Explore a arquitetura do Hadoop, que é a estrutura mais adotada para armazenar e processar dados em massa.
Neste artigo, estudaremos a Arquitetura Hadoop. O artigo explica a arquitetura do Hadoop e os componentes da arquitetura do Hadoop que são HDFS, MapReduce e YARN. No artigo, exploraremos a arquitetura do Hadoop em detalhes, juntamente com o diagrama da Arquitetura do Hadoop.
Vamos agora começar com a Arquitetura Hadoop.
Arquitetura do Hadoop
O objetivo de projetar o Hadoop é desenvolver uma estrutura barata, confiável e escalável que armazene e analise o big data crescente.
Apache Hadoop é uma estrutura de software projetada pela Apache Software Foundation para armazenar e processar grandes conjuntos de dados de tamanhos e formatos variados.
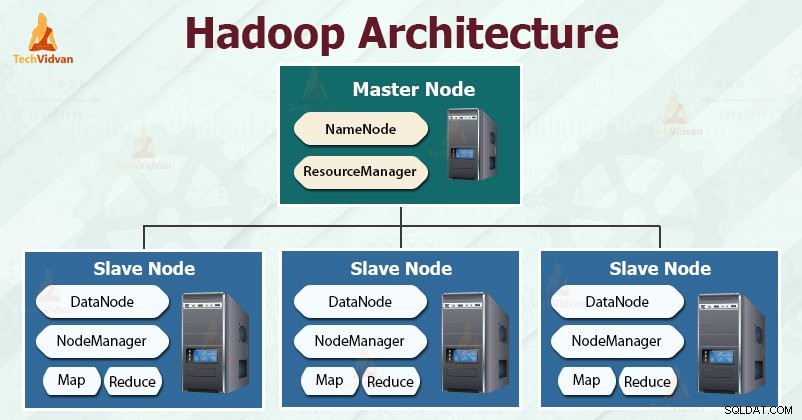
O Hadoop segue o mestre-escravo arquitetura para armazenar e processar efetivamente grandes quantidades de dados. Os nós mestres atribuem tarefas aos nós escravos.
Os nós escravos são responsáveis por armazenar os dados reais e realizar a computação/processamento real. Os nós mestres são responsáveis por armazenar os metadados e gerenciar os recursos no cluster.
Os nós escravos armazenam os dados de negócios reais, enquanto o mestre armazena os metadados.
A arquitetura Hadoop compreende três camadas. Eles estão:
- Camada de armazenamento (HDFS)
- Camada de gerenciamento de recursos (YARN)
- Camada de processamento (MapReduce)
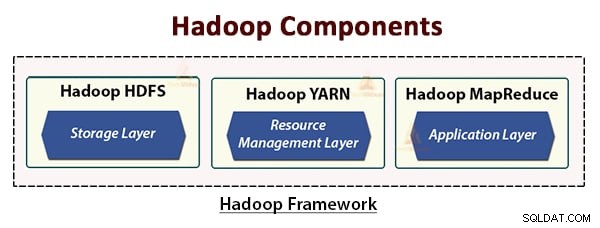
O HDFS, YARN e MapReduce são os principais componentes do Hadoop Framework.
Vamos agora estudar esses três componentes principais em detalhes.
1. HDFS
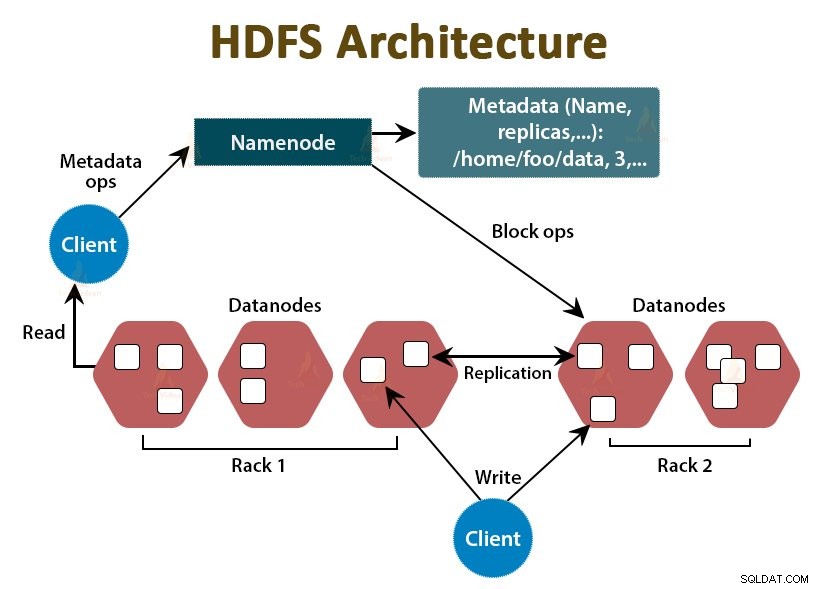
HDFS é o Sistema de Arquivos Distribuídos Hadoop , que roda em hardware de baixo custo. É a camada de armazenamento do Hadoop. Os arquivos no HDFS são divididos em blocos de tamanho de bloco chamados blocos de dados.
