Backups - uma das coisas mais importantes para cuidar ao gerenciar bancos de dados. Diz-se que existem dois tipos de pessoas - aquelas que fazem backup de seus dados e aquelas que fazem backup de seus dados. Nesta postagem do blog, discutiremos as boas práticas em torno de backups e mostraremos como você pode criar um sistema de backup confiável usando o ClusterControl.
Veremos como o ClusterControl oferece gerenciamento de backup centralizado para MySQL, MariaDB, MongoDB e PostgreSQL. Ele fornece backups dinâmicos de grandes conjuntos de dados, recuperação pontual, criptografia de dados em repouso e em trânsito, integridade de dados por meio de verificação de restauração automática, backups em nuvem (AWS, Google e Azure) para recuperação de desastres, políticas de retenção para garantir a conformidade e alertas e relatórios automatizados.
Tipos de backup
Existem dois tipos principais de backup que podemos fazer no ClusterControl:
- Backup lógico - o backup de dados é armazenado em um formato legível como SQL
- Backup físico - o backup contém dados binários
Ambos se complementam - o backup lógico permite (mais ou menos facilmente) recuperar até uma única linha de dados. Os backups físicos exigiriam mais tempo para fazer isso, mas, por outro lado, eles permitem restaurar um host inteiro muito rapidamente (algo que pode levar horas ou até dias ao usar o backup lógico).
O ClusterControl suporta backup para MySQL/MariaDB/Percona Server, PostgreSQL e MongoDB.
Agendar backup
Iniciar um backup no ClusterControl é simples e eficiente usando um assistente. Agendar um backup oferece facilidade de uso e acessibilidade a outros recursos, como criptografia, teste/verificação automática de backup ou arquivamento na nuvem.
Os backups agendados disponíveis serão listados na guia Backups agendados conforme a imagem abaixo:
