e 1118 para evitar os problemas de contenção em torno do tempdb.
- Sinalizador de rastreamento 1117 – permite o crescimento automático de todos os arquivos em um único grupo de arquivos
- Sinalizador de rastreamento 1118 – habilita UNIFORM FULL EXTENTS para tempdb
Sinalizador de rastreamento 1117
Sem o sinalizador de rastreamento 1117 habilitado, sempre que o tempdb for configurado com vários arquivos de dados com tamanho uniforme e os arquivos de dados precisarem crescer automaticamente, o SQL Server, por padrão, tentará aumentar os tamanhos dos arquivos de forma round-robin se todos os arquivos. Se os arquivos de dados não forem dimensionados uniformemente, o SQL Server tentará aumentar o tamanho do maior arquivo de dados de tempdb e usará esse arquivo maior para a maioria das operações do usuário, resultando em problemas de contenção de tempdb.
Para resolver esse problema, o SQL Server introduziu o sinalizador de rastreamento 1117. Uma vez habilitado, se um arquivo em um grupo de arquivos precisar crescer automaticamente, ele aumentará automaticamente todos os arquivos desse grupo de arquivos. Ele resolve os problemas de contenção do tempdb. No entanto, o problema é que, assim que o sinalizador de rastreamento 1117 estiver ativado, o crescimento automático também será configurado para todos os bancos de dados de usuários.
Sinalizador de rastreamento 1118
O sinalizador de rastreamento 1118 é usado para habilitar UNIFORM FULL EXTENTS. Vamos dar um passo atrás para entender como o SQL Server armazena os dados do básico.
Página é a unidade fundamental de armazenamento no SQL Server com um tamanho de 8 Kilobytes (KB).
Extensão é um conjunto de 8 páginas fisicamente contíguas com o tamanho de 64KB(8*8KB). Com base em quantos objetos ou proprietários armazenam os dados em uma extensão, a extensão pode ser classificada em:
- Extensões uniformes são 8 páginas contíguas usadas ou acessadas por um único objeto ou proprietário;
- Misto Extensões – são 8 páginas contíguas usadas ou acessadas por no mínimo 2 e no máximo 8 objetos ou proprietários
A ativação do sinalizador de rastreamento 1118 permitirá que o tempdb tenha extensões uniformes, resultando em melhor desempenho.
Como ativar sinalizadores de rastreamento 1117 e 1118
Os sinalizadores de rastreamento podem ser ativados por meio de várias abordagens. Você pode definir a forma adequada a partir das opções abaixo:
Parâmetros de inicialização do serviço SQL Server
Disponível permanentemente mesmo após a reinicialização do serviço SQL. A maneira recomendada é habilitar os sinalizadores de rastreamento 1117 e 1118 por meio dos parâmetros de inicialização do SQL Server Service .
Abra o SQL Server Configuration Manager e clique em Serviços do SQL Server para listar os serviços disponíveis nesse servidor:

- Clique com o botão direito do mouse em SQL Server (MSSQLSERVER) > Propriedades > Parâmetros de inicialização .
- Tipo –T no campo vazio para indicar o Sinalizador de rastreamento .
- Forneça valores 1117 e 1118 conforme mostrado abaixo.
- Clique em Adicionar para ter os sinalizadores de rastreamento adicionados como parâmetros de inicialização.
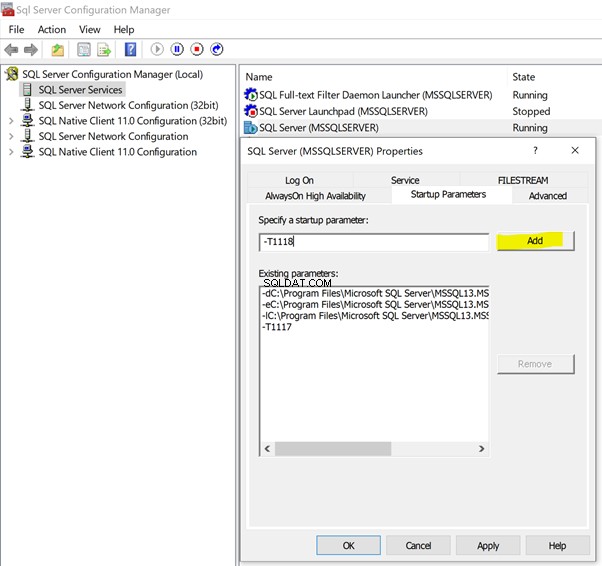
Em seguida, clique em OK para ter os sinalizadores de rastreamento adicionados permanentemente para esta instância do SQL Server. Reinicie o SQL Server Service para que as alterações sejam refletidas.