Esses blocos são então armazenados nos nós escravos do cluster. O tamanho do bloco é de 128 MB por padrão, que podemos configurar conforme nossos requisitos.
Assim como o Hadoop, o HDFS também segue a arquitetura mestre-escravo. Ele compreende dois daemons - NameNode e DataNode. O NameNode é o daemon mestre que é executado no nó mestre. Os DataNodes são o daemon escravo que é executado nos nós escravos.
NomeNode
NameNode armazena os metadados do sistema de arquivos, ou seja, nomes de arquivos, informações sobre blocos de um arquivo, localizações de blocos, permissões, etc. Ele gerencia os Datanodes.
DataNode
DataNodes são os nós escravos que armazenam os dados de negócios reais. Ele atende às solicitações de leitura/gravação do cliente com base nas instruções do NameNode.
DataNodes armazena os blocos dos arquivos e NameNode armazena os metadados como locais de bloco, permissão, etc.
2. MapReduce
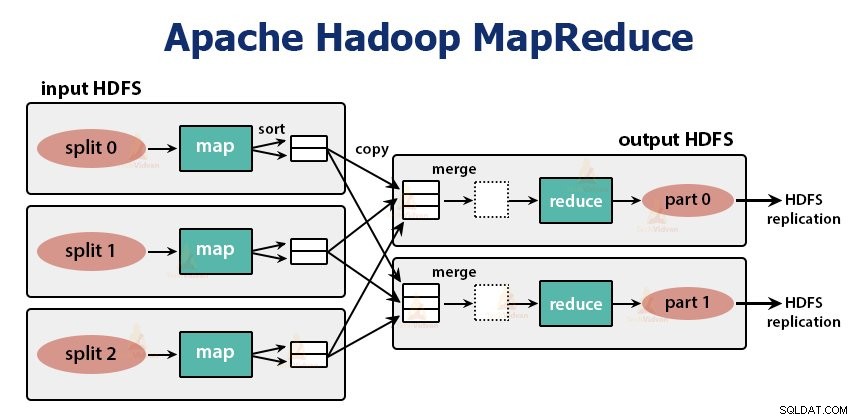
É a camada de processamento de dados do Hadoop. É uma estrutura de software para escrever aplicativos que processam grandes quantidades de dados (terabytes a petabytes no intervalo) em paralelo no cluster de hardware comum.
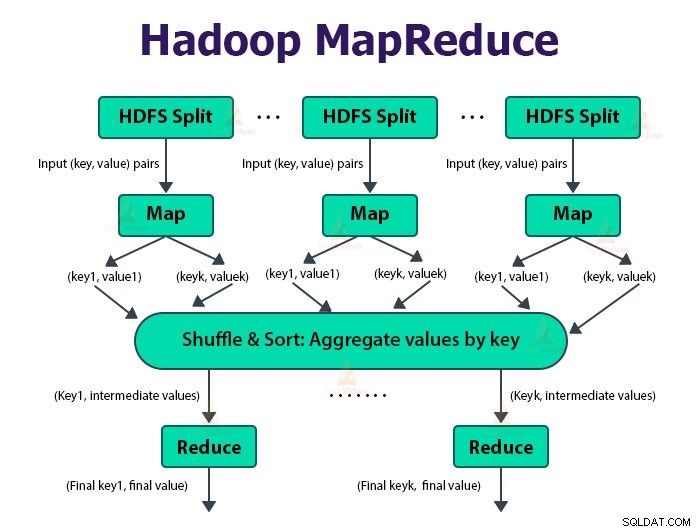
A estrutura MapReduce funciona nos pares
O trabalho MapReduce é a unidade de trabalho que o cliente deseja realizar. O trabalho MapReduce consiste principalmente nos dados de entrada, no programa MapReduce e nas informações de configuração. O Hadoop executa as tarefas do MapReduce dividindo-as em dois tipos de tarefas que são tarefas de mapa e reduzir tarefas . O Hadoop YARN agendou essas tarefas e são executadas nos nós do cluster.
