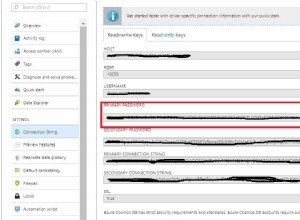
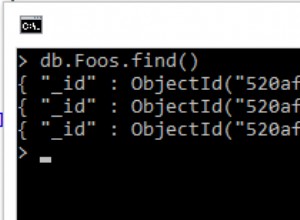
O próprio Spark depende do Hadoop e os dados no HDFS podem ser usados como fonte de dados. No entanto, se você usar o Mongo Spark Connector você pode usar o MongoDB como uma fonte de dados para o Spark sem usar o Hadoop.