Testes de lançamento normalmente são uma das etapas de todo o processo de implantação. Você escreve o código, verifica como ele se comporta em um ambiente de teste e, finalmente, implanta o novo código na produção. Os bancos de dados são internos a qualquer tipo de aplicação e, portanto, é importante verificar como as alterações relacionadas ao banco de dados alteram a aplicação. É possível verificá-lo de duas maneiras; uma delas seria usar uma réplica dedicada. Vejamos como isso pode ser feito.
Obviamente, você não quer que esse processo seja manual - ele deve fazer parte dos processos de CI/CD da sua empresa. Dependendo do aplicativo, ambiente e processos exatos que você possui, você pode usar réplicas criadas ad hoc ou réplicas que sempre fazem parte do ambiente do banco de dados.
A maneira como o Galera Cluster funciona é que ele trata as alterações de esquema de uma maneira específica. É possível executar uma alteração de esquema em um único nó no cluster, mas é complicado, pois não suporta todas as alterações de esquema possíveis e afetará a produção se algo der errado. Tal nó teria que ser totalmente reconstruído usando SST, o que significa que um dos nós Galera restantes terá que atuar como um doador e transferir todos os seus dados pela rede.
Uma alternativa será usar uma réplica ou até mesmo todo Galera Cluster adicional atuando como réplica. Obviamente, o processo precisa ser automatizado para ser conectado ao pipeline de desenvolvimento. Há muitas maneiras de fazer isso:scripts ou várias ferramentas de orquestração de infraestrutura, como Ansible, Chef, Puppet ou Salt stack. Não vamos descrevê-los em detalhes, mas gostaríamos que você mostrasse as etapas necessárias para que todo o processo funcione corretamente, e deixaremos a implementação em uma das ferramentas para você.
Automatizando testes de lançamento
Em primeiro lugar, queremos poder implantar um novo banco de dados facilmente. Ele deve ser provisionado com os dados recentes, e isso pode ser feito de várias maneiras - você pode copiar os dados do banco de dados de produção para o servidor de teste; é a coisa mais simples de fazer. Como alternativa, você pode usar o backup mais recente - essa abordagem tem benefícios adicionais de testar a restauração do backup. A verificação de backup é obrigatória em qualquer tipo de implantação séria, e a reconstrução de configurações de teste é uma ótima maneira de verificar novamente se o processo de restauração funciona. Também ajuda a cronometrar o processo de restauração - saber quanto tempo leva para restaurar o backup ajuda a avaliar corretamente a situação em um cenário de recuperação de desastres.
Depois que os dados forem provisionados no banco de dados, convém configurar esse nó como uma réplica de seu cluster primário. Tem seus prós e contras. Se você pudesse reexecutar todo o seu tráfego para o nó autônomo, seria perfeito - nesse caso, não há necessidade de configurar a replicação. Alguns dos balanceadores de carga, como o ProxySQL, permitem espelhar o tráfego e enviar sua cópia para outro local. Por outro lado, a replicação é a próxima melhor coisa. Sim, você não pode executar gravações diretamente nesse nó, o que força você a planejar como executará novamente as consultas, pois a abordagem mais simples de apenas responder não funcionará. Por outro lado, todas as escritas eventualmente serão executadas via thread SQL, então você só precisa planejar como lidar com consultas SELECT.
Dependendo da mudança exata, você pode querer testar o processo de mudança de esquema. As alterações de esquema são bastante comuns de serem executadas e podem ter um impacto sério no desempenho do banco de dados. Assim, é importante verificá-los antes de aplicá-los à produção. Queremos ver o tempo necessário para executar a alteração e verificar se a alteração pode ser aplicada em nós separadamente ou é necessária para realizar a alteração em toda a topologia ao mesmo tempo. Isso nos dirá qual processo devemos usar para uma determinada mudança de esquema.
Usando o ClusterControl para melhorar a automação dos testes de versão
ClusterControl vem com um conjunto de recursos que podem ser usados para ajudá-lo a automatizar os testes de lançamento. Vamos dar uma olhada no que ele oferece. Para deixar claro, os recursos que vamos mostrar estão disponíveis de duas maneiras. A maneira mais simples é usar a interface do usuário, mas é desnecessário o que você deseja fazer se tiver automação em mente. Há mais duas maneiras de fazer isso:Interface de linha de comando para ClusterControl e API RPC. Em ambos os casos, os trabalhos podem ser acionados a partir de scripts externos, permitindo que você os conecte aos seus processos de CI/CD existentes. Isso também economizará muito tempo, pois implantar o cluster pode ser apenas uma questão de executar um comando em vez de configurá-lo manualmente.
Implantando o cluster de teste
Em primeiro lugar, o ClusterControl vem com uma opção para implantar um novo cluster e provisioná-lo com os dados do banco de dados existente. Esse recurso sozinho permite que você implemente facilmente o provisionamento do servidor de teste.