Devido a algumas condições desfavoráveis, se as tarefas falharem, elas serão automaticamente reprogramadas em um nó diferente.
O usuário define a função de mapa e a função reduzir para executar o trabalho MapReduce.
A entrada para a função map e a saída da função reduce é o par chave, valor.
A função das tarefas de mapa é carregar, analisar, filtrar e transformar os dados. A saída da tarefa de mapa é a entrada para a tarefa de redução. A tarefa de redução executa o agrupamento e a agregação na saída da tarefa de mapa.
A tarefa MapReduce é feita em duas fases-
1. Fase do mapa
a. Leitor de registros
O Hadoop divide as entradas para o trabalho MapReduce em divisões de tamanho fixo chamadas divisões de entrada ou divisões. O RecordReader transforma essas divisões em registros e analisa os dados em registros, mas não analisa os registros em si. Leitor de registros fornece os dados para a função mapeadora em pares chave-valor.
b. Mapa
Na fase de mapa, o Hadoop cria uma tarefa de mapa que executa uma função definida pelo usuário chamada função de mapa para cada registro na divisão de entrada. Ele gera zero ou vários pares de valores-chave intermediários como saída da tarefa de mapa.
A tarefa de mapa grava sua saída no disco local. Essa saída intermediária é então processada pelas tarefas de redução que executam uma função de redução definida pelo usuário para produzir a saída final. Depois que o trabalho é concluído, a saída do mapa é liberada.
c. Combinador
A entrada para a tarefa de redução única é a saída de todos os Mapeadores que é saída de todas as tarefas de mapa. O Hadoop permite que o usuário defina uma função de combinação que é executada na saída do mapa.
Combinador agrupa os dados na fase de mapa antes de passá-los para o Reducer. Ele combina a saída da função map que é então passada como entrada para a função reduce.
d. Particionador
Quando há vários redutores, as tarefas de mapa particionam sua saída, cada uma criando uma partição para cada tarefa de redução. Em cada partição, pode haver muitas chaves e seus valores associados, mas os registros de qualquer chave estão todos em uma única partição.
O Hadoop permite que os usuários controlem o particionamento especificando uma função de particionamento definida pelo usuário. Geralmente, há um Partitioner padrão que agrupa as chaves usando a função hash.
2. Fase de redução:
As várias fases na tarefa de redução são as seguintes:
a. Classificar e embaralhar:
A tarefa Redutor começa com uma etapa de embaralhar e classificar. O objetivo principal desta fase é coletar as chaves equivalentes juntas. A fase Sort and Shuffle baixa os dados que são gravados pelo particionador no nó em que o Reducer está sendo executado.
Ele classifica cada parte de dados em uma grande lista de dados. A estrutura MapReduce executa essa classificação e embaralha para que possamos iterar facilmente na tarefa de redução.
A classificação e embaralhamento são executados pelo framework automaticamente. O desenvolvedor por meio do objeto comparador pode ter controle sobre como as chaves são classificadas e agrupadas.
b. Reduzir:
O Redutor, que é a função de redução definida pelo usuário, é executada uma vez por agrupamento de teclas. O redutor filtra, agrega e combina dados de várias maneiras diferentes. Depois que a tarefa de redução é concluída, ela fornece zero ou mais pares de valores-chave para o OutputFormat. A saída da tarefa de redução é armazenada no Hadoop HDFS.
c. Formato de saída
Ele pega a saída do redutor e a grava no arquivo HDFS pelo RecordWriter. Por padrão, ele separa chave, valor por uma tabulação e cada registro por um caractere de nova linha.
