Ansioso para aprender tudo sobre o Hadoop Cluster?
O Hadoop é uma estrutura de software para analisar e armazenar grandes quantidades de dados em clusters de hardware comum. Neste artigo, estudaremos um cluster Hadoop.
Vamos começar com uma introdução ao Cluster.
O que é um cluster?
Um cluster é uma coleção de nós. Os nós nada mais são do que um ponto de conexão/interseção dentro de uma rede.
Um cluster de computadores é uma coleção de computadores conectados a uma rede, capazes de se comunicar entre si e funcionam como um único sistema.
O que é cluster Hadoop?
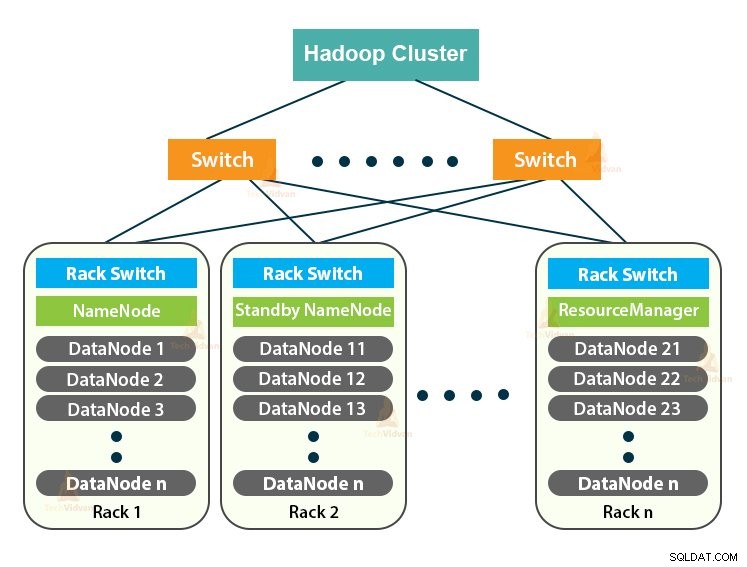
O Hadoop Cluster é apenas um cluster de computador usado para manipular uma grande quantidade de dados de maneira distribuída.
É um cluster computacional projetado para armazenar e analisar grandes quantidades de dados não estruturados ou estruturados em um ambiente de computação distribuído.
Os clusters do Hadoop também são conhecidos como sistemas sem compartilhamento porque nada é compartilhado entre os nós do cluster, exceto a largura de banda da rede. Isso diminui a latência de processamento.
Assim, quando há necessidade de processar consultas sobre uma grande quantidade de dados, a latência em todo o cluster é minimizada.
Vamos agora estudar a Arquitetura do Cluster Hadoop.
Arquitetura do cluster Hadoop
O cluster Hadoop segue uma arquitetura mestre-escravo. Ele consiste no nó mestre, nos nós escravos e no nó cliente.
1. Mestre em cluster Hadoop
Master in the Hadoop Cluster é uma máquina de alta potência com alta configuração de memória e CPU. Os dois daemons que são NameNode e ResourceManager são executados no nó mestre.
a. Funções de NameNode
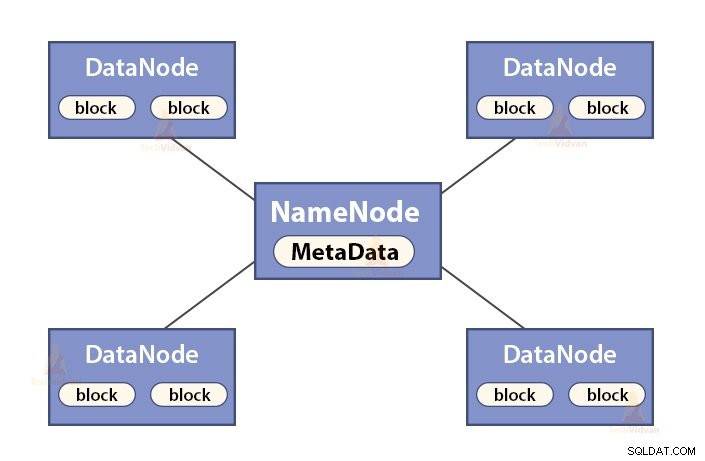
NameNode é um nó mestre no Hadoop HDFS . NameNode gerencia o namespace do sistema de arquivos. Ele armazena metadados do sistema de arquivos na memória para recuperação rápida. Portanto, ele deve ser configurado em máquinas de ponta.
As funções do NameNode são:
- Gerencia o namespace do sistema de arquivos
- Armazena metadados sobre blocos de um arquivo, localização de blocos, permissões etc.
