Os serviços do AWS PostgreSQL estão sob o guarda-chuva do RDS, que é a oferta de DaaS da Amazon para todos os mecanismos de banco de dados conhecidos.
Os serviços de banco de dados gerenciados oferecem certas vantagens que são atraentes para o cliente que busca independência da manutenção da infraestrutura e configurações altamente disponíveis. Como sempre, não existe uma solução de tamanho único. As opções atualmente disponíveis estão destacadas abaixo:
Aurora PostgreSQL
A página de perguntas frequentes do Amazon Aurora fornece detalhes importantes que precisam ser considerados antes de mergulhar no produto. Por exemplo, aprendemos que a camada de armazenamento é virtualizada e fica em um sistema de armazenamento virtualizado proprietário com backup em SSD.
Preços
Em termos de preços, deve-se observar que o Aurora PostgreSQL não está disponível no nível gratuito da AWS.
Compatibilidade
A mesma página de perguntas frequentes deixa claro que a Amazon não reivindica 100% de compatibilidade com o PostgreSQL. A maioria (grifo meu) dos aplicativos ficará bem, por exemplo. o sabor do AWS PostgreSQL é compatível com fio com PostgreSQL 9.6. Como resultado, o Dissector PostgreSQL do Wireshark funcionará bem.
Desempenho
O desempenho também está vinculado ao tipo de instância, por exemplo, o número máximo de conexões é configurado por padrão com base no tamanho da instância.
Também importante quando se trata de compatibilidade é o tamanho da página que foi mantido em 8KiB, que é o tamanho de página padrão do PostgreSQL. Por falar em páginas, vale a pena citar o FAQ:“Ao contrário dos mecanismos de banco de dados tradicionais, o Amazon Aurora nunca envia páginas de banco de dados modificadas para a camada de armazenamento, resultando em mais economia de consumo de E/S. ” Isso é possível porque a Amazon mudou a forma como o cache da página é gerenciado, permitindo que ele permaneça na memória em caso de falha do banco de dados. Esse recurso também beneficia a reinicialização do banco de dados após uma falha, permitindo que a recuperação ocorra muito mais rapidamente do que no método tradicional de repetição dos logs.
De acordo com as perguntas frequentes mencionadas acima, o Aurora PostgreSQL oferece três vezes o desempenho do PostgreSQL nas operações SELECT e UPDATE. De acordo com o white paper do PostgreSQL Benchmark da Amazon, as ferramentas usadas para medir o desempenho foram pgbench e sysbench. Notável é a dependência de desempenho do tipo de instância, seleção de região e desempenho da rede. Quer saber por que INSERT não é mencionado? Isso ocorre porque a conformidade do PostgreSQL ACID (o “C”) exige que um registro atualizado seja criado usando uma exclusão seguida de uma inserção.
Para aproveitar ao máximo as melhorias de desempenho, a Amazon recomenda que os aplicativos sejam projetados para interagir com o banco de dados usando grandes números de consultas e transações simultâneas . Este fator importante, muitas vezes é negligenciado levando a um mau desempenho atribuído à implementação.
Limites
Existem algumas limitações a serem consideradas ao planejar a migração:
-
As páginas_grandes não podem ser modificadas, mas estão ativadas por padrão:
template1=> select aurora_version(); aurora_version ---------------- 1.0.11 (1 row) template1=> show huge_pages ; huge_pages ------------ on (1 row) - pg_hba não pode ser usado porque requer uma reinicialização do servidor. Como observação lateral, deve ser um erro de digitação na documentação da Amazon, pois o PostgreSQL só precisa ser recarregado. Em vez de confiar no pg_hba, os administradores precisarão usar os grupos de segurança da AWS e o PostgreSQL GRANT.
- A granularidade de PITR é de 5 minutos.
- A replicação entre regiões não está disponível no momento para o PostgreSQL.
- O tamanho máximo das tabelas é 64 TiB
- Até 15 réplicas de leitura
Escalabilidade
Atualmente, a escalabilidade da instância do banco de dados é um processo manual, que pode ser feito por meio do Console AWS ou CLI, embora o dimensionamento automático esteja em andamento, no entanto, de acordo com as perguntas frequentes do Amazon Aurora, ele estará disponível apenas para MySQL.
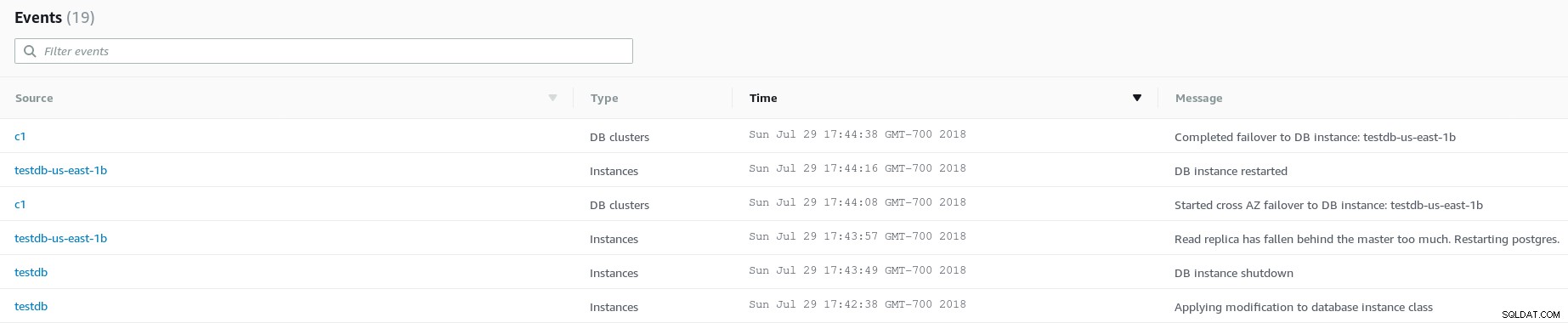 Recursos de computação de dimensionamento de log de eventos
Recursos de computação de dimensionamento de log de eventos Para escalar horizontalmente, os aplicativos devem aproveitar as APIs do AWS SDK, por exemplo, para obter failover rápido.