Como uma boa prática para agendar um backup, você já deve ter sua retenção de backup definida e um backup diário é recomendado. No entanto, também depende dos dados que você precisa, do tráfego que você pode esperar e da disponibilidade dos dados sempre que precisar, especialmente durante a recuperação de dados, onde os dados foram excluídos acidentalmente ou uma corrupção de disco - que são inevitáveis. Há situações também em que a perda de dados é reproduzível ou pode ser duplicada manualmente, como, por exemplo, geração de relatórios, miniaturas ou dados em cache. Embora a questão dependa de quão imediatamente você precisa deles sempre que um desastre acontece; quando possível, você deseja fazer backups mysqldump e xtrabackup diariamente para MySQL, aproveitando a disponibilidade de backup lógico e físico. Para cobrir ainda mais bases, você pode querer agendar várias execuções de xtrabackup incrementais por dia. Isso pode economizar algum espaço em disco, E/S de disco ou até E/S de CPU do que fazer um backup completo.
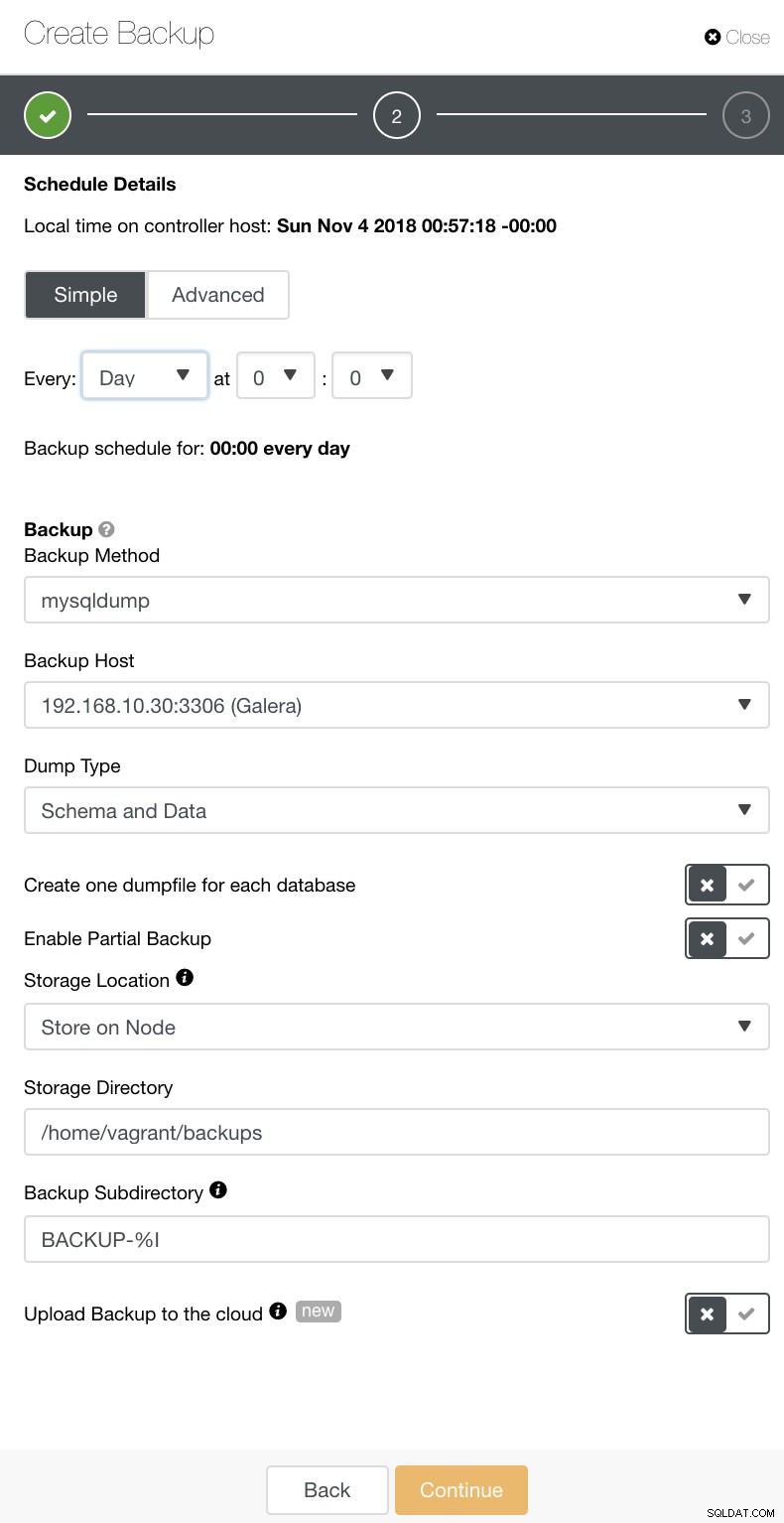
No ClusterControl, você pode agendar facilmente esses diferentes tipos de backups. Existem algumas configurações para decidir. Você pode armazenar um backup no controlador ou localmente, no nó do banco de dados em que o backup é feito. Você precisa decidir sobre o local em que o backup deve ser armazenado e quais bancos de dados você gostaria de fazer backup - todos os conjuntos de dados ou esquemas separados? Veja a imagem abaixo:
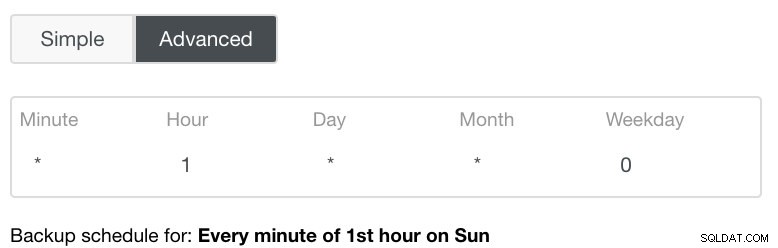
A configuração Avançada aproveitaria uma configuração semelhante ao cron para obter mais granularidade. Veja imagem abaixo:
Sempre que ocorre uma falha, o ClusterControl lida com esses problemas com eficiência e produz logs para diagnóstico adicional da falha de backup.