- Executa as operações de namespace do sistema de arquivos, como abrir, fechar, renomear arquivos e diretórios, etc.
- Ele mantém e gerencia o DataNode.
b. Funções do Gerenciador de Recursos
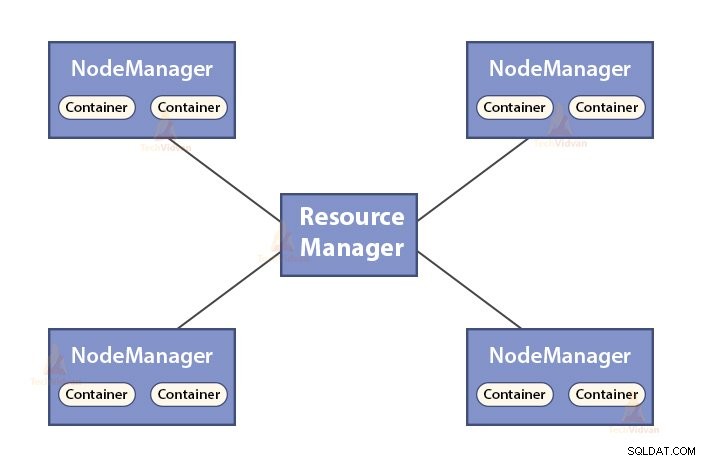
- ResourceManager é o daemon mestre do YARN.
- O ResourceManager arbitra os recursos entre todos os aplicativos do sistema.
- Ele monitora os nós ativos e mortos no cluster.
2. Escravos no cluster do Hadoop
Os escravos no cluster do Hadoop são hardwares de baixo custo. Os dois daemons que são DataNodes e YARN NodeManagers são executados nos nós escravos.
a. Funções de DataNodes
- DataNodes armazena os dados de negócios reais. Ele armazena os blocos de um arquivo.
- Ele executa a criação, exclusão e replicação de blocos com base nas instruções do NameNode.
- O DataNode é responsável por atender às operações de leitura/gravação do cliente.
b. Funções do NodeManager
- NodeManager é o daemon escravo do YARN.
- É responsável pelos contêineres, monitorando seu uso de recursos (como CPU, disco, memória, rede) e reportando o mesmo ao ResourceManager.
- O NodeManager também verifica a integridade do nó em que está sendo executado.
3. Nó cliente no cluster Hadoop
Os nós clientes no Hadoop não são nós mestres nem nós escravos. Eles têm o Hadoop instalado com todas as configurações de cluster.
Funções dos nós do cliente
- Os nós do cliente carregam dados no cluster do Hadoop.
- Ele envia jobs do MapReduce, descrevendo como esses dados devem ser processados.
- Recupere os resultados do trabalho após a conclusão do processamento.
Podemos dimensionar o cluster do Hadoop adicionando mais nós. Isso torna o Hadoop linearmente escalonável . Com cada adição de nó, obtemos um aumento correspondente na taxa de transferência. Se tivermos 'n' nós, adicionar 1 nó fornece (1/n) poder de computação adicional.
Cluster Hadoop de nó único VS Cluster Hadoop de vários nós
1. Cluster Hadoop de nó único
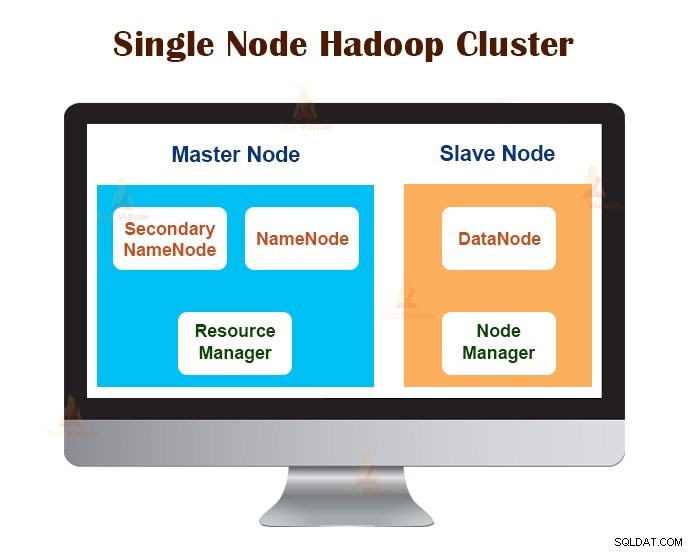
O cluster Hadoop de nó único é implantado em uma única máquina. Todos os daemons como NameNode, DataNode, ResourceManager, NodeManager são executados na mesma máquina/host.