Alta disponibilidade
Passando para a alta disponibilidade, em caso de falha do nó primário, o Aurora PostgreSQL fornece um endpoint de cluster como um registro DNS A, que é atualizado automaticamente internamente para apontar para a réplica selecionada para se tornar mestre.
Backups
Vale ressaltar que se o banco de dados for excluído, quaisquer instantâneos de backup manual serão mantidos, enquanto os instantâneos automáticos serão removidos.
Replicação
Como as réplicas compartilham o mesmo armazenamento subjacente que a instância primária, o atraso de replicação está, em teoria, na faixa de milissegundos.
A Amazon recomenda ler réplicas para reduzir a duração do failover. Com uma réplica de leitura em espera, o processo de failover leva cerca de 30 segundos, enquanto sem uma réplica, espera-se até 15 minutos.
Outra boa notícia é que a replicação lógica também é suportada, conforme mostrado na página 22.
Embora as perguntas frequentes do Amazon Aurora não forneçam detalhes sobre a replicação como no MySQL, as práticas recomendadas do Aurora PostgreSQL fornecem uma consulta útil para verificar o status da replicação:
select server_id, session_id, highest_lsn_rcvd,
cur_replay_latency_in_usec, now(), last_update_timestamp from
aurora_replica_status();A consulta acima produz:
-[ RECORD 1 ]--------------+-------------------------------------
server_id | testdb
session_id | 9e268c62-9392-11e8-87fc-a926fa8340fe
highest_lsn_rcvd | 46640889
cur_replay_latency_in_usec | 8830
now | 2018-07-29 20:14:55.434701-07
last_update_timestamp | 2018-07-29 20:14:54-07
-[ RECORD 2 ]--------------+-------------------------------------
server_id | testdb-us-east-1b
session_id | MASTER_SESSION_ID
highest_lsn_rcvd |
cur_replay_latency_in_usec |
now | 2018-07-29 20:14:55.434701-07
last_update_timestamp | 2018-07-29 20:14:55-07Como a replicação é um tópico tão importante, valeu a pena configurar o teste pgbench conforme descrito no white paper de referência mencionado acima:
[example@sqldat.com ~]$ whoami
ec2-user
[example@sqldat.com ~]$ tail -n 2 .bashrc
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/pgsql/lib
export PATH=$PATH:/usr/local/pgsql/bin/
[example@sqldat.com ~]$ which pgbench
/usr/local/pgsql/bin/pgbench
[example@sqldat.com ~]$ pgbench --version
pgbench (PostgreSQL) 9.6.8Dica: Evite digitação desnecessária criando um arquivo pgpass e exportando o host, banco de dados e variáveis de ambiente do usuário, por exemplo:
[example@sqldat.com ~]# tail -n 3 ~/.bashrc export
PGUSER=dbadmin
export PGHOST=c1.cluster-ctfirtyhadgr.us-east-1.rds.amazonaws.com
export PGDATABASE=template1
[example@sqldat.com ~]# cat ~/.pgpass
*:*:*:dbadmin:passwordExecute o comando de inicialização de dados:
[example@sqldat.com ~]$ pgbench -i --fillfactor=90 --scale=10000 postgresEnquanto a inicialização de dados estiver em execução, capture o atraso de replicação usando o SQL acima chamado no script a seguir:
while : ; do
psql -t -q \
-c 'select server_id, session_id, highest_lsn_rcvd,
cur_replay_latency_in_usec, now(), last_update_timestamp
from aurora_replica_status();' postgres
sleep 1
doneFiltrando a saída do log de tela por meio do seguinte comando:
[example@sqldat.com ~]# awk -F '|' '{print $4,$5,$6}' screenlog.2 | sort -k1,1 -n | tail
513116 2018-07-30 04:30:44.394729+00 2018-07-30 04:30:43+00
529294 2018-07-30 04:20:54.261741+00 2018-07-30 04:20:53+00
544139 2018-07-30 04:41:57.538566+00 2018-07-30 04:41:57+00
1001902 2018-07-30 04:42:54.80136+00 2018-07-30 04:42:53+00
2376951 2018-07-30 04:38:06.621681+00 2018-07-30 04:38:06+00
2376951 2018-07-30 04:38:07.672919+00 2018-07-30 04:38:07+00
5365719 2018-07-30 04:36:51.608983+00 2018-07-30 04:36:50+00
5365719 2018-07-30 04:36:52.912731+00 2018-07-30 04:36:51+00
6308586 2018-07-30 04:45:22.951966+00 2018-07-30 04:45:21+00
8210986 2018-07-30 04:46:14.575385+00 2018-07-30 04:46:13+00Acontece que a replicação atrasou até 8 segundos!