Dependendo do tipo de backup que você escolheu, existem configurações separadas para configurar. Para Xtrabackup e Galera Cluster, você pode ter as opções para escolher quais configurações seu backup físico aplicaria durante a execução. Ver abaixo:
- Usar compactação
- Nível de compactação
- Dessincronizar nó durante o backup
- Bloqueios de backup
- Bloquear DDL por tabela
- Threads de cópia paralela do Xtrabackup
- Taxa de limitação de streaming de rede (MB/s)
- Usar PIGZ para gzip paralelo
- Ativar criptografia
- Retenção
Você pode ver, na imagem abaixo, como sinalizar as opções adequadamente e há ícones de dicas de ferramentas que fornecem mais informações sobre as opções que você gostaria de aproveitar para sua política de backup.
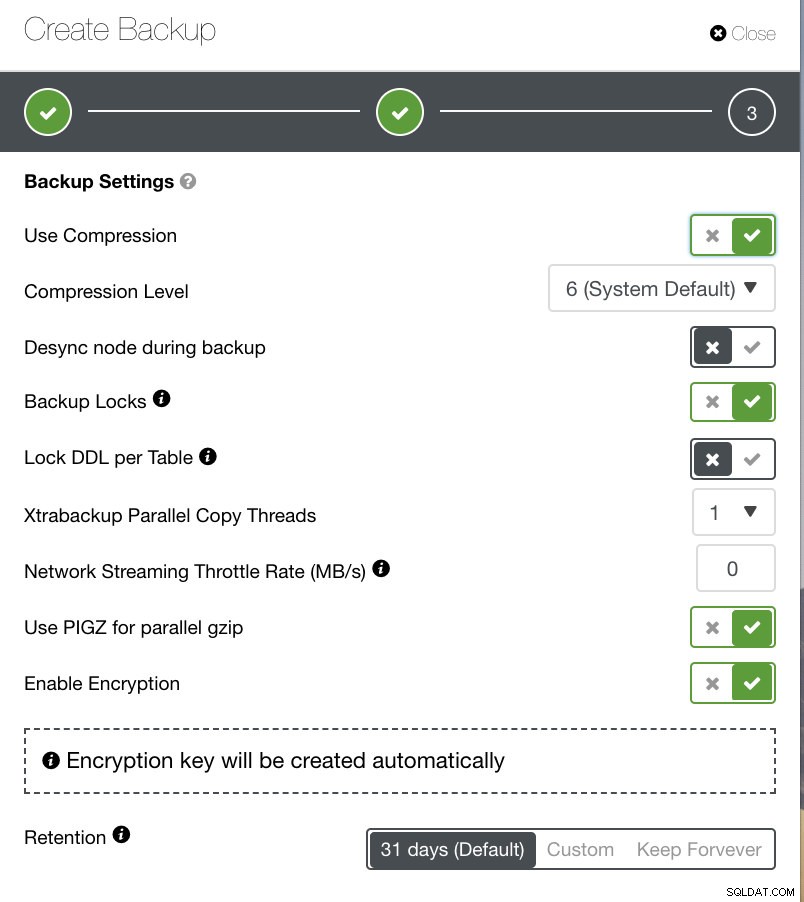
Dependendo de sua política de backup, o ClusterControl pode ser adaptado de acordo com as melhores práticas para atualizar seus backups disponíveis. Ao definir sua política de backup, prevê-se que você deve ter a configuração necessária disponível de hardware para software para nuvem, durabilidade, alta disponibilidade ou escalabilidade.
Ao fazer backups em um Galera Cluster, é uma boa prática definir o nó Galera wsrep_desync=ON enquanto o backup está em execução. Isso impedirá que o nó participe do Flow Control e protegerá todo o cluster do atraso de replicação, especialmente se os dados do backup forem grandes. No ClusterControl, lembre-se de que isso também pode remover o nó de backup de destino do conjunto de balanceamento de carga. Isso é especialmente verdadeiro se você usar proxies HAProxy, ProxySQL ou MaxScale. Se você configurou o gerenciador de alertas caso o nó seja dessincronizado, você pode desligar durante o período em que o backup foi acionado.
Outra forma popular de minimizar o impacto de um backup em um Galera Cluster ou em um mestre de replicação é implantar um escravo de replicação e usá-lo como fonte de backups - desta forma o Galera Cluster não será afetado em nenhum momento, pois o backup no slave é desacoplado do cluster.
