Os sistemas de banco de dados são componentes cruciais no ciclo de qualquer aplicativo em execução bem-sucedido. Cada organização que os envolve, portanto, tem a obrigação de garantir o bom desempenho desses DBMs por meio de monitoramento consistente e tratamento de pequenos contratempos antes que eles se transformem em enormes complicações que podem resultar em tempo de inatividade do aplicativo ou desempenho lento.
Você pode perguntar como saber se o banco de dados realmente terá um problema enquanto estiver funcionando normalmente? Bem, isso é o que vamos discutir neste artigo e chamamos isso de benchmarking. O benchmarking está basicamente executando algum conjunto de consultas com alguns dados de teste junto com algum fornecimento de recursos para determinar se esses parâmetros atendem ao nível de desempenho esperado.
O MongoDB não possui uma metodologia de benchmarking padrão, portanto, precisamos resolver em testes de consultas em hardware próprio. Por mais que você também possa obter números impressionantes do processo de benchmark, você precisa ser cauteloso, pois esse pode ser um caso diferente ao executar seu banco de dados com consultas reais.
A ideia por trás do benchmarking é ter uma ideia geral de como as diferentes opções de configuração afetam o desempenho, como você pode ajustar algumas dessas configurações para obter o máximo desempenho e estimar o custo de melhorar essa implementação. Além disso, os aplicativos crescem com o tempo em termos de usuários e provavelmente a quantidade de dados a serem atendidos, portanto, é necessário fazer algum planejamento de capacidade antes desse período. Depois de perceber uma tendência crescente de dados, você precisa fazer alguns benchmarks sobre como atenderá aos requisitos desses vastos dados crescentes.
Considerações sobre o benchmarking do MongoDB
- Selecione cargas de trabalho que são uma representação típica dos aplicativos modernos de hoje. As aplicações modernas estão se tornando mais complexas a cada dia e isso é transmitido para as estruturas de dados. Ou seja, a apresentação de dados também mudou com o tempo, por exemplo, armazenando campos simples em objetos e matrizes. Não é muito fácil trabalhar com esses dados com configurações de banco de dados padrão ou abaixo do padrão, pois isso pode levar a problemas como baixa latência e operações de taxa de transferência ruins envolvendo dados complexos. Ao executar um benchmark, portanto, você deve usar dados que sejam uma apresentação clara de seu aplicativo.
- Verifique novamente as gravações. Certifique-se sempre de que todas as gravações de dados foram feitas de uma maneira que não permitiu perda de dados. Isso é para melhorar a integridade dos dados, garantindo que os dados sejam consistentes e sejam mais aplicáveis, especialmente no ambiente de produção.
- Empregar volumes de dados que são uma representação de conjuntos de dados de “big data” que certamente excederão a capacidade de RAM para um nó individual. Quando a carga de trabalho de teste for grande, isso ajudará você a prever as expectativas futuras do desempenho do banco de dados, portanto, inicie um planejamento de capacidade com antecedência suficiente.
Metodologia
Nosso teste de benchmark envolverá alguns grandes dados de localização que podem ser baixados aqui e usaremos o software Robo3t para manipular nossos dados e coletar as informações de que precisamos. O arquivo tem mais de 500 documentos que são suficientes para nosso teste. Estamos usando o MongoDB versão 4.0 em um servidor dedicado Ubuntu Linux 12.04 Intel Xeon-SandyBridge E3-1270-Quadcore de 3,4 GHz com 32 GB de RAM, disco giratório Western Digital WD Caviar RE4 de 1 TB e SSD Smart XceedIOPS de 256 GB. Inserimos os primeiros 500 documentos.
Executamos os comandos de inserção abaixo
db.getCollection('location').insertMany([<document1, <document2>…<document500>],{w:0})
db.getCollection('location').insertMany([<document1, <document2>…<document500>],{w:1})Escreva preocupação
A preocupação de gravação descreve o nível de confirmação solicitado do MongoDB para operações de gravação neste caso para um MongoDB autônomo. Para uma operação de alta taxa de transferência, se esse valor for definido como baixo, as chamadas de gravação serão tão rápidas, reduzindo assim a latência da solicitação. Por outro lado, se o valor for definido como alto, as chamadas de gravação serão lentas e, consequentemente, aumentarão a latência da consulta. Uma explicação simples para isso é que, quando o valor é baixo, você não está preocupado com a possibilidade de perder algumas gravações em um evento de travamento do mongod, erro de rede ou falha anônima do sistema. Uma limitação neste caso será, você não terá certeza se essas gravações foram bem-sucedidas. Por outro lado, se o problema de gravação for alto, haverá um prompt de tratamento de erros e, portanto, as gravações serão reconhecidas. Uma confirmação é simplesmente uma confirmação de que o servidor aceitou a gravação para processar.