Em uma nota relacionada, a métrica AuroraReplicaLagMaximum do AWS CloudWatch não concorda com os resultados do comando SQL acima. Eu gostaria de saber o porquê, então o feedback é muito apreciado.
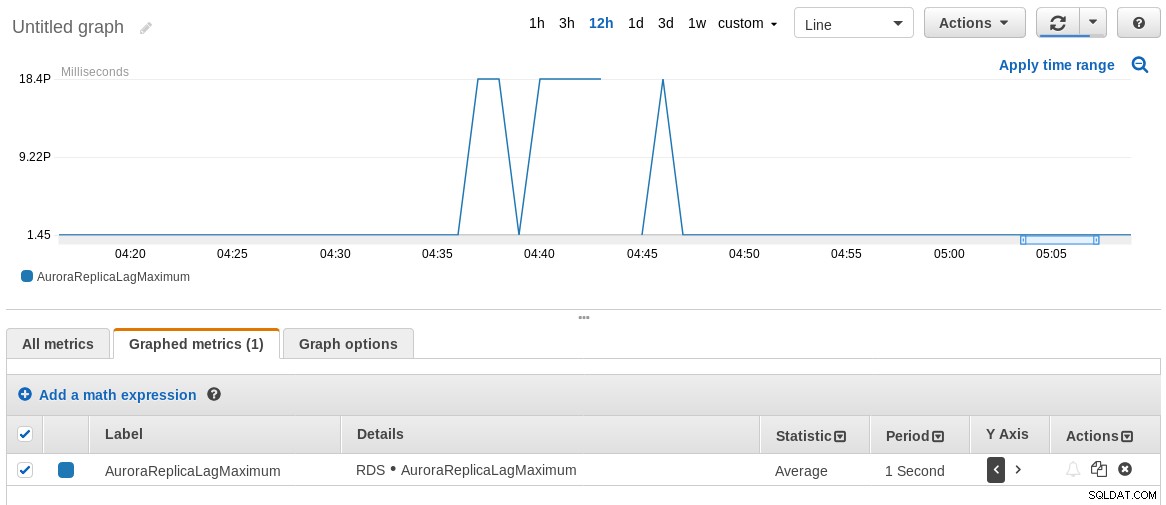 Gráfico de atraso de réplica máximo do RDS CloudWatch
Gráfico de atraso de réplica máximo do RDS CloudWatch Segurança
-
A criptografia está disponível e deve ser habilitada quando o banco de dados é criado, pois não pode ser alterado posteriormente.
Solução de problemas
Esta pequena seção é uma parte importante Assegure-se de que o work_mem do PostgreSQL esteja ajustado adequadamente para que as operações de classificação não gravem dados no disco.
Configuração
Basta seguir o assistente de configuração no Console AWS:
-
Abra o Amazon RDS console de gerenciamento.
 console de gerenciamento RDS
console de gerenciamento RDS -
Selecione Amazon Aurora e PostgreSQL edição.
 Assistente do Aurora PostgreSQL
Assistente do Aurora PostgreSQL -
Especifique os detalhes do banco de dados e observe as limitações de senha do Aurora PostgreSQL:
Master Password must be at least eight characters long, as in "mypassword". Can be any printable ASCII character except "/", """, or "@".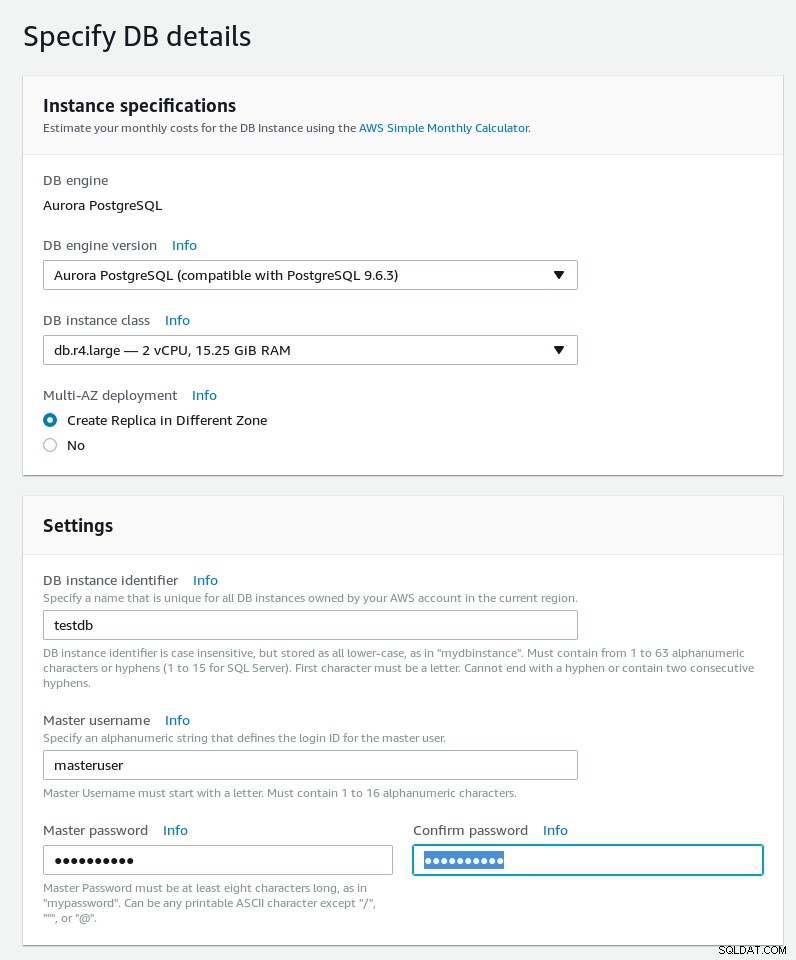 Detalhes do banco de dados do assistente Aurora PostgreSQL
Detalhes do banco de dados do assistente Aurora PostgreSQL -
Configure as opções do banco de dados:
- Até o momento, apenas o PostgreSQL 9.6 está disponível. Use o PostgreSQL no Amazon RDS se precisar de suporte para versões mais recentes, incluindo visualizações beta.