DBCC TRACEON (, -1)
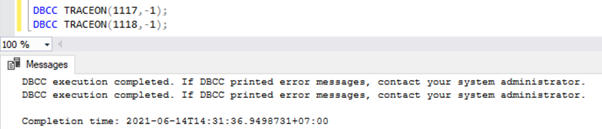
Habilite um sinalizador de rastreamento globalmente. O serviço SQL Server perderá os sinalizadores de rastreamento após a reinicialização do serviço. Para habilitar um sinalizador de rastreamento globalmente, execute o script abaixo em uma nova janela de consulta:
DBCC TRACEON(1117,-1);
DBCC TRACEON(1118,-1);
DBCC TRACEON ()
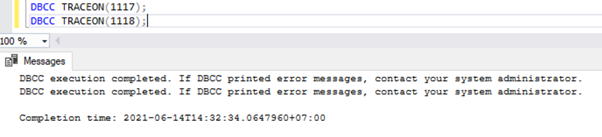
Habilite o sinalizador de rastreamento em nível de sessão. Aplica-se apenas à sessão atual criada pelo usuário. Para habilitar um sinalizador de rastreamento no nível da sessão, execute o script abaixo em uma nova janela de consulta:
DBCC TRACEON(1117);
DBCC TRACEON(1118);
Para visualizar a lista de sinalizadores de rastreamento habilitados em uma instância do SQL Server, podemos usar o DBCC TRACESTATUS comando:
DBCC TRACESTATUS();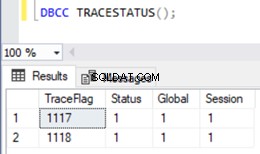
Como podemos ver, Trace Flags 1117 e 1118 estão habilitados globalmente na minha instância junto com Session .
Para desativar um sinalizador de rastreamento, podemos usar o comando DBCC TRACEOFF como:
DBCC TRACEOFF(1117,-1);
DBCC TRACEOFF(1118,-1);
Aprimoramentos do SQL Server 2016 TempDB
Nas versões do SQL Server do SQL Server 2000 ao SQL Server 2014, temos que habilitar os sinalizadores de rastreamento 1117 e 1118 junto com o monitoramento completo de tempdb para evitar problemas de contenção de tempdb. A partir do SQL Server 2016 e versões posteriores, os sinalizadores de rastreamento 1117 e 1118 são implementados por padrão.
No entanto, com base na minha experiência pessoal, é melhor pré-aumentar o tempdb para um tamanho enorme para evitar a necessidade de crescimento automático várias vezes e eliminar tamanhos de arquivo irregulares ou arquivos únicos usados extensivamente pelo SQL Server .
Podemos verificar como o Trace Flag 1117 e 1118 são implementados no SQL Server 2016:
Sinalizador de rastreamento 1117 que define o crescimento automático de todos os arquivos dentro de um grupo de arquivos agora é uma propriedade do grupo de arquivos . Podemos configurá-lo ao criar um novo grupo de arquivos ou modificar um existente.
Para verificar a propriedade de crescimento automático do grupo de arquivos , execute o script abaixo em sys.filegroups DMV :
SELECT name Filegroup_Name, is_autogrow_all_files
FROM sys.filegroups
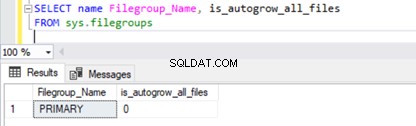
Para modificar a propriedade de crescimento automático do banco de dados do Grupo de arquivos primário do AdventureWorks , executamos o script abaixo com AUTOGROW_ALL_FILES para aumentar automaticamente todos os arquivos igualmente ou AUTOGROW_SINGLE_FILE para permitir o crescimento automático de apenas um único arquivo de dados.