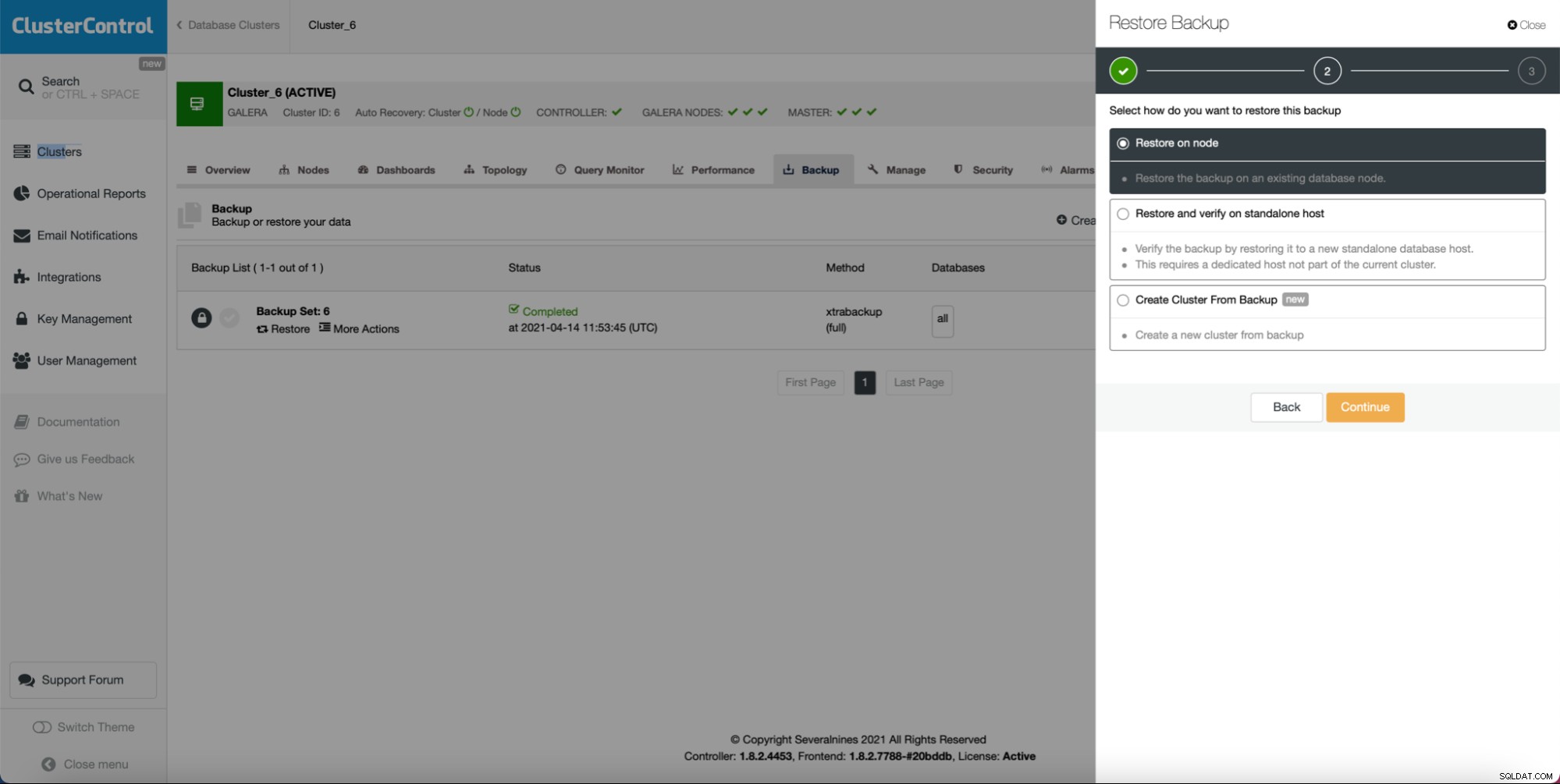
Como você pode ver, contanto que você tenha um backup criado, você pode criar um novo cluster e provisioná-lo usando os dados do backup:
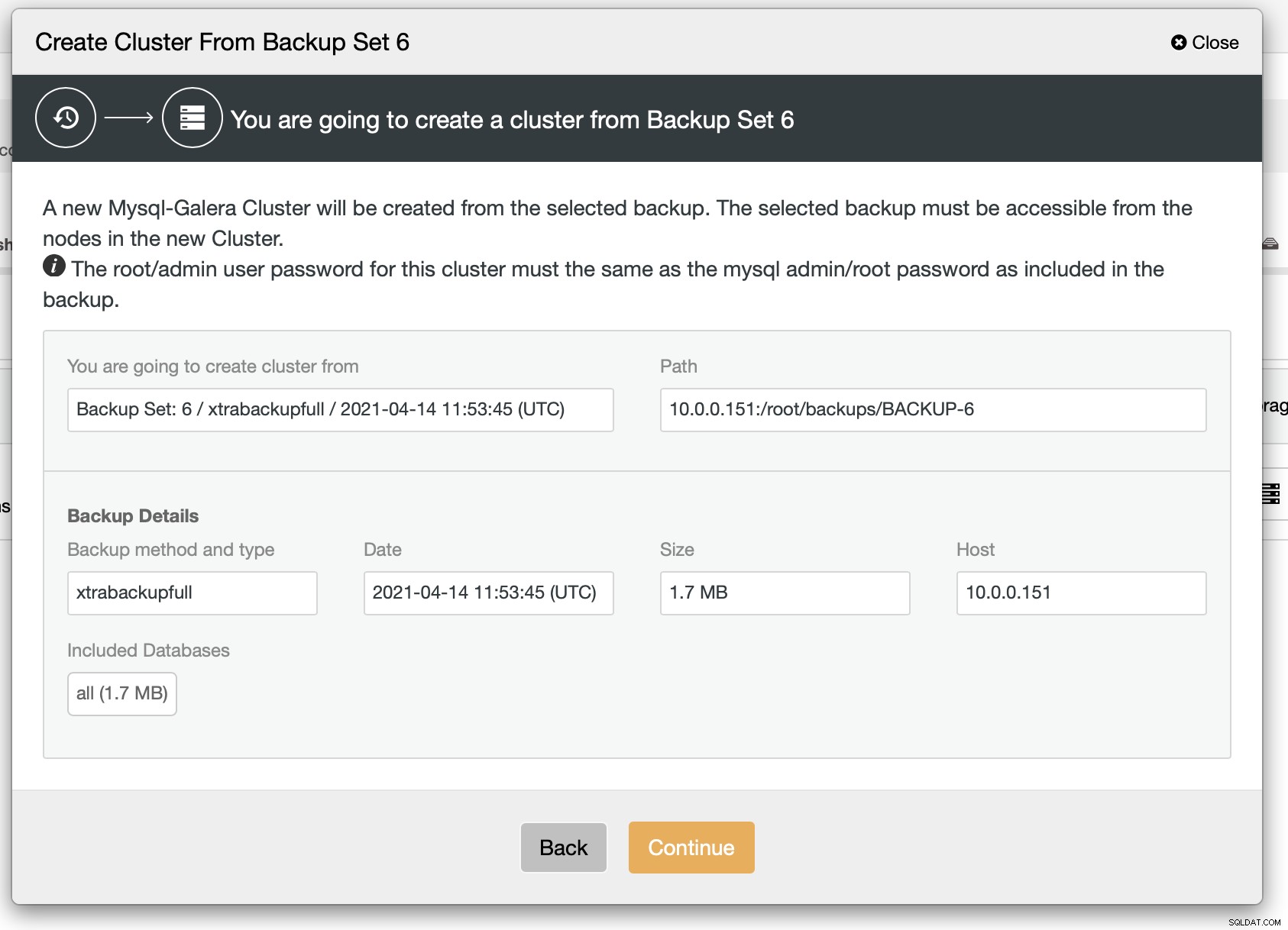