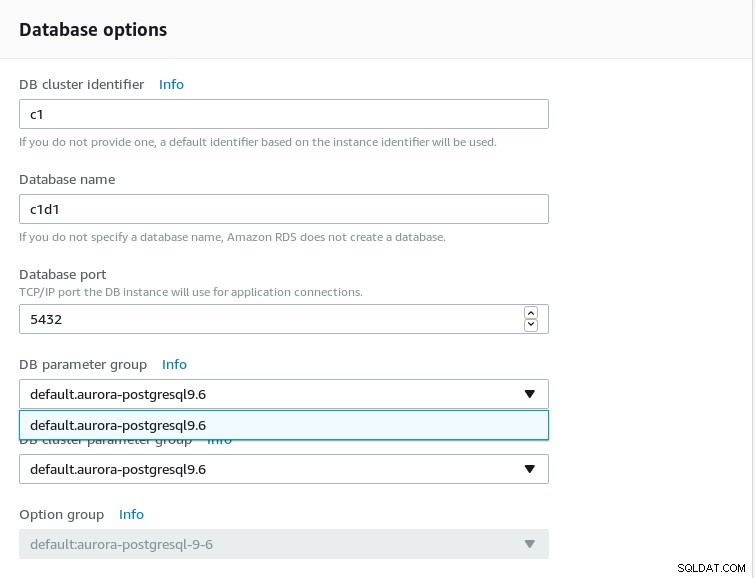
-
Configure a prioridade de failover e selecione o número de réplicas.
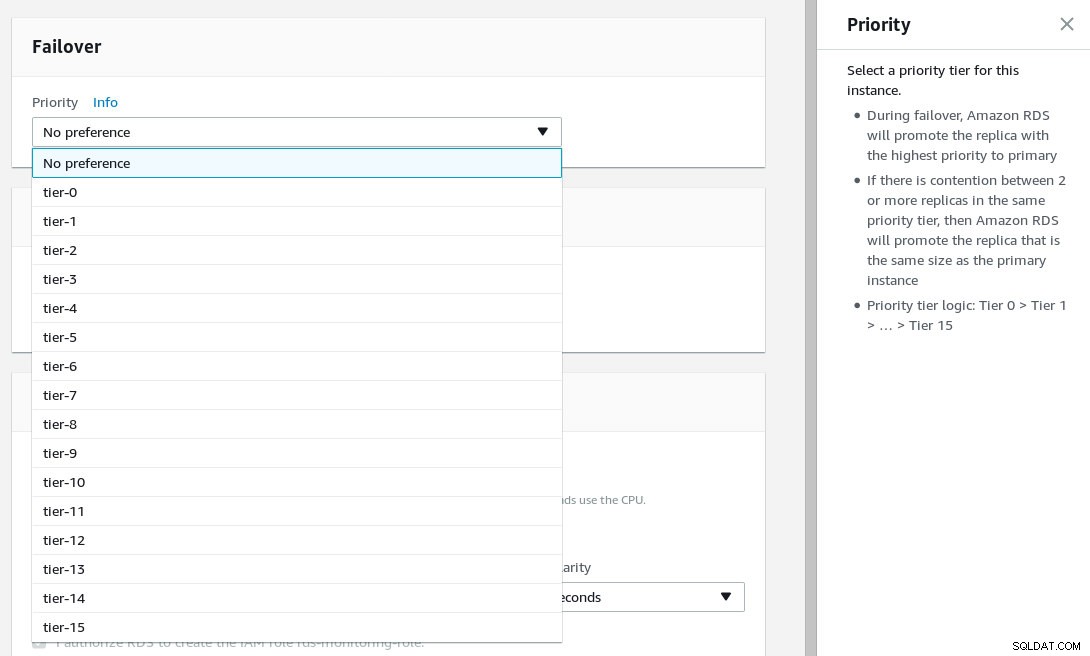 Descrição da foto
Descrição da foto -
Defina a retenção de backup (o máximo é 35 dias).