 Quando o problema de gravação é definido como alto
Quando o problema de gravação é definido como alto  Quando o problema de gravação é definido como baixo
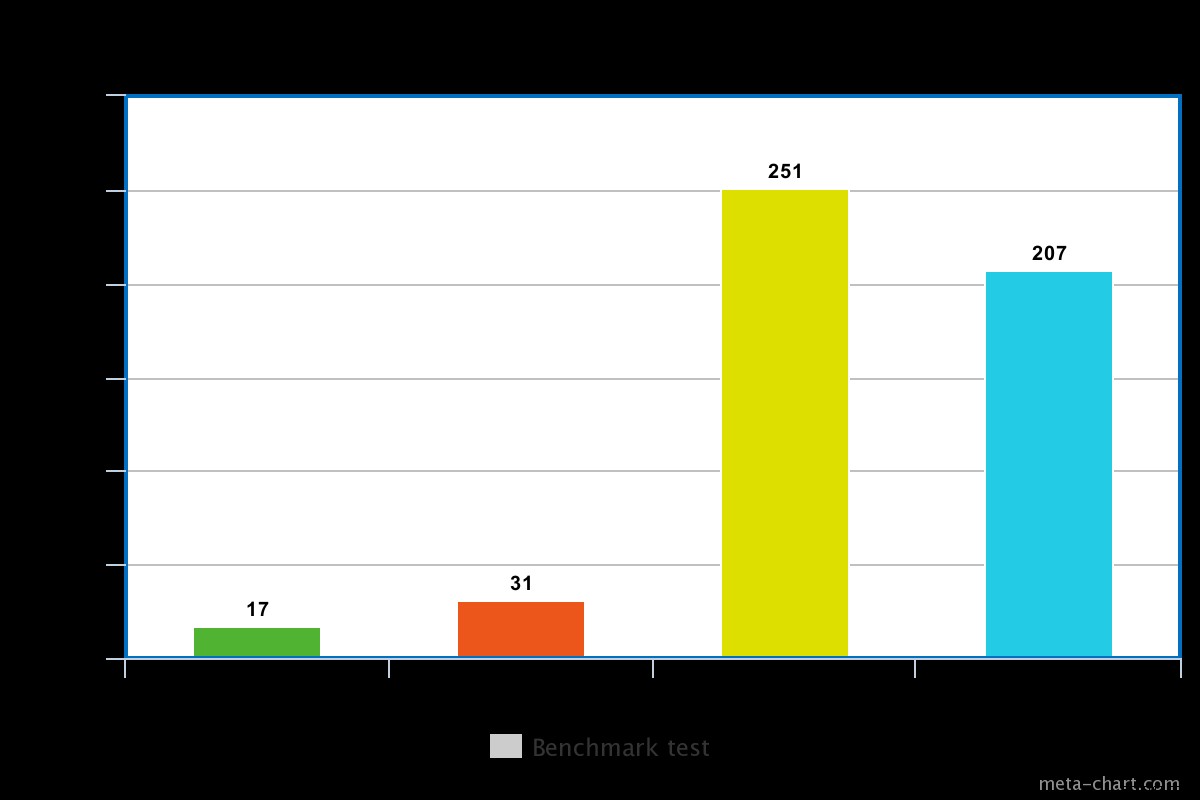
Quando o problema de gravação é definido como baixo Em nosso teste, a preocupação de gravação definida como baixa resultou na execução da consulta em um mínimo de 0,013ms e um máximo de 0,017ms. Nesse caso, o reconhecimento básico de gravação está desabilitado, mas ainda é possível obter informações sobre exceções de soquete e qualquer erro de rede que possa ter sido acionado.