Como podemos ver, há um breve resumo do que acontecerá. Se você clicar em Continuar, você prosseguirá.
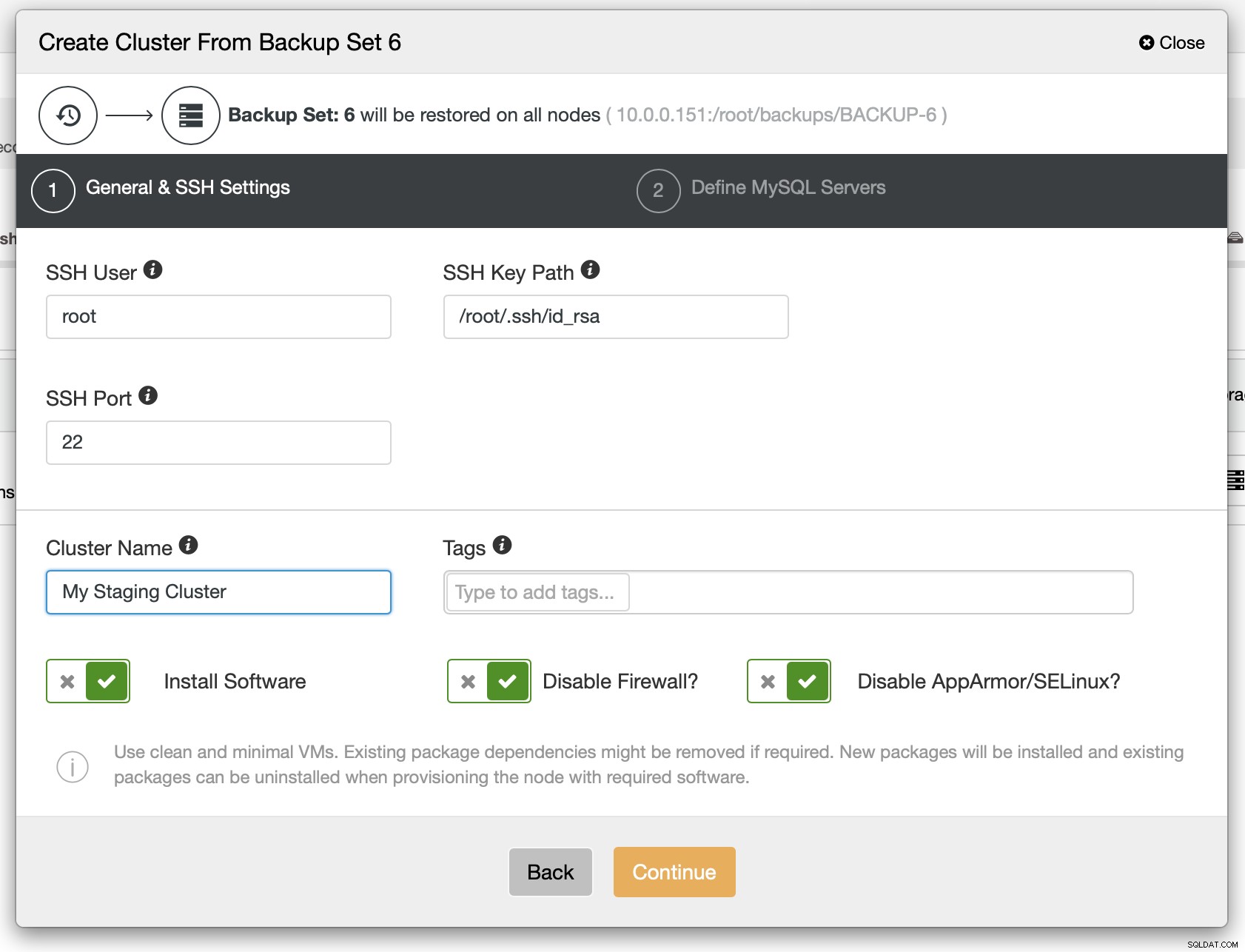
Como próxima etapa, você deve definir a conectividade SSH - ela deve estar em vigor