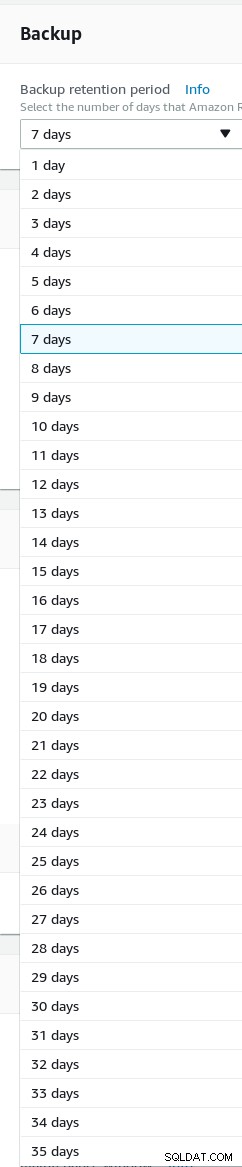 Retenção de backup do assistente Aurora PostgreSQL
Retenção de backup do assistente Aurora PostgreSQL -
Selecione o cronograma de manutenção. Atualizações automáticas de versões secundárias estão disponíveis, mas é importante verificar com o suporte da AWS se a programação de patches pode ou não ser acelerada caso o projeto PostgreSQL libere atualizações urgentes. Por exemplo, levou mais de dois meses para a AWS enviar as atualizações de 2018-05-10.
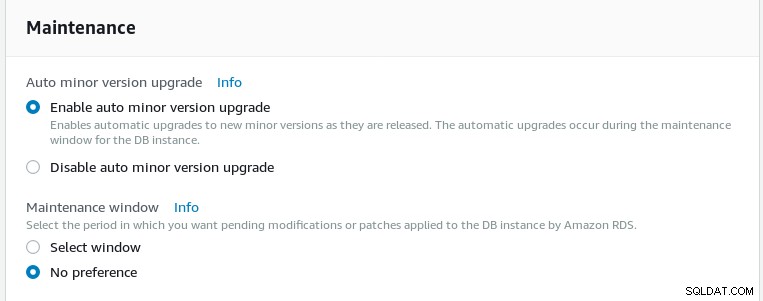 Cronograma de manutenção do assistente Aurora PostgreSQL
Cronograma de manutenção do assistente Aurora PostgreSQL -
Se o banco de dados foi criado com sucesso, um link para instruções sobre como se conectar a ele será exibido:
 Configuração do assistente do Aurora PostgreSQL concluída
Configuração do assistente do Aurora PostgreSQL concluída
Conectando ao banco de dados
Revise as instruções detalhadas das opções de conexões disponíveis, com base na configuração da infraestrutura. No cenário mais simples, a conexão é feita por meio de uma instância pública do EC2.
Observação:o cliente deve ser compatível com PostgreSQL 9.6.3 ou superior.
[example@sqldat.com ~]# psql -U dbadmin -h c1.cluster-ctfirtyhadgr.us-east-1.rds.amazonaws.com template1
Password for user dbadmin:
psql (9.6.8, server 9.6.3)
SSL connection (protocol: TLSv1.2, cipher: DHE-RSA-AES256-GCM-SHA384, bits: 256, compression: off)
Type "help" for help.Monitoramento
A Amazon fornece várias métricas para monitorar o banco de dados, um exemplo abaixo mostrando as métricas da instância:
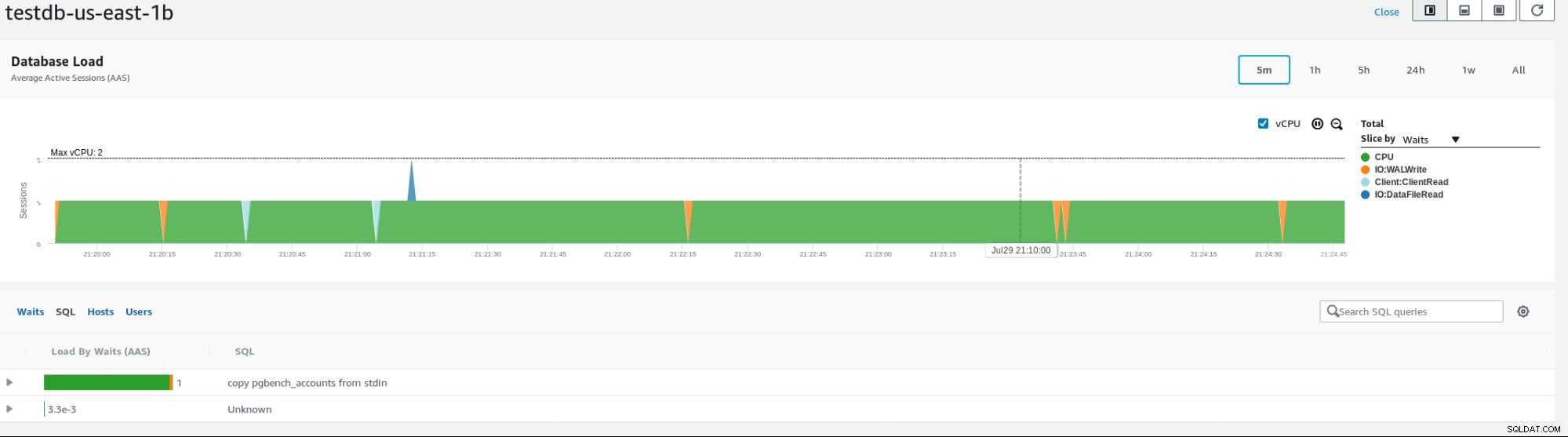 Métricas de instância RDS Baixe o whitepaper hoje PostgreSQL Management &Automation with ClusterControlSaiba mais sobre o que você precisa saber para implantar, monitorar, gerencie e dimensione o PostgreSQLBaixe o whitepaper
Métricas de instância RDS Baixe o whitepaper hoje PostgreSQL Management &Automation with ClusterControlSaiba mais sobre o que você precisa saber para implantar, monitorar, gerencie e dimensione o PostgreSQLBaixe o whitepaper RDS para PostgreSQL
Esta é uma oferta que permite mais granularidade em termos de opções de configuração. Por exemplo, ao contrário do Aurora que usa um sistema de armazenamento proprietário, o RDS oferece armazenamento configurável usando volumes EBS que podem ser SSD de uso geral (GP2), IOPS provisionadas ou magnético (não recomendado).