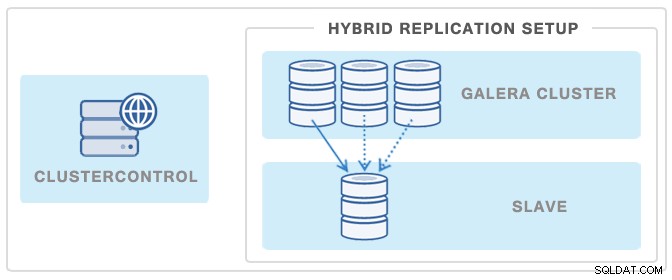
Você pode implantar esse escravo em apenas alguns cliques usando o ClusterControl. Veja imagem abaixo:
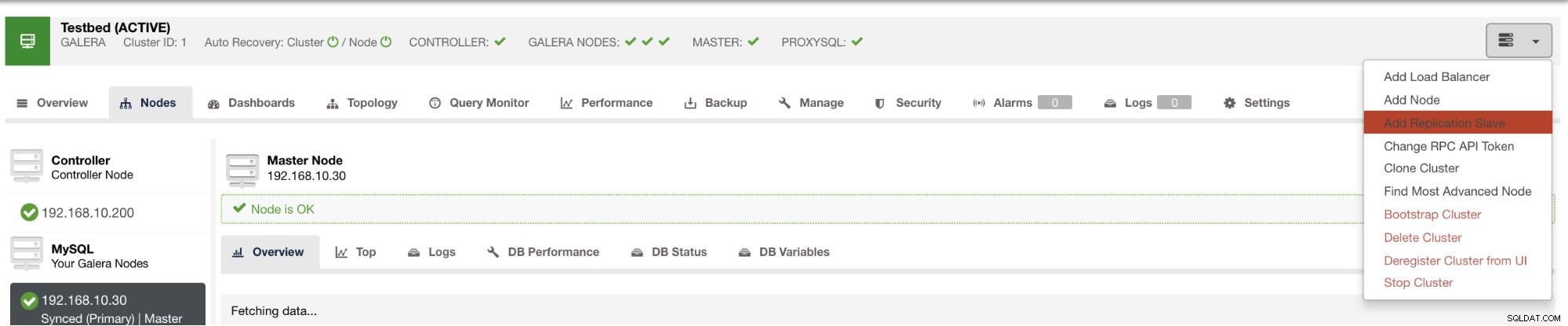
e depois de clicar nesse botão, você pode selecionar em quais nós configurar um escravo. Certifique-se de que o log binário dos nós esteja ativado. A habilitação do log binário também pode