antes que o ClusterControl possa implantar os nós.
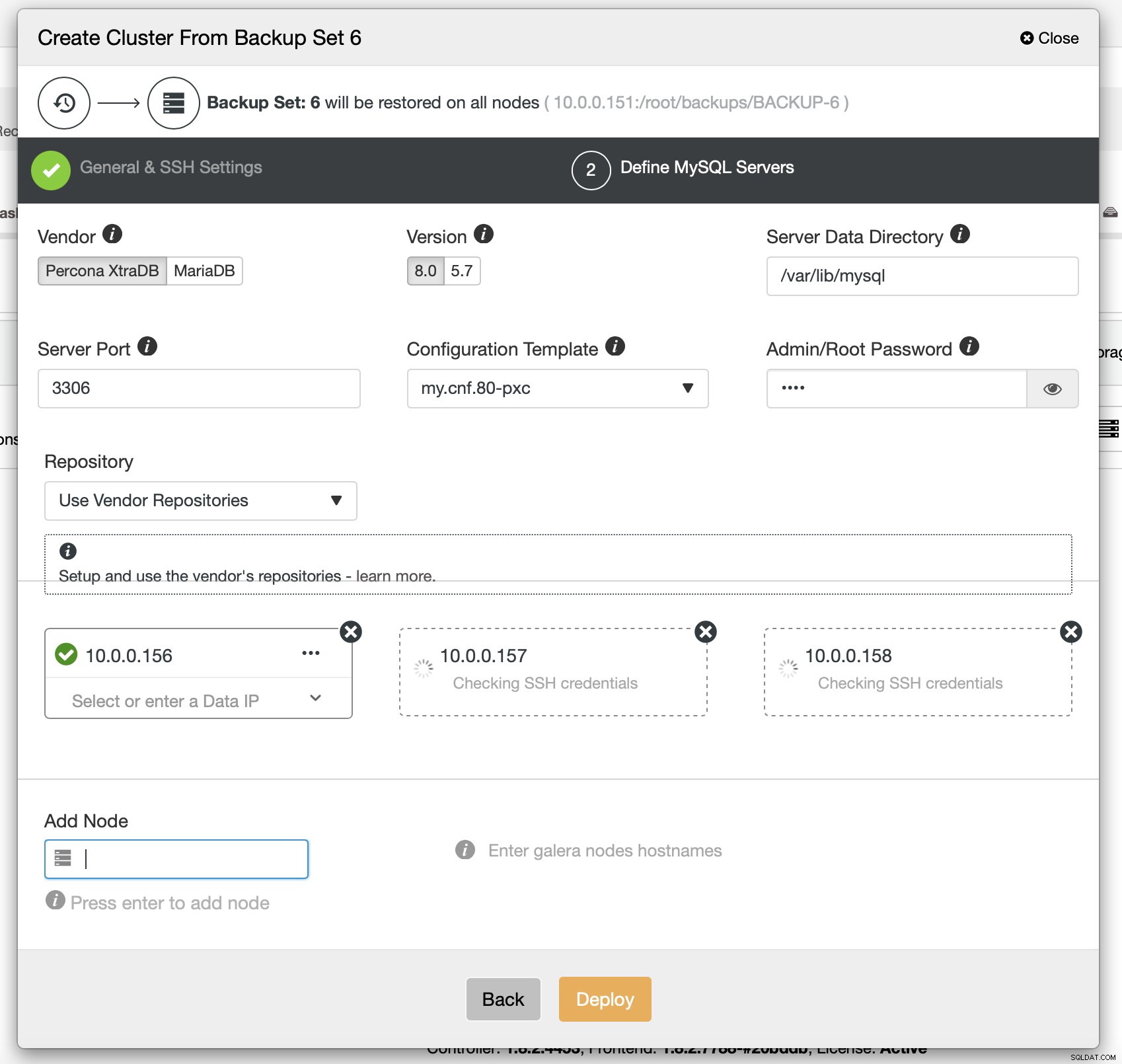
Finalmente, você deve escolher (entre outros) o fornecedor, a versão e os nomes de host dos nós que deseja usar no cluster. É só isso.