Para atender a grandes instalações, que exigem personalização não disponível na oferta Aurora, a Amazon lançou recentemente as recomendações de práticas recomendadas, disponíveis apenas para RDS.
A alta disponibilidade deve ser configurada manualmente (ou automatizada usando qualquer uma das ferramentas conhecidas da AWS) e é recomendável configurar uma implantação Multi-AZ.
A replicação é implementada usando a replicação nativa do PostgreSQL.
Existem alguns limites para instâncias de banco de dados PostgreSQL que precisam ser considerados.
Com as notas acima em mente, aqui está um passo a passo para configurar um ambiente RDS PostgreSQL Multi-AZ:
-
No Console de gerenciamento do RDS inicie o assistente
 Assistente RDS PostgreSQL
Assistente RDS PostgreSQL -
Escolha entre uma configuração de produção e de desenvolvimento.
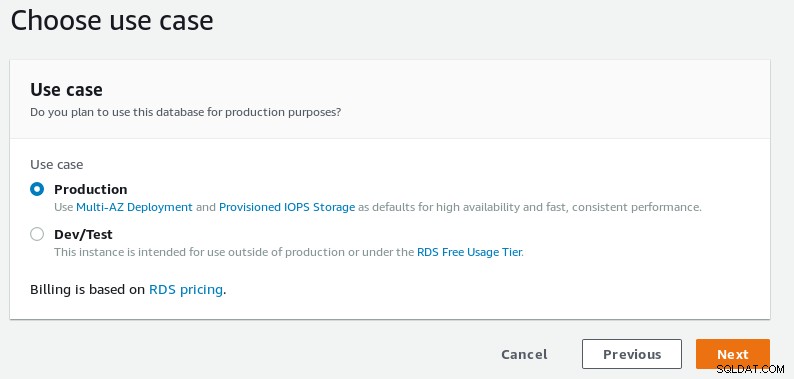 Seleção de caso de uso do banco de dados do assistente RDS PostgreSQL
Seleção de caso de uso do banco de dados do assistente RDS PostgreSQL -
Insira os detalhes sobre seu novo cluster de banco de dados.
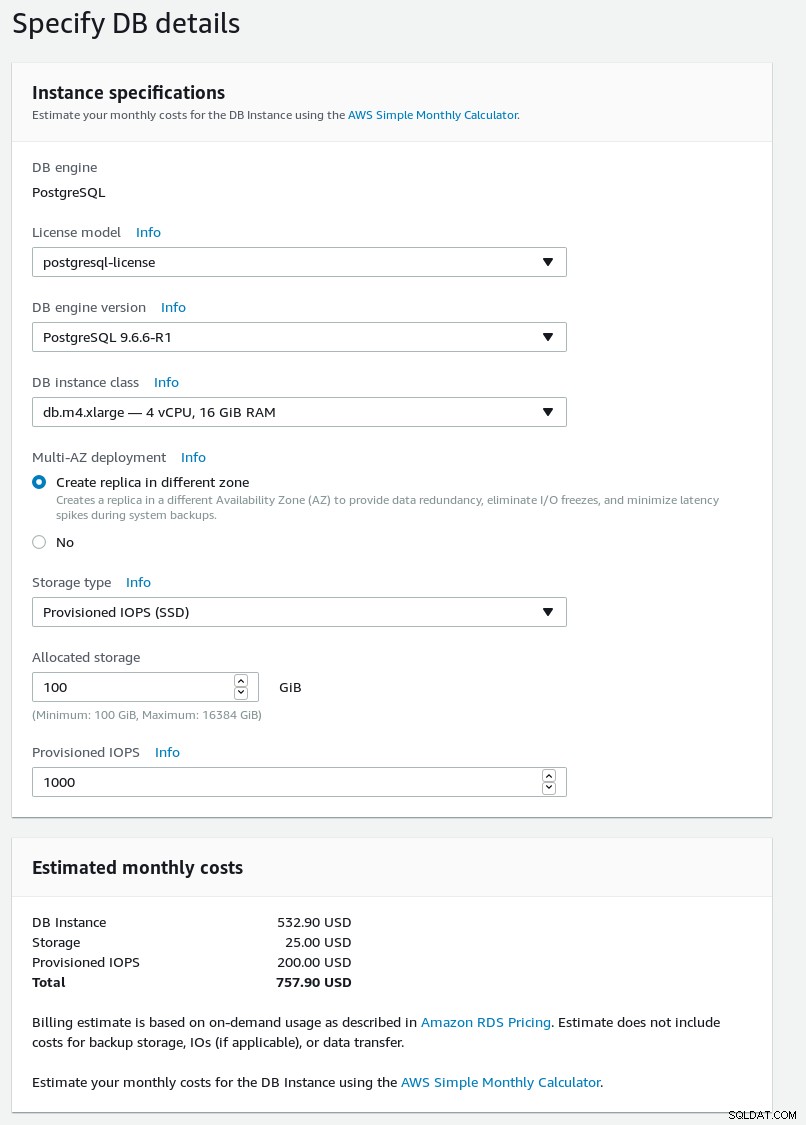 Detalhes do banco de dados do assistente RDS PostgreSQL
Detalhes do banco de dados do assistente RDS PostgreSQL 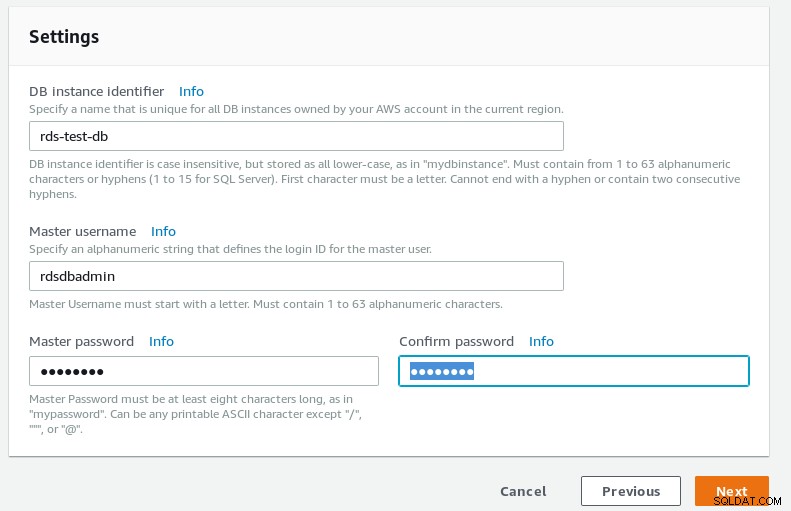 Configurações do banco de dados do assistente RDS PostgreSQL
Configurações do banco de dados do assistente RDS PostgreSQL -
Na próxima página, configure a programação de rede, segurança e manutenção:
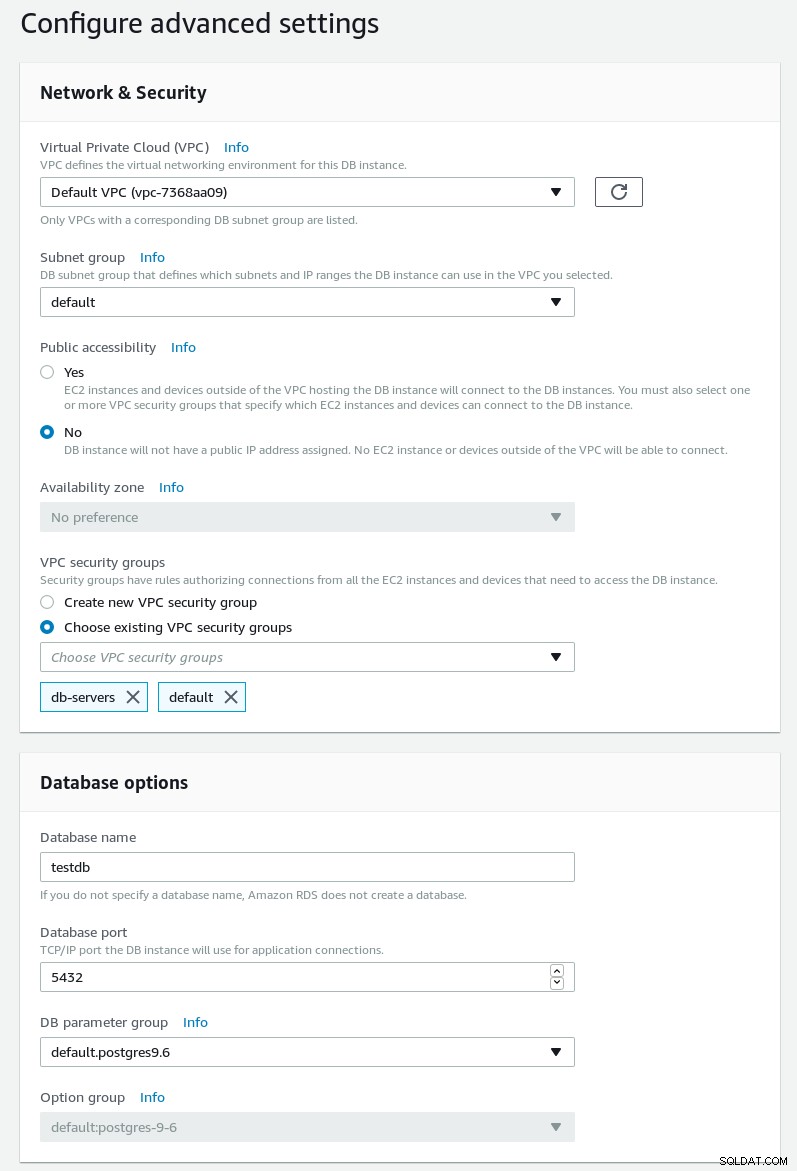 Configurações avançadas do assistente RDS PostgreSQL