Em uma configuração de cluster de nó único, tudo é executado em uma única instância JVM. O usuário do Hadoop não precisou fazer nenhuma configuração, exceto definir a variável JAVA_HOME.
O fator de replicação padrão para um cluster Hadoop de nó único é sempre 1.
2. Cluster Hadoop de vários nós
O cluster Hadoop de vários nós é implantado em várias máquinas. Todos os daemons no cluster Hadoop de vários nós estão ativos e executados em diferentes máquinas/hosts.
Um cluster Hadoop de vários nós segue a arquitetura mestre-escravo. Os daemons Namenode e ResourceManager são executados nos nós mestres, que são computadores de última geração.
Os daemons DataNodes e NodeManagers são executados nos nós escravos (nós de trabalho), que são hardwares de baixo custo.
No cluster Hadoop de vários nós, as máquinas escravas podem estar presentes em qualquer local, independentemente da localização física do servidor mestre.
Protocolos de comunicação usados no cluster Hadoop
Os protocolos de comunicação HDFS são colocados em camadas na parte superior do protocolo TCP/IP. Um cliente estabelece uma conexão com o NameNode através da porta TCP configurável na máquina NameNode.
O cluster do Hadoop estabelece uma conexão com o cliente por meio do ClientProtocol. Além disso, o DataNode conversa com o NameNode usando o protocolo DataNode.
A abstração Remote Procedure Call (RPC) envolve o protocolo Client Protocol e o protocolo DataNode. Por design, NameNode não inicia nenhum RPC. Ele responde apenas às solicitações RPC emitidas por clientes ou DataNodes.
Práticas recomendadas para criar cluster Hadoop
O desempenho de um cluster Hadoop depende de vários fatores com base nos recursos de hardware bem dimensionados que usam CPU, memória, largura de banda de rede, disco rígido e outras camadas de software bem configuradas.
Construir um cluster Hadoop não é uma tarefa trivial. Isso requer a consideração de vários fatores, como escolher o hardware certo, dimensionar os clusters do Hadoop e configurar o cluster do Hadoop.
Vejamos agora cada um em detalhes.
1. Escolhendo o hardware certo para o cluster Hadoop
Muitas organizações, ao configurar a infraestrutura Hadoop, estão em uma situação difícil, pois não estão cientes do tipo de máquina que precisam comprar para configurar um ambiente Hadoop otimizado e a configuração ideal que devem usar.
Para escolher o hardware certo para o Hadoop Cluster, deve-se considerar os seguintes pontos:
- O volume de dados que o cluster processará.
- O tipo de cargas de trabalho com as quais o cluster lidará (limite de CPU, limite de E/S).
- Metodologia de armazenamento de dados, como contêineres de dados, técnicas de compactação de dados usadas, se houver.
- Uma política de retenção de dados, ou seja, por quanto tempo queremos manter os dados antes de eliminá-los.
2. Dimensionando o cluster do Hadoop
Para determinar o tamanho do cluster do Hadoop, o volume de dados que os usuários do Hadoop processarão no cluster do Hadoop deve ser uma consideração importante.
Ao conhecer o volume de dados a serem processados, ajuda a decidir quantos nós serão necessários para processar os dados de forma eficiente e a capacidade de memória necessária para cada nó. Deve haver um equilíbrio entre o desempenho e o custo do hardware aprovado.
3. Configurando o cluster do Hadoop
Encontrar a configuração ideal para o cluster Hadoop não é uma tarefa fácil. A estrutura do Hadoop deve ser adaptada ao cluster em execução e também ao trabalho.
A melhor maneira de decidir a configuração ideal para o cluster do Hadoop é executar os trabalhos do Hadoop com a configuração padrão disponível para obter uma linha de base. Depois disso, podemos analisar os arquivos de log do histórico de tarefas para ver se há alguma deficiência de recursos ou se o tempo gasto para executar as tarefas é maior do que o esperado.
Se for assim, altere a configuração. Repetir o mesmo processo pode ajustar a configuração do cluster Hadoop que melhor se adapta aos requisitos de negócios.
O desempenho do cluster Hadoop depende muito dos recursos alocados aos daemons. Para contextos de dados pequenos e médios, o Hadoop reserva um núcleo de CPU em cada DataNode, enquanto que, para conjuntos de dados longos, ele aloca 2 núcleos de CPU em cada DataNode para daemons HDFS e MapReduce.
Gerenciamento de cluster do Hadoop
Ao implantar o cluster do Hadoop em produção, fica claro que ele deve ser dimensionado em todas as dimensões que são volume, variedade e velocidade.