O comando CLI que faria a mesma coisa se parece com isso:
s9s cluster --create --cluster-type=galera --nodes="10.0.0.156;10.0.0.157;10.0.0.158" --vendor=percona --cluster-name=PXC --provider-version=8.0 --os-user=root --os-key-file=/root/.ssh/id_rsa --backup-id=6Configurando o ProxySQL para espelhar o tráfego
Se tivermos um cluster implantado, podemos enviar o tráfego de produção para ele para verificar como o novo esquema trata o tráfego existente. Uma maneira de fazer isso é usando ProxySQL.
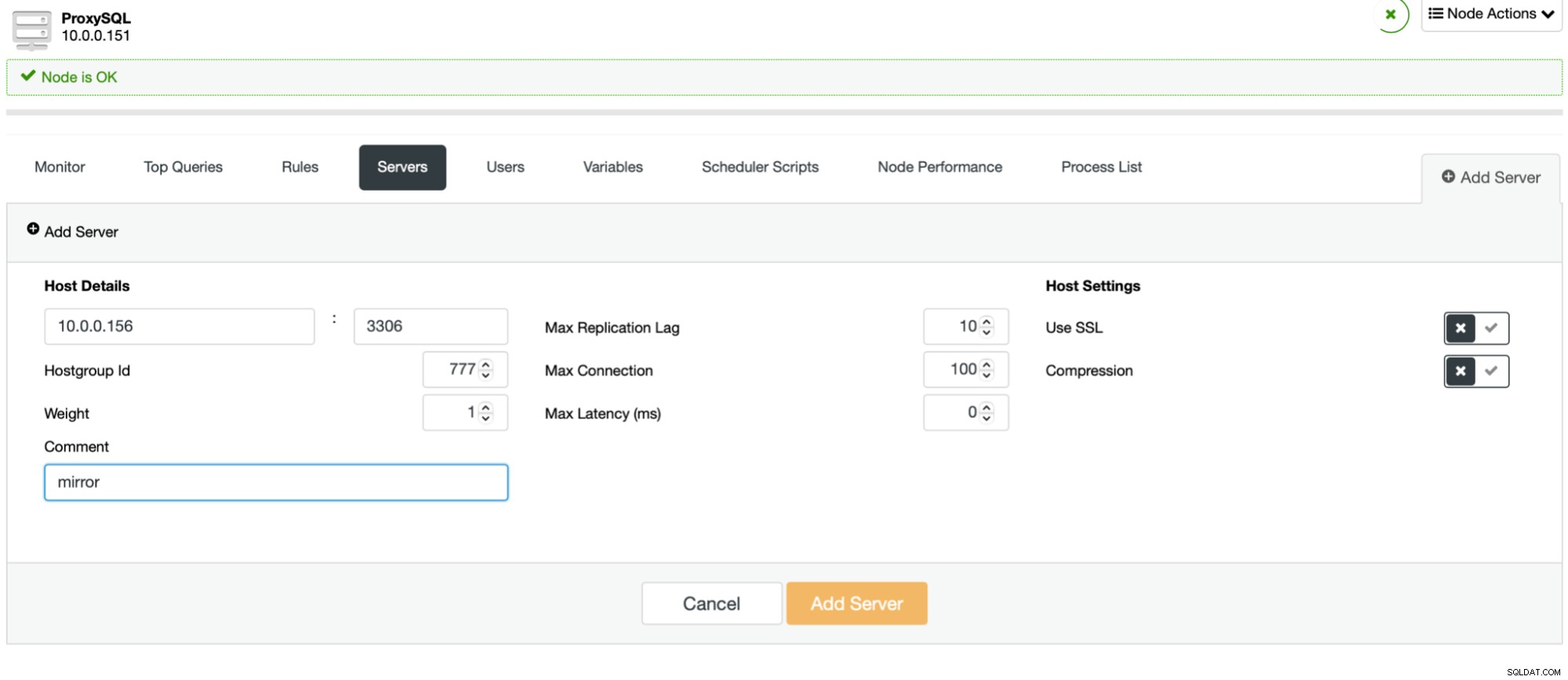
O processo é fácil. Primeiro, você deve adicionar os nós ao ProxySQL. Eles devem pertencer a um hostgroup separado que ainda não está em uso. Certifique-se de que o usuário do monitor ProxySQL possa acessá-los.
