Você está usando o MongoDB para armazenar o ID. É um estado. A geração do ID é uma função. Você usa o Mongodb para gerar o ID quando o processo do mongodb recebe argumentos da função e retorna o ID gerado. Não é o que você está fazendo. Você está usando nodejs para gerar o ID.
O número de threads, ou melhor, loops de eventos é fundamental, pois define a arquitetura, mas de qualquer forma você não precisa de transações. As transações no mongodb estão sendo chamadas de "transações de vários documentos" exatamente para destacar que são destinadas à atualização consistente de vários documentos ao mesmo tempo. O primeiro parágrafo de https://docs.mongodb.com/manual/core/transactions / avisa que se você atualizar um único documento não há espaço para transações.
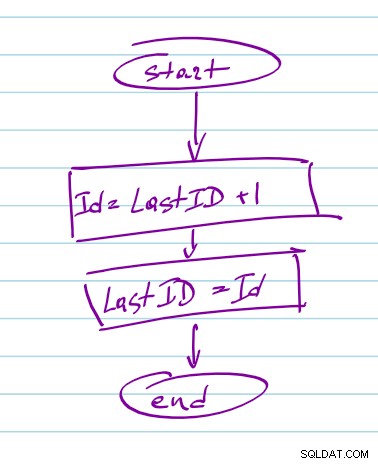
Um único aplicativo encadeado não requer nenhuma sincronização. Você pode ler com segurança o ID gerado mais recente na inicialização e garantir que o ID seja exclusivo no processo nodejs. Se você excluir mongodb e outras E/S da função de geração, você a tornará síncrona para poder manter o estado do ID dentro do processo nodejs e garantir sua exclusividade. Uma vez gerado, você pode persistir no banco de dados de forma assíncrona. Na pior das hipóteses, você pode ter uma lacuna nos números sequenciais, mas não duplicatas.
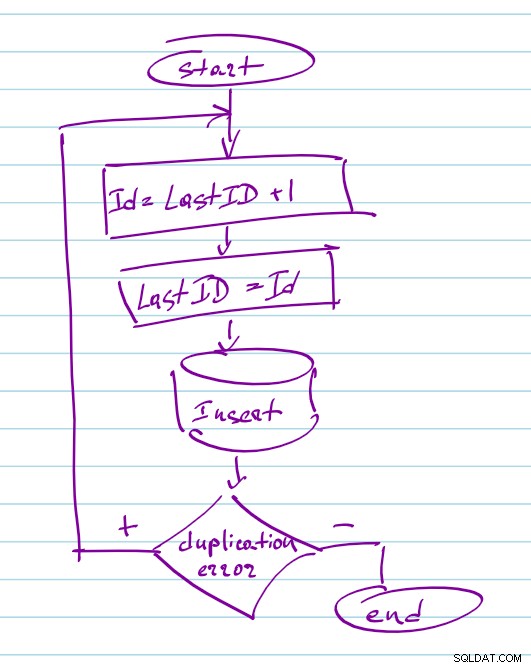
Se houver uma pequena chance de você precisar escalar para mais de 1 processo nodejs para lidar com mais solicitações simultâneas ou adicionar outro host para redundância no futuro, você precisará sincronizar a geração do ID e poderá empregar índices exclusivos do Mongodb para este. A função em si não muda muito, você ainda gera o ID como em uma arquitetura de thread único, mas adiciona uma etapa extra para salvar o ID no mongo. O documento deve ter um índice exclusivo no campo ID, portanto, em caso de atualizações simultâneas, uma das consultas adicionará o documento com sucesso e outra falhará com "E11000 erro de chave duplicada". Você pega esses erros no lado do nodejs e repete a função novamente escolhendo o próximo número: