Como o postgres é muito mais sensato que o MySQL, não há muitos "truques" para relatar;-)
O manual tem algumas boas dicas de desempenho.
Algumas outras coisas relacionadas ao desempenho a serem lembradas:
- Verifique se o autovacuum está ativado
- Certifique-se de ter passado pelo seu postgres.conf (tamanho efetivo do cache, buffers compartilhados, memória de trabalho ... muitas opções para ajustar).
- Use pgpool ou pgbouncer para manter suas conexões de banco de dados "reais" no mínimo
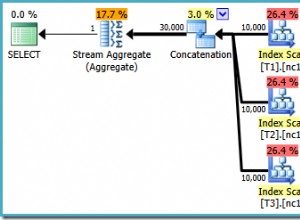
- Saiba como EXPLAIN e EXPLAIN ANALYZE funcionam. Aprenda a ler a saída.
- CLUSTER classifica os dados no disco de acordo com um índice. Pode melhorar drasticamente o desempenho de tabelas grandes (principalmente) somente leitura. O clustering é uma operação única:quando a tabela é atualizada posteriormente, as alterações não são agrupadas.
Aqui estão algumas coisas que achei úteis que não são relacionadas à configuração ou ao desempenho em si.
Para ver o que está acontecendo no momento:
select * from pg_stat_activity;
Pesquisar funções diversas:
select * from pg_proc WHERE proname ~* '^pg_.*'
Encontre o tamanho do banco de dados:
select pg_database_size('postgres');
select pg_size_pretty(pg_database_size('postgres'));
Encontre o tamanho de todos os bancos de dados:
select datname, pg_size_pretty(pg_database_size(datname)) as size
from pg_database;
Encontre o tamanho das tabelas e índices:
select pg_size_pretty(pg_relation_size('public.customer'));
Ou, para listar todas as tabelas e índices (provavelmente mais fácil visualizar isso):
select schemaname, relname,
pg_size_pretty(pg_relation_size(schemaname || '.' || relname)) as size
from (select schemaname, relname, 'table' as type
from pg_stat_user_tables
union all
select schemaname, relname, 'index' as type
from pg_stat_user_indexes) x;
Ah, e você pode aninhar transações, reverter transações parciais++
test=# begin;
BEGIN
test=# select count(*) from customer where name='test';
count
-------
0
(1 row)
test=# insert into customer (name) values ('test');
INSERT 0 1
test=# savepoint foo;
SAVEPOINT
test=# update customer set name='john';
UPDATE 3
test=# rollback to savepoint foo;
ROLLBACK
test=# commit;
COMMIT
test=# select count(*) from customer where name='test';
count
-------
1
(1 row)