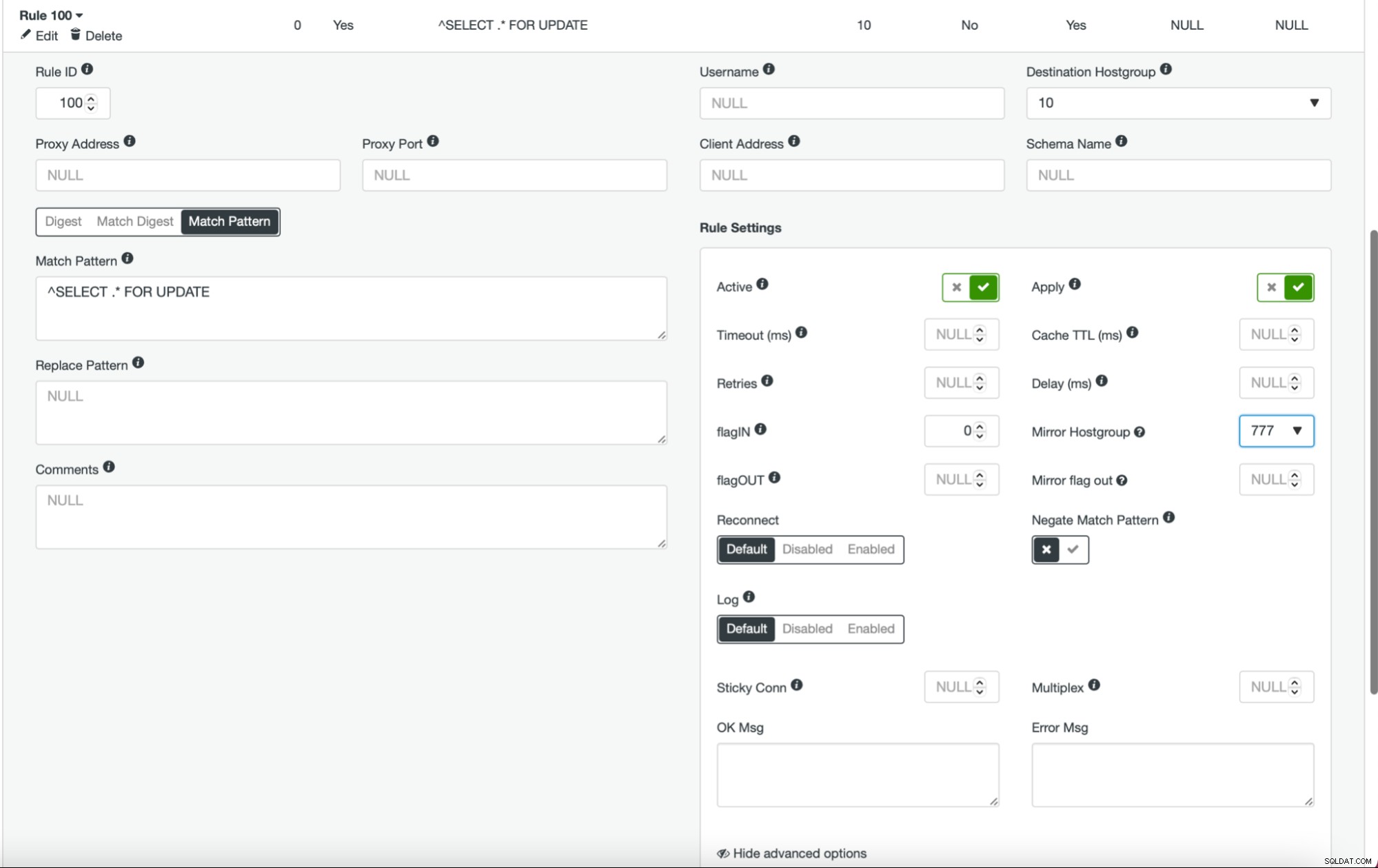
Uma vez feito isso e você tem todos (ou alguns) de seus nós configurados no hostgroup, você pode editar as regras de consulta e definir o Mirror Hostgroup (está disponível nas opções avançadas). Se você quiser fazer isso para todo o tráfego, provavelmente desejará editar todas as suas regras de consulta dessa maneira. Se você deseja espelhar apenas consultas SELECT, deve editar as regras de consulta apropriadas. Depois que isso for feito, seu cluster de preparo deve começar a receber tráfego de produção.
Implantando cluster como escravo
Como discutimos anteriormente, uma solução alternativa seria criar um novo cluster que atuaria como uma réplica da configuração existente. Com tal abordagem podemos ter todas as escritas testadas automaticamente, usando a replicação. SELECTs podem ser testados usando a abordagem que descrevemos acima - espelhamento por meio de ProxySQL.
A implantação de um cluster escravo é bastante direta.
