Saiba mais sobre a arquitetura de ingestão de dados quase em tempo real para transformar e enriquecer fluxos de dados usando Apache Flume, Apache Kafka e RocksDB no Santander UK.
A Cloudera Professional Services tem trabalhado com o Santander UK para construir um sistema de análise transacional quase em tempo real (NRT) no Apache Hadoop. O objetivo é capturar, transformar, enriquecer, contar e armazenar uma transação em poucos segundos após a compra do cartão. O sistema recebe as transações de cartão de cliente de varejo do banco e calcula as informações de tendência associadas agregadas por titular de conta e em várias dimensões e taxonomias. Essas informações são fornecidas com segurança ao aplicativo "Spendlytics" do Santander (veja abaixo) para permitir que os clientes analisem seus padrões de gastos mais recentes.
O Apache HBase foi escolhido como a solução de armazenamento subjacente devido à sua capacidade de suportar gravações aleatórias de alto rendimento e leituras aleatórias de baixa latência. No entanto, a exigência da NRT descartou a realização de transformações e enriquecimento das transações em lote, portanto, estas devem ser feitas enquanto as transações são transmitidas para o HBase. Isso inclui transformar mensagens de XML para Avro e enriquecê-las com informações de tendências, como informações de marca e comerciante.
Esta postagem descreve como o Santander usa Apache Flume, Apache Kafka e RocksDB para transformar, enriquecer e transmitir transações para o HBase. Esta é uma implementação do NRT Event Processing with External Context padrão de streaming descrito por Ted Malaska neste post.
Flafka
A primeira decisão que o Santander teve que tomar foi a melhor forma de transmitir dados para o HBase. O Flume é quase sempre a melhor escolha para ingestão de streaming no Hadoop devido à sua simplicidade, confiabilidade, rica variedade de fontes e coletores e escalabilidade inerente.
Recentemente, uma excelente integração ao Kafka foi adicionada, levando ao inevitavelmente chamado Flafka. O Flume pode fornecer de forma nativa a entrega de eventos garantida por meio de seu canal de arquivos, mas a capacidade de reproduzir eventos e a flexibilidade adicional e a proteção para o futuro que Kafka traz foram os principais impulsionadores da integração.
Nessa arquitetura, o Santander usa os canais Kafka para fornecer um buffer de ingestão confiável, auto-equilibrado e escalável, no qual todas as transformações e processamentos são representados em tópicos Kafka encadeados. Em particular, fazemos uso extensivo da fonte e do coletor da Flafka e da capacidade da Flume de realizar processamento em voo usando interceptores. Isso evitou que tivéssemos que codificar nosso próprio produtor e consumidor Kafka e permitiu que o Santander aproveitasse ao máximo o Cloudera Manager para configurar, implantar e monitorar os agentes e corretores.
Transformação
As transações capturadas pelos principais sistemas bancários são entregues ao Flume como mensagens XML, tendo sido lidas do banco de dados de origem por meio de replicação de log. (Colocar um log de banco de dados em tópicos do Kafka dessa maneira é um padrão cada vez mais comum e, combinado com a compactação de log, pode fornecer uma “visão mais recente” do banco de dados para casos de uso de captura de dados de alteração.)
O Flume armazena essas mensagens XML em um tópico Kafka “bruto”. A partir daqui, e como precursor de todos os outros processamentos, decidiu-se transformar o XML semiestruturado em registros binários estruturados para facilitar o processamento downstream padronizado. Esse processamento é realizado por um Flume Interceptor personalizado que transforma as mensagens XML em uma representação Avro genérica, aplicando tipos específicos quando apropriado e retornando a uma representação de string quando não. Todo o processamento NRT subsequente armazena os resultados derivados no Avro em tópicos Kafka dedicados, facilitando o acesso ao fluxo e a obtenção de um feed de eventos em qualquer ponto da cadeia de processamento.
Se um processamento de eventos mais complexo fosse necessário – por exemplo, agregações com Spark Streaming – seria uma questão trivial consumir um ou mais desses tópicos e publicar em novos tópicos derivados. (Apache Avro é uma escolha natural para este formato:é um protocolo binário compacto que suporta a evolução do esquema, tem uma definição de esquema flexível e é suportado em toda a pilha do Hadoop. O Avro está rapidamente se tornando um padrão de fato para armazenamento de dados temporário e geral em um hub de dados corporativos e está perfeitamente posicionado para transformação no Apache Parquet para cargas de trabalho de análise.)