Quando o problema de gravação é definido como alto, quase o dobro do tempo para retornar com o tempo de execução sendo 0,027ms mínimo e 0,031ms máximo. O reconhecimento neste caso é garantido, mas não 100% atingiu o diário do disco. Nesse caso, as chances de perda de gravação são de 50% devido à janela de 100 ms em que o diário pode não ser liberado para o disco.
Diário
Essa é uma técnica para garantir que não haja perda de dados, fornecendo durabilidade em caso de falha. Isso é obtido por meio de um registro de gravação antecipada em arquivos de diário em disco. É mais eficiente quando a preocupação de gravação é definida como alta.
Para um disco giratório, o tempo de execução com journaling habilitado é um pouco alto, por exemplo em nosso teste foi cerca de 0,251ms para a mesma operação acima.

O tempo de execução de um SSD, no entanto, é um pouco menor para o mesmo comando. Em nosso teste, foi cerca de 0,207 ms, mas dependendo da natureza dos dados, às vezes isso pode ser 3 vezes mais rápido que um disco giratório.

Quando o registro no diário está ativado, ele confirma que as gravações foram feitas no diário e, portanto, garante a durabilidade dos dados. Consequentemente, a operação de gravação sobreviverá a um desligamento do mongod e garante que a operação de gravação seja durável.
Para uma operação de alto rendimento, você pode reduzir pela metade os tempos de consulta definindo w=0. Caso contrário, se você precisar ter certeza de que os dados foram gravados, ou melhor, serão no caso de um retorno à vida após a falha, você precisará definir o w =1.
 Severalnines Torne-se um DBA do MongoDB - Trazendo o MongoDB para a produçãoSaiba mais sobre o que você precisa saber para implantar, monitorar, gerenciar e scale MongoDBBaixar gratuitamente
Severalnines Torne-se um DBA do MongoDB - Trazendo o MongoDB para a produçãoSaiba mais sobre o que você precisa saber para implantar, monitorar, gerenciar e scale MongoDBBaixar gratuitamente Replicação
A confirmação de uma preocupação de gravação pode ser habilitada para mais de um nó que é o primário e alguns secundários em um conjunto de réplicas. Isso será caracterizado por qual número inteiro é valorizado para o parâmetro de gravação. Por exemplo, se w =3, o Mongod deve garantir que a consulta receba uma confirmação do nó principal e de 2 escravos. Se você tentar definir um valor maior que um e o nó ainda não estiver replicado, ele gerará um erro informando que o host deve ser replicado.
A replicação vem com um revés de latência, de modo que o tempo de execução será aumentado. Para a consulta simples acima, se w=3, o tempo médio de execução aumenta para 270 ms. Um fator determinante para isso é o intervalo no tempo de resposta entre os nós afetados pela latência da rede, sobrecarga de comunicação entre os 3 nós e congestionamento. Além disso, todos os três nós esperam um ao outro terminar antes de retornar o resultado. Em uma implantação de produção, você não precisará envolver tantos nós se quiser melhorar o desempenho. O MongoDB é responsável por selecionar quais nós devem ser reconhecidos, a menos que haja uma especificação no arquivo de configuração usando tags.
Disco giratório vs disco de estado sólido
Como mencionado acima, o disco SSD é bastante rápido do que o disco giratório, dependendo dos dados envolvidos. Às vezes, pode ser 3 vezes mais rápido, portanto, vale a pena pagar, se necessário. No entanto, será mais caro usar um SSD, especialmente ao lidar com dados vastos. O MongoDB tem o mérito de suportar o armazenamento de bancos de dados em diretórios que podem ser montados, portanto, a chance de usar um SSD. Empregar um SSD e habilitar o journaling é uma ótima otimização.
Conclusão
O experimento tinha certeza de que a preocupação de gravação desabilitada resulta em tempo de execução reduzido de uma consulta às custas das chances de perda de dados. Por outro lado, quando a preocupação de gravação está habilitada, o tempo de execução é quase 2 vezes quando está desabilitada, mas há a garantia de que os dados não serão perdidos. Além disso, podemos justificar que o SSD é mais rápido que um disco giratório. No entanto, para garantir a durabilidade dos dados em caso de falha do sistema, é aconselhável habilitar a preocupação de gravação. Ao habilitar a preocupação de gravação para um conjunto de réplicas, não defina o número muito grande, pois isso pode resultar em algum desempenho degradado no final do aplicativo.



