Vamos a sua pergunta uma a uma:
Observar as métricas de desempenho de apenas uma única execução não é realmente como funciona. Você deve calcular a média de várias execuções antes de concluir porque há vários fatores em jogo. Dito isso, o MongoDB armazena em cache os documentos usados com mais frequência na memória e os mantém lá, a menos que tenha que ceder memória para algum outro documento. Portanto, se uma consulta acessar documentos já armazenados em cache de uma consulta anterior, ela deverá ser mais rápida.
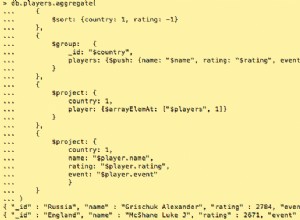
Também na agregação do MongoDB usa índices apenas no início, se houver. Por exemplo
$match e $sort fases podem usar índices. No seu caso $match é o primeiro estágio do pipeline, então é uma vitória. No MongoDB, os dados são armazenados em BSON , então datas são basicamente números quando são comparados. Então não há diferença.
Embora eu não tenha testado, eu realmente duvido que a abordagem time_bucket dê uma resposta mais rápida. Desde
created_at sempre aumentará, o índice, neste caso, também será anexado ao final sem o time_bucket. Além disso, o tamanho do índice será comparativamente maior quando criado em uma matriz do que em um campo de data simples. Isso não causará o problema de ajustar o índice na RAM. Usar um time_bucket faz sentido quando você está usando alguma função no campo de data antes da correspondência. Se você extrair apenas o ano do campo de data antes da correspondência, isso tornará o índice existente na data inútil.
É sempre melhor converter seus parâmetros para corresponder ao tipo de dados no banco de dados em vez do contrário.
Sim é possivel. Se for
$and , basta especificar todos os seus filtros separados por vírgulas no $match Estágio. Se for $ou use o $ou
operador. Se você tiver dois
$macth fases um por um MongoDB combina-o a um
. Portanto, você não precisa se preocupar em adicionar resultados de várias fases de partida. Agora sua Otimização Pontos
Sim, consultas cobertas são muito mais rápidos.
Se o tamanho dos documentos for reduzido no
$group estágio usando $project , então sim é verdade. Não é necessariamente verdade, mas geralmente é o caso. Você pode verificar esta resposta .