ser feita através do ClusterControl, o que adiciona mais viabilidade para a administração do seu mestre desejado. Veja imagem abaixo:
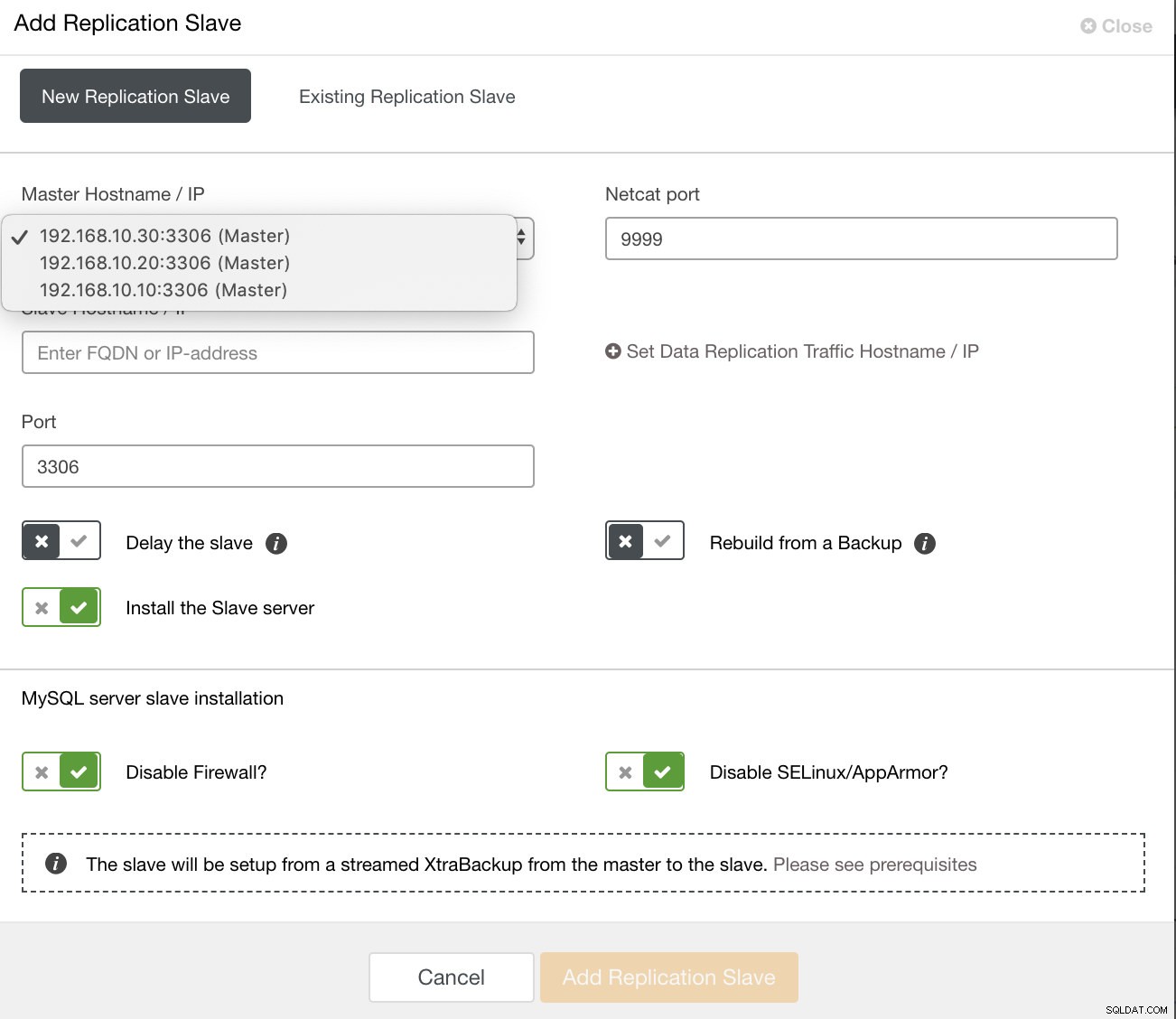
e você também pode configurar o escravo de replicação existente,
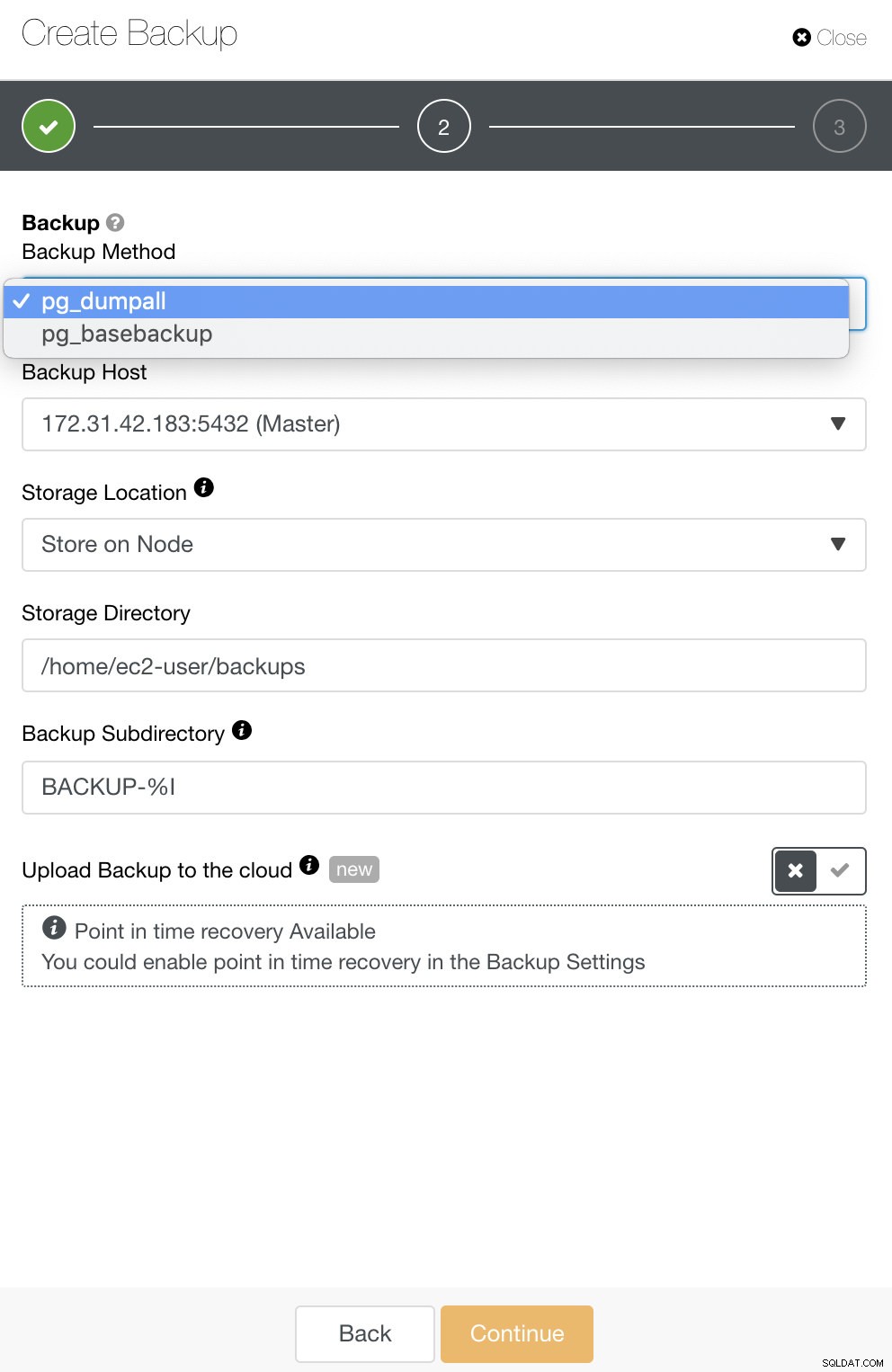
Para o PostgreSQL, você tem opções para fazer backup de backups lógicos ou físicos. No