ALTER DATABASE Adventureworks MODIFY FILEGROUP [PRIMARY]
AUTOGROW_SINGLE_FILE
-- AUTOGROW_ALL_FILES is the default behavior
GO
Sinalizador de rastreamento 1118 que define a propriedade Uniform Extent dos arquivos de dados é habilitada por padrão para tempdb e todos os bancos de dados do usuário a partir do SQL Server 2016 . Não podemos alterar as propriedades de tempdb, pois agora ele suporta apenas a opção Uniform Extent.
Para bancos de dados do usuário, podemos modificar esse parâmetro. Os bancos de dados mestre, modelo e msdb do sistema oferecem suporte a extensões mistas por padrão e também não podem ser alterados.
Para modificar os valores da propriedade de alocação de página mista para bancos de dados de usuários, use o script abaixo:
ALTER DATABASE Adventureworks SET MIXED_PAGE_ALLOCATION ON
-- OFF is the default behavior
GO
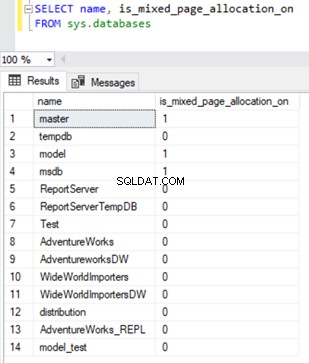
Para verificar a propriedade de alocação de página mista, podemos consultar o is_mixed_page_allocation_on coluna de sys.databases DMV com valor como 0, indicando alocação de página de extensão uniforme e 1 para indicar a alocação de página de extensão mista.
SELECT name, is_mixed_page_allocation_on
FROM sys.databases
Arquivos de dados TempDB crescendo para um valor enorme, exigindo redução do TempDB
No SQL Server 2014 ou versões anteriores, se os sinalizadores de rastreamento 1117 e 1118 não estiverem configurados corretamente junto com vários arquivos de dados criados para o banco de dados tempdb, alguns desses arquivos inevitavelmente ficarão enormes. Se isso acontecer, um DBA geralmente tenta reduzir os arquivos de dados tempdb. Mas é um impróprio abordagem para lidar com esse cenário.
Existem outras opções disponíveis para reduzir o tempdb.
Vamos considerar os comandos DBCC disponíveis para Shrink tempdb e os impactos de fazer essas operações.
DBCC SHRINKDATABASE
O DBCC SHRINKDATABASE O comando console funciona reduzindo o final dos Arquivos de Dados\Log .
Para reduzir com êxito um banco de dados, o comando precisa de espaço livre no final do arquivo. Se houver alguma transação ativa no final do arquivo, os arquivos do banco de dados não poderão ser reduzidos.
O impacto da execução de DBCC SHRINKDATABASE é que ele tentará liberar espaço livre disponível no final de cada arquivo de dados ou arquivo de log que possa ter sido reservado para o crescimento futuro dos dados da tabela. Portanto, a execução desse comando pode resultar em tamanhos de arquivo desiguais, levando a problemas de contenção de tempdb.
A sintaxe para reduzir um banco de dados do usuário, por exemplo, o banco de dados Adventureworks seria
DBCC SHRINKDATABASE (AdventureWorks, TRUNCATEONLY);DBCC SHRINKFILE
O DBCC SHRINKFILE O comando console funciona de maneira semelhante ao DBCC SHRINKDATABASE, mas reduz os dados do banco de dados ou arquivos de log especificados .
Se você identificar que um arquivo de dados tempdb específico é enorme, podemos tentar reduzir esse item específico usando DBCC SHRINKFILE conforme mostrado abaixo.