Enriquecimento
A inspiração para o design da solução de enriquecimento de streaming veio de um post do O'Reilly Radar escrito por Jay Kreps. Em seu post, Jay descreve os benefícios de usar um armazenamento local para permitir que um processador de fluxo consulte ou modifique um estado local em resposta à sua entrada, em vez de fazer chamadas remotas para um banco de dados distribuído.
No Santander, adaptamos esse padrão para fornecer lojas de referência locais que são usadas para consultar e enriquecer transações à medida que são transmitidas pelo Flume. Por que não usar o HBase como repositório de referência? Bem, um padrão típico para esse tipo de problema é simplesmente armazenar o estado no HBase e fazer com que o mecanismo de enriquecimento o consulte diretamente. Decidimos contra essa abordagem por alguns motivos. Primeiro, os dados de referência são relativamente pequenos e caberiam em uma única região HBase, provavelmente causando um hotspot de região. Em segundo lugar, o HBase atende ao aplicativo Spendlytics voltado para o cliente e o Santander não queria que a carga adicional afetasse a latência do aplicativo ou vice-versa. Essa também é a razão pela qual decidimos não usar o HBase para inicializar as lojas locais na inicialização.
Assim, ao fornecer a cada Agente Flume uma loja local rápida para enriquecer os eventos durante o voo, o Santander pode oferecer melhores garantias de desempenho tanto para o enriquecimento a bordo quanto para o aplicativo Spendlytics. Decidimos usar o RocksDB para implementar os armazenamentos locais porque ele é capaz de fornecer acesso rápido a grandes quantidades de dados fora do heap (eliminando a carga do GC) e o fato de ter uma API Java para facilitar o uso de um Flume Interceptor personalizado. Essa abordagem nos salvou de ter que codificar nosso próprio armazenamento fora do heap. O RocksDB pode ser facilmente trocado por outra implementação de loja local, mas neste caso foi perfeito para o caso de uso do Santander.
A implementação personalizada do Interceptor de enriquecimento do Flume processa eventos do tópico “transformado” upstream, consulta seu armazenamento local para enriquecê-los e grava os resultados nos tópicos Kafka downstream, dependendo do resultado. Este processo é ilustrado com mais detalhes abaixo.
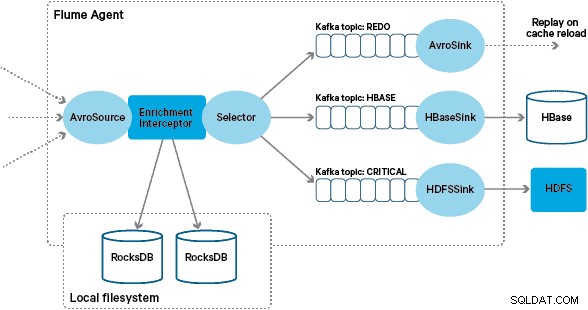
Neste ponto, você pode estar se perguntando:sem persistência fornecida pelo HBase, como os armazenamentos locais são gerados? Os dados de referência compreendem vários conjuntos de dados diferentes que precisam ser unidos. Esses conjuntos de dados são atualizados no HDFS diariamente e formam a entrada para um aplicativo Apache Spark agendado, que gera os armazenamentos RocksDB. Os armazenamentos RocksDB recém-gerados são encenados no HDFS até serem baixados pelos Flume Agents para garantir que o fluxo de eventos seja enriquecido com as informações mais recentes.
Idealmente, não teríamos que esperar que todos esses conjuntos de dados estivessem disponíveis no HDFS antes que pudessem ser processados. Se esse fosse o caso, as atualizações de dados de referência poderiam ser transmitidas por meio do pipeline Flafka para manter continuamente o estado dos dados de referência local.