ClusterControl, você pode aproveitar seus backups do PostgreSQL selecionando pg_dump ou pg_basebackup. pg_basebackup não funcionará para versões anteriores a 9.3.
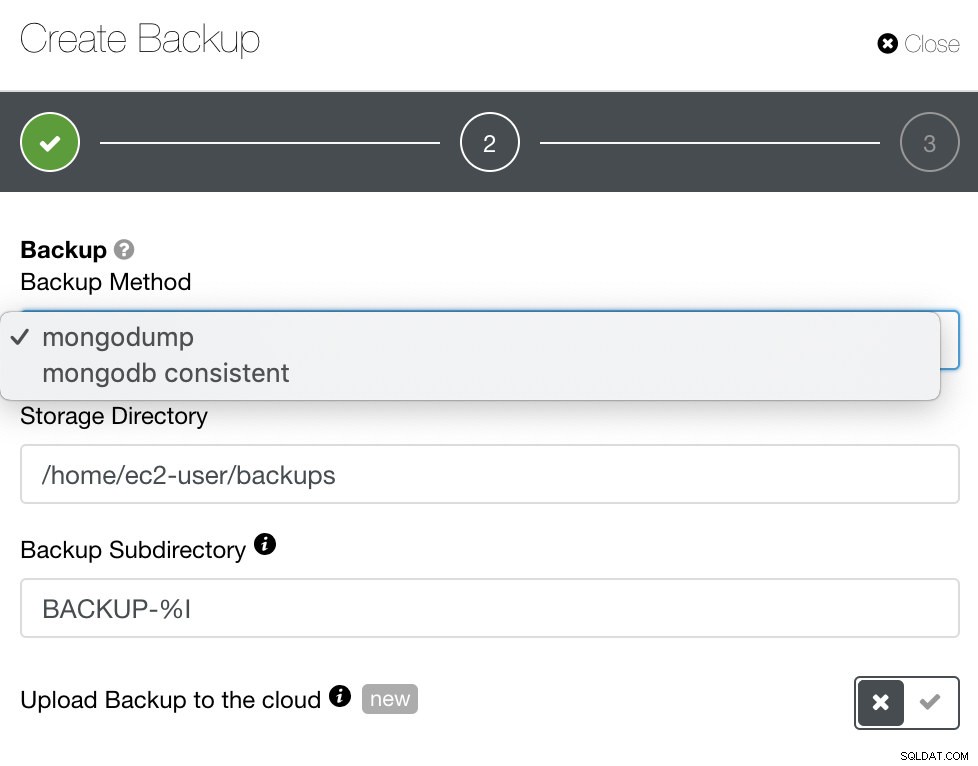
Para MongoDB, ClusterControl oferece mongodump ou mongodb consistente. Você pode ter que notar que o mongodb consistente não suporta RHEL 7, mas você pode instalá-lo manualmente.