Configurações avançadas do assistente RDS PostgreSQL 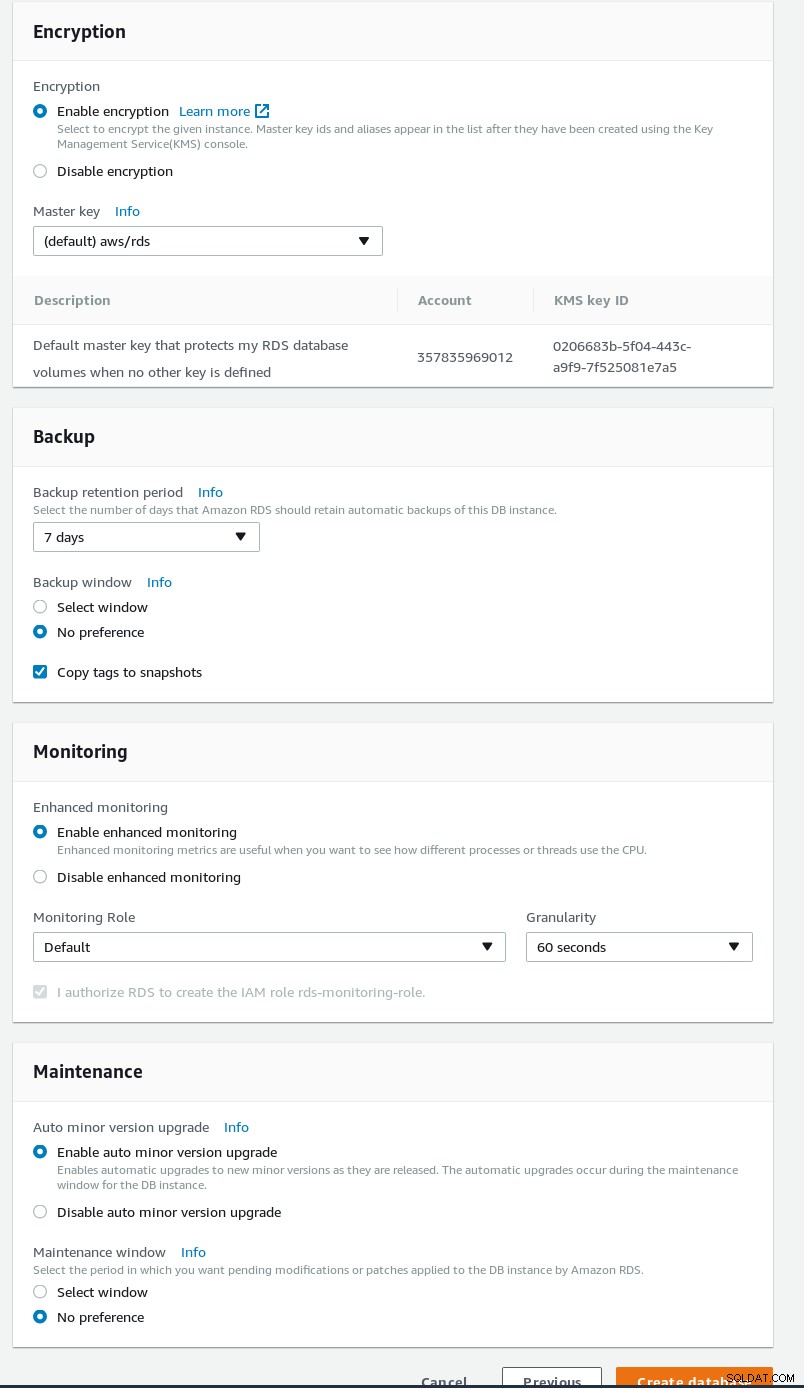 Segurança e manutenção do assistente RDS PostgreSQL
Segurança e manutenção do assistente RDS PostgreSQL
Conclusão
O Amazon RDS Services for PostgreSQL inclui o RDS PostgreSQL e o Aurora PostgreSQL, ambos sendo ofertas de DaaS gerenciadas. Embalado com muitos recursos e armazenamento de back-end sólido, eles têm algumas limitações em relação à configuração tradicional, no entanto, com um planejamento cuidadoso, essas ofertas podem fornecer uma relação custo-funcionalidade bem equilibrada. O Amazon RDS for PostgreSQL é voltado para usuários que precisam de mais opções para configurar seus ambientes e geralmente é mais caro. A maioria dos usuários se beneficiará ao iniciar com o Aurora PostgreSQL e trabalhar em configurações mais complexas.