Tenha cuidado ao usar este comando no tempdb porque se um arquivo for reduzido para um valor inferior ou superior a outros arquivos de dados, esse arquivo de dados específico não será usado de forma eficaz. Ou será usado com mais frequência, levando a problemas de contenção de tempdb.
A sintaxe para executar a operação DBCC SHRINKFILE no arquivo de dados AdventureWorks para 1 GB (1024 MB) seria:
DBCC SHRINKFILE (AdventureWorks, 1024);
GO
DBCC DROPCLEANBUFFERS
Os DBCC DROPCLEANBUFFERS O comando console é usado para limpar todos os buffers limpos do conjunto de buffers e objetos columnstore do conjunto de objetos columnstore .
Basta executar o comando abaixo:
DBCC DROPCLEANBUFFERSDBCC FREEPROCCACHE
O DBCC FREEPROCCACHE comando limpa todo o cache do plano de execução do procedimento armazenado .
O Cache do Plano de Execução de Procedimento é usado pelo SQL Server para executar as mesmas chamadas de procedimento mais rapidamente. Após executar o DBCC FREEPROCCACHE, o Plan Cache é limpo. Assim, o SQL Server deve criar esse cache novamente quando o procedimento armazenado for executado na instância. Ele deixa um sério impacto negativo quando executado nas instâncias de banco de dados de produção.
Não é recomendado executar DBCC FREEPROCCACHE na instância do banco de dados de produção!
A sintaxe para executar DBCC FREEPROCCACHE está abaixo:
DBCC FREEPROCCACHEDBCC FREESESSIONCACHE
O DBCC FREESESSIONCACHE comando limpa o cache de conexão da consulta de distribuição da instância do SQL Server . Será útil quando houver muitas consultas distribuídas em execução em uma instância específica do SQL Server.
A sintaxe para executar DBCC FREESESSIONCACHE seria:
DBCC FREESESSIONCACHEDBCC FREESYSTEMCACHE
O DBCC FREESYSTEMCACHE comando limpa todas as entradas de cache não utilizadas de todo o cache . O SQL Server faz isso por padrão para disponibilizar mais memória para novas operações. No entanto, podemos executá-lo manualmente usando o comando abaixo:
DBCC FREESYSTEMCACHEComo sabemos, o tempdb armazena todos os objetos de usuário temporários ou objetos internos, incluindo Cache do Plano de Execução, dados do pool de buffers, Caches de Sessão e Caches do Sistema. Portanto, executar os 6 comandos DBCC acima ajudará a limpar os arquivos de dados tempdb que impedem o processo normal de redução.
Embora tenhamos seguido as etapas sobre como reduzir o tempdb por meio de várias abordagens, as práticas recomendadas recomendadas para lidar com o banco de dados tempdb estão listadas abaixo:
a. Reinicie o SQL Server Services, se possível, para recriar os arquivos de dados tempdb uniformemente. O impacto potencial seria perder todos os planos de execução e outras informações de cache discutidas acima.
b. Pré-cultive os arquivos de dados tempdb para um tamanho de arquivo enorme disponível na unidade que contém os arquivos de dados tempdb. Isso impedirá que o SQL Server aumente os tamanhos de arquivo de forma desigual nas versões do SQL Server 2014 e anteriores.
c. Se o SQL Server Services não puder ser reiniciado devido a RTO ou RPO, tente os comandos DBCC acima depois de entender claramente os impactos.
d. Reduzir o banco de dados tempdb ou os arquivos de dados não é uma abordagem recomendada e, portanto, nunca faça isso em seu ambiente de produção, a menos que não haja outras opções.
Conclusão
Aprendemos mais sobre o funcionamento interno do tempdb para que possamos configurar o tempdb para obter melhor desempenho, evitando problemas de contenção no tempdb. Também analisamos os problemas enfrentados com frequência no tempdb, as medidas disponíveis no SQL Server em várias versões e como lidar com isso com eficiência. Além disso, examinamos por que a redução do banco de dados tempdb ou dos arquivos de dados não é uma abordagem recomendada ao lidar com o banco de dados tempdb.