Em nosso projeto inicial, planejamos escrever e agendar via cron um script para pesquisar o HDFS para verificar novas versões das lojas RocksDB, baixando-as do HDFS quando disponíveis. Embora devido aos controles internos e governança dos ambientes de produção do Santander, esse mecanismo teve que ser incorporado ao mesmo Flume Interceptor que é usado para realizar o enriquecimento (ele verifica as atualizações uma vez por hora, portanto, não é uma operação cara). Quando uma nova versão da loja está disponível, uma tarefa é despachada para um thread de trabalho para baixar a nova loja do HDFS e carregá-la no RocksDB. Esse processo acontece em segundo plano enquanto o Interceptor de enriquecimento continua processando o fluxo. Depois que a nova versão da loja é carregada no RocksDB, o Interceptor alterna para a versão mais recente e a loja expirada é excluída. O mesmo mecanismo é usado para inicializar os armazenamentos RocksDB de uma inicialização a frio antes que o Interceptor comece a tentar enriquecer eventos.
As mensagens enriquecidas com êxito são gravadas em um tópico Kafka para serem gravadas de forma idempotente no HBase usando o HBaseEventSerializer.
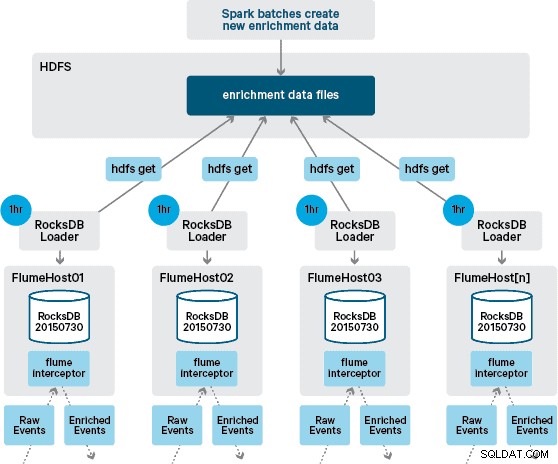
Enquanto o fluxo de eventos é processado continuamente, novas versões do armazenamento local só podem ser geradas diariamente. Imediatamente após uma nova versão da loja local ser carregada pelo Flume, ela é considerada nova”, embora se torne cada vez mais obsoleta antes da disponibilidade de uma nova versão. Consequentemente, o número de “faltas de cache” aumenta até que uma versão mais recente do armazenamento local esteja disponível. Por exemplo, informações de marca e comerciante novas e atualizadas podem ser adicionadas aos dados de referência, mas até que sejam disponibilizadas para o enriquecimento do Flume, as transações do Interceptor podem deixar de ser enriquecidas ou ser enriquecidas com informações desatualizadas que posteriormente precisam ser reconciliado após ter sido persistido no HBase.
Para lidar com esse caso, as faltas de cache (eventos que não são enriquecidos) são gravadas em um tópico “redo” do Kafka usando um seletor Flume. O tópico de refazer é então reproduzido novamente no tópico de origem do Interceptor de enriquecimento quando um novo armazenamento local estiver disponível.
Para evitar “mensagens envenenadas” (eventos que falham continuamente no enriquecimento), decidimos adicionar um contador ao cabeçalho de um evento antes de adicioná-lo ao tópico de redo. Os eventos que aparecem repetidamente nesse tópico são eventualmente redirecionados para um tópico “crítico”, que é gravado no HDFS para inspeção e correção posteriores. Essa abordagem é ilustrada no primeiro diagrama.
Conclusão
Para resumir os principais pontos desta postagem:
- Usar uma cadeia de tópicos Kafka para armazenar dados compartilhados intermediários como parte de seu pipeline de ingestão é um padrão eficaz.
- Você tem várias opções para persistir e consultar o estado ou os dados de referência em seu pipeline de ingestão NRT. Favoreça o HBase para essa finalidade como o padrão comum quando os dados suplementares forem grandes, mas considere o uso de armazenamentos locais incorporados (como RocksDB) ou memória JVM quando o uso do HBase não for prático.
- O tratamento de falhas é importante. (Consulte o nº 1 para obter ajuda sobre isso.)
Em uma postagem de acompanhamento, descreveremos como usamos os coprocessadores HBase para fornecer agregações de tendências históricas de compras por cliente e como as transações off-line são processadas em lote usando (projeto Cloudera Labs) SparkOnHBase (que foi recentemente confirmado no Tronco HBase). Também descreveremos como a solução foi projetada para atender aos requisitos de alta disponibilidade e cross-datacenter do cliente.
James Kinley, Ian Buss e Rob Siwicki são arquitetos de soluções da Cloudera.