Vários recursos que ele deve possuir para estar pronto para produção são:disponibilidade ininterrupta, robustez, capacidade de gerenciamento e desempenho. O gerenciamento do Hadoop Cluster é a principal faceta da iniciativa de big data.
A melhor ferramenta para gerenciamento de cluster Hadoop deve ter os seguintes recursos:-
- Deve garantir alta disponibilidade 24 horas por dia, 7 dias por semana, provisionamento de recursos, segurança diversificada, gerenciamento de carga de trabalho, monitoramento de integridade, otimização de desempenho. Além disso, ele precisa fornecer agendamento de trabalhos, gerenciamento de políticas, backup e recuperação em um ou mais nós.
- Implemente a alta disponibilidade redundante do HDFS NameNode com balanceamento de carga, hot standbys, ressincronização e failover automático.
- Aplicar controles baseados em políticas que impedem que qualquer aplicativo obtenha uma parcela desproporcional de recursos em um cluster Hadoop já maximizado.
- Realizar testes de regressão para gerenciar a implantação de qualquer camada de software em clusters Hadoop. Isso é para garantir que quaisquer tarefas ou dados não sofram falhas ou encontrem gargalos nas operações diárias.
Benefícios do cluster Hadoop
Os vários benefícios fornecidos pelo Hadoop Cluster são:
1. Escalável
Os clusters do Hadoop são escaláveis. Podemos adicionar qualquer número de nós ao cluster Hadoop sem qualquer tempo de inatividade e sem nenhum esforço extra. Com cada adição de nó, obtemos um aumento correspondente na taxa de transferência.
2. Robustez
O cluster Hadoop é mais conhecido por seu armazenamento confiável. Ele pode armazenar dados de forma confiável, mesmo em casos como falha de DataNode, falha de NameNode e partição de rede. O DataNode envia periodicamente um sinal de pulsação para o NameNode.
Na partição de rede, um conjunto de DataNodes é separado do NameNode devido ao qual NameNode não recebe nenhuma pulsação desses DataNodes. NameNode então considera esses DataNodes como mortos e não encaminha nenhuma solicitação de E/S para eles.
Além disso, o fator de replicação dos blocos armazenados nesses DataNodes fica abaixo do valor especificado. Como resultado, o NameNode inicia a replicação desses blocos e se recupera da falha.
3. Rebalanceamento de cluster
A arquitetura Hadoop HDFS executa automaticamente o rebalanceamento de cluster. Se o espaço livre no DataNode ficar abaixo do nível limite, a arquitetura HDFS moverá automaticamente alguns dados para outro DataNode onde houver espaço suficiente disponível.
4. Econômico
A configuração do cluster do Hadoop é econômica porque inclui hardware de baixo custo. Qualquer organização pode configurar facilmente um cluster Hadoop poderoso sem gastar muito em hardware de servidor caro.
Além disso, os clusters do Hadoop com sua topologia de armazenamento distribuído superam as limitações do sistema tradicional. O armazenamento limitado pode ser estendido apenas adicionando unidades de armazenamento de baixo custo adicionais ao sistema.
5. Flexível
Os clusters Hadoop são altamente flexíveis, pois podem processar dados de qualquer tipo, estruturados, semiestruturados ou não estruturados e de qualquer tamanho, de Gigabytes a Petabytes.
6. Processamento rápido
No Hadoop Cluster, os dados podem ser processados paralelamente em um ambiente distribuído. Isso fornece recursos de processamento de dados rápidos para o Hadoop. Os clusters Hadoop podem processar Terabytes ou Petabytes de dados em uma fração de segundos.
7. Integridade dos dados
Para verificar qualquer corrupção em blocos de dados devido a software com bugs, falhas em um dispositivo de armazenamento, etc., o Hadoop Cluster implementa checksum em cada bloco do arquivo. Caso encontre algum bloco corrompido, busca-o em outro DataNode que contenha a réplica do mesmo bloco. Assim, o cluster Hadoop mantém a integridade dos dados.
Resumo
Depois de ler este artigo, podemos dizer que o Hadoop Cluster é um cluster computacional especial projetado para analisar e armazenar big data. O Hadoop Cluster segue a arquitetura mestre-escravo.
O nó mestre é a máquina de computador de última geração e os nós escravos são máquinas com configuração normal de CPU e memória. Também vimos que o Hadoop Cluster pode ser configurado em uma única máquina chamada Hadoop Cluster de nó único ou em várias máquinas chamadas Hadoop Cluster de vários nós.
Neste artigo, também abordamos as práticas recomendadas a serem seguidas ao criar um cluster do Hadoop. Também vimos muitas vantagens do cluster Hadoop, incluindo escalabilidade, flexibilidade, custo-benefício, etc.