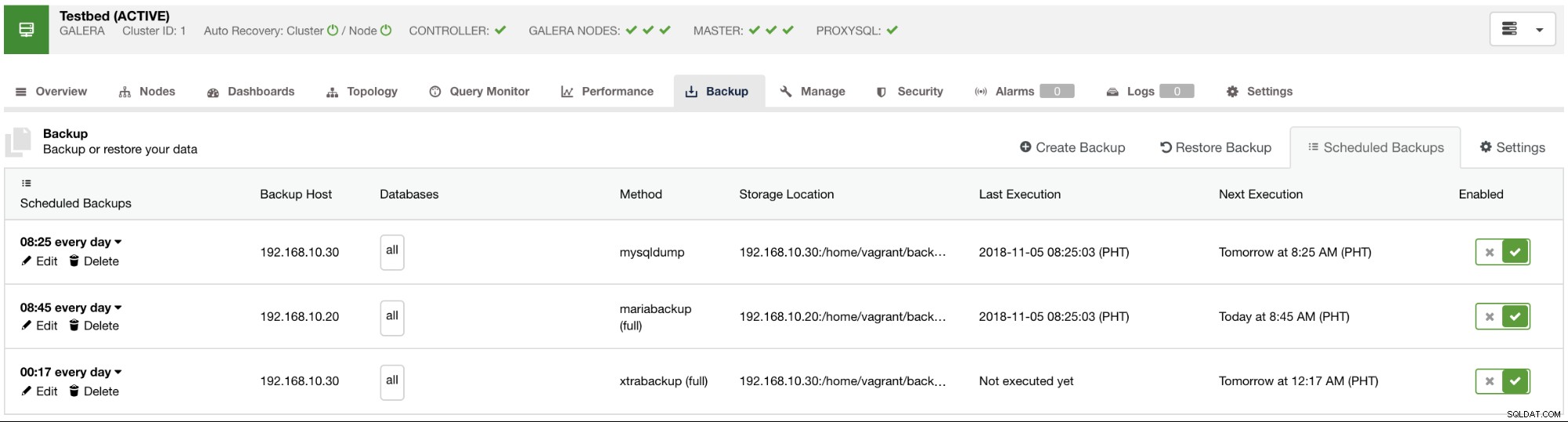
Por padrão, o ClusterControl listará um relatório de todos os backups realizados, bem-sucedidos ou com falha. Ver abaixo:
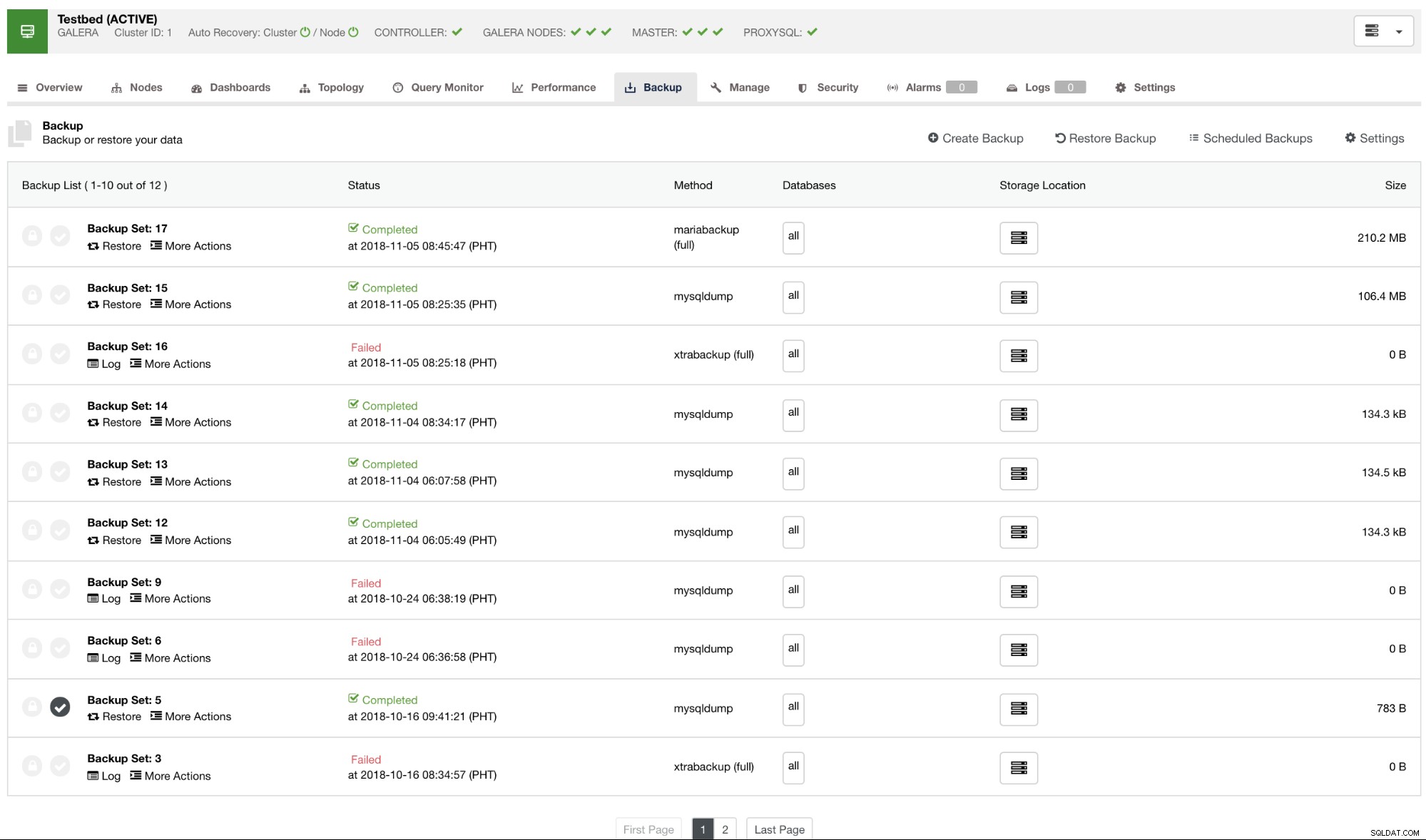
Você pode verificar a lista de relatórios de backup que foram criados ou agendados usando o ClusterControl. Na lista, você pode visualizar os logs para investigação e diagnóstico adicionais. Por exemplo, se o backup foi concluído corretamente de acordo com a política de backup desejada, se a compactação e a criptografia estão definidas corretamente ou se o tamanho dos dados de backup desejado está correto. Essa é uma boa maneira de fazer uma verificação rápida de integridade - se seu conjunto de dados tiver cerca de 1 GB de tamanho, não há como um backup completo ser tão pequeno quanto 100 KB - algo deve ter dado errado em algum momento.
Recuperação de desastres
Armazenar backups dentro do cluster (diretamente em um nó de banco de dados ou no host ClusterControl) é útil quando você deseja restaurar seus dados rapidamente:todos os arquivos de backup estão no local e podem ser descompactados e restaurados imediatamente. Quando se trata de recuperação de desastres (DR), essa pode não ser a melhor opção. Diferentes problemas podem acontecer - os servidores podem falhar, a rede pode não