3. FIO
YARN significa Yet Another Resource Negotiator . É a camada de gerenciamento de recursos do Hadoop. Foi introduzido no Hadoop 2.
O YARN foi projetado com a ideia de dividir as funcionalidades de agendamento de tarefas e gerenciamento de recursos em daemons separados. A ideia básica é ter um ResourceManager global e um mestre de aplicativos por aplicativo, onde o aplicativo pode ser um único trabalho ou DAG de trabalhos.
O YARN consiste em ResourceManager, NodeManager e ApplicationMaster por aplicativo.
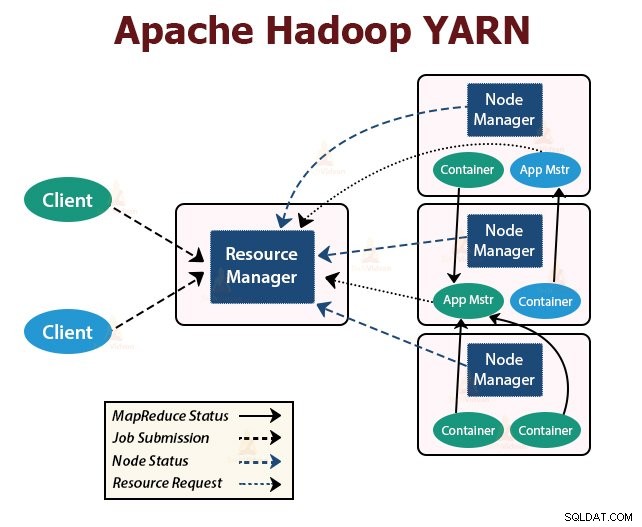
1. Gestor de recursos
Ele arbitra recursos entre todos os aplicativos no cluster.
Ele tem dois componentes principais que são o Scheduler e o ApplicationManager.
a. Agendador
- O Agendador aloca recursos para as diversas aplicações em execução no cluster, considerando as capacidades, filas, etc.
- É um Agendador puro. Ele não monitora nem rastreia o status do aplicativo.
- O Agendador não garante o reinício das tarefas com falha que falharam devido a falha do aplicativo ou falha de hardware.
- Ele realiza o agendamento com base nos requisitos de recursos dos aplicativos.
b. Gerenciador de aplicativos
- Eles são responsáveis por aceitar os envios de trabalho.
- O ApplicationManager negocia o primeiro contêiner para executar o ApplicationMaster específico do aplicativo.
- Eles fornecem serviço para reiniciar o contêiner ApplicationMaster em caso de falha.
- O ApplicationMaster por aplicativo é responsável por negociar contêineres do Agendador. Ele rastreia e monitora seu status e progresso.
2. Gerenciador de nós:
O NodeManager é executado nos nós escravos. Ele é responsável por contêineres, monitorando o uso de recursos da máquina que é CPU, memória, disco, uso de rede e relatando o mesmo ao ResourceManager ou Agendador.
3. Mestre de aplicativos:
O ApplicationMaster por aplicativo é uma biblioteca específica da estrutura. Ele é responsável por negociar recursos do ResourceManager. Ele trabalha com o(s) NodeManager(s) para executar e monitorar as tarefas.
Resumo
Neste artigo, estudamos a Arquitetura Hadoop. O Hadoop segue a topologia mestre-escravo. Os nós mestres atribuem tarefas aos nós escravos. A arquitetura compreende três camadas que são HDFS, YARN e MapReduce.
HDFS é o sistema de arquivos distribuído no Hadoop para armazenamento de big data. MapReduce é a estrutura de processamento para processar grandes dados no cluster Hadoop de maneira distribuída. O YARN é responsável por gerenciar os recursos entre os aplicativos no cluster.
O daemon HDFS NameNode e o daemon YARN ResourceManager são executados no nó mestre no cluster Hadoop. O daemon HDFS DataNode e o YARN NodeManager são executados nos nós escravos.
A estrutura HDFS e MapReduce é executada no mesmo conjunto de nós, o que resulta em largura de banda agregada muito alta em todo o cluster.
Continue aprendendo!!