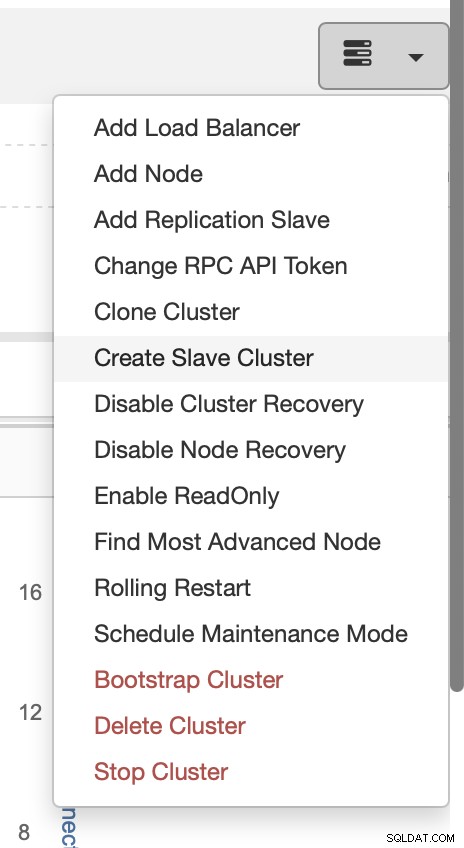
Escolha a tarefa Criar cluster escravo.
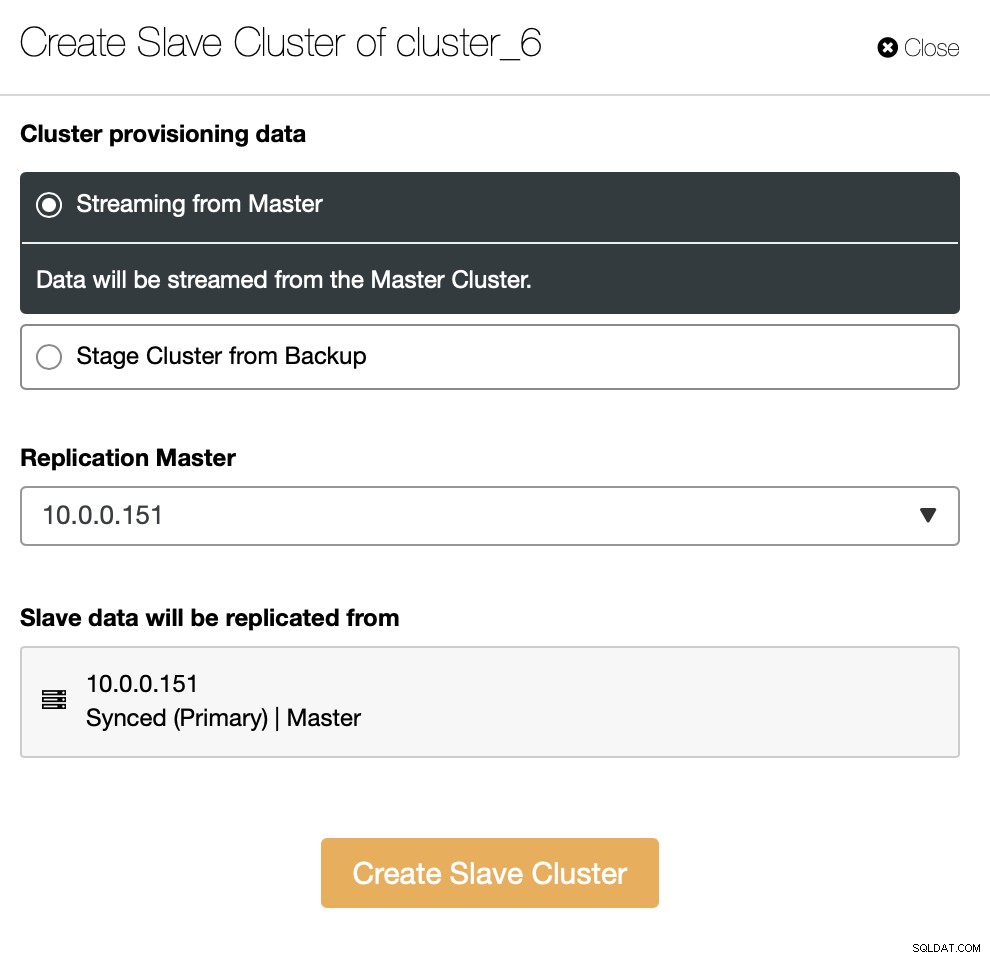
Você precisa decidir como deseja que a replicação seja definida. Você pode transferir todos os dados do mestre para os novos nós.
