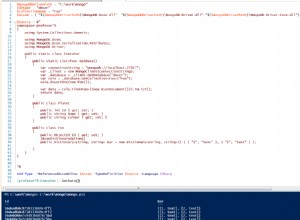
O curta:
COUNT_SCAN é a maneira mais eficiente de obter uma contagem lendo o valor de um índice, mas só pode ser realizada em determinadas situações. Caso contrário, IXSCAN é realizada seguida por alguma filtragem de documentos e uma contagem na memória. Ao ler do secundário, a preocupação de leitura
available é usado. Este nível de preocupação não considera documentos órfãos em clusters fragmentados e, portanto, não há SHARDING_FILTER palco será realizado. É quando você vê COUNT_SCAN . No entanto, se usarmos a preocupação de leitura
local , precisamos buscar os documentos para realizar o estágio de filtro SHARDING_FILTER. Nesse caso, existem vários estágios para preencher a consulta:IXSCAN , então FETCH então SHARDING_FILTER .