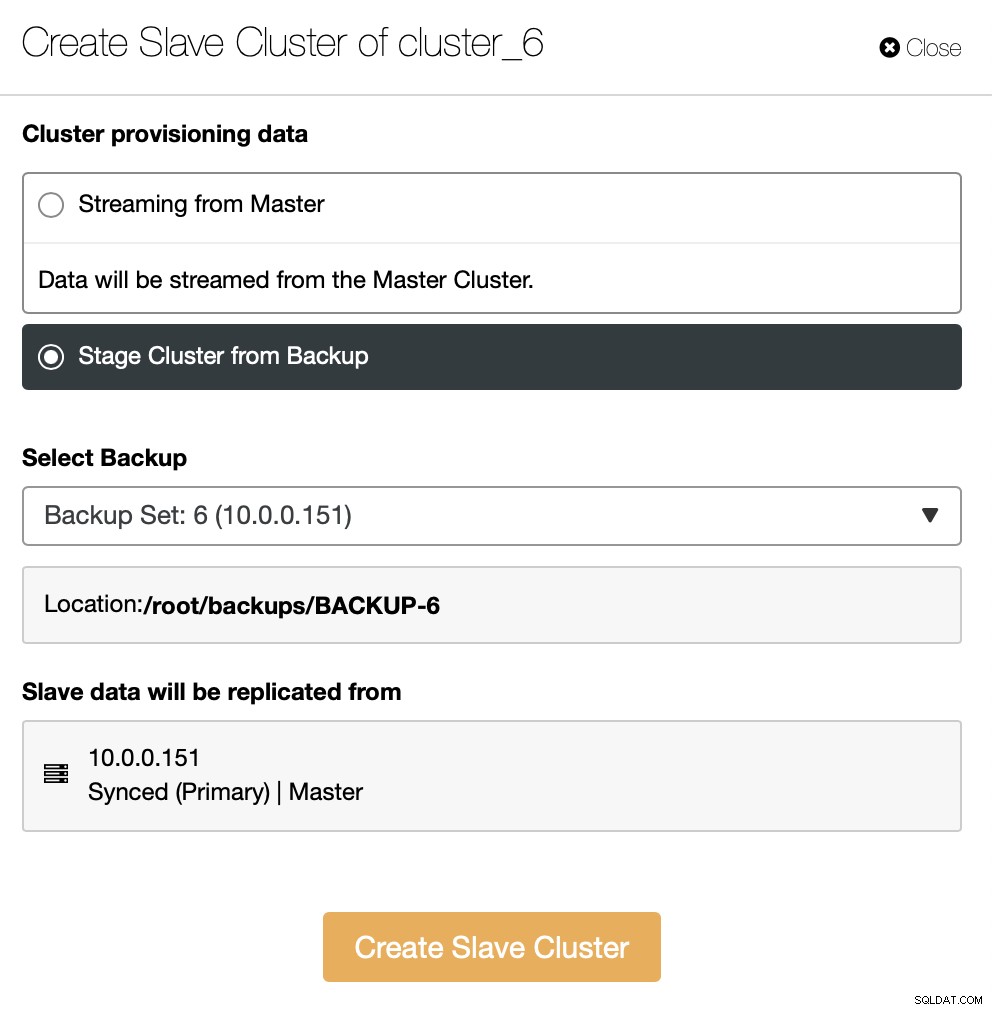
Como alternativa, você pode usar o backup existente para provisionar o novo cluster. Isso ajudará a reduzir a carga de trabalho no nó mestre - em vez de transferir todos os dados, apenas as transações que foram executadas entre o momento em que o backup foi criado e o momento em que a replicação foi configurada terão que ser transferidas.
O resto é seguir o assistente de implantação padrão, definindo conectividade SSH, versão, fornecedor, hosts e assim por diante. Depois de implantado, você verá o cluster na lista.
A solução alternativa para a interface do usuário é fazer isso via RPC.
{
"command": "create_cluster",
"job_data": {
"cluster_name": "",
"cluster_type": "galera",
"company_id": null,
"config_template": "my.cnf.80-pxc",
"data_center": 0,
"datadir": "/var/lib/mysql",
"db_password": "pass",
"db_user": "root",
"disable_firewall": true,
"disable_selinux": true,
"enable_mysql_uninstall": true,
"generate_token": true,
"install_software": true,
"port": "3306",
"remote_cluster_id": 6,
"software_package": "",
"ssh_keyfile": "/root/.ssh/id_rsa",
"ssh_port": "22",
"ssh_user": "root",
"sudo_password": "",
"type": "mysql",
"user_id": 5,
"vendor": "percona",
"version": "8.0",
"nodes": [
{
"hostname": "10.0.0.155",
"hostname_data": "10.0.0.155",
"hostname_internal": "",
"port": "3306"
},
{
"hostname": "10.0.0.159",
"hostname_data": "10.0.0.159",
"hostname_internal": "",
"port": "3306"
},
{
"hostname": "10.0.0.160",
"hostname_data": "10.0.0.160",
"hostname_internal": "",
"port": "3306"
}
],
"with_tags": []
}
}Avançando
Se você estiver interessado em aprender mais sobre as maneiras de integrar seus processos com o ClusterControl, gostaríamos de encaminhá-lo para a documentação, onde temos uma seção inteira sobre desenvolvimento de soluções onde o ClusterControl desempenha um papel papel importante:
https://docs.severalnines.com/docs/clustercontrol/developer-guide/cmon-rpc/
https://docs.severalnines.com/docs/clustercontrol/user-guide-cli/
Esperamos que você tenha achado este breve blog informativo e útil. Se você tiver alguma dúvida relacionada à integração do ClusterControl em seu ambiente, entre em contato conosco e faremos o possível para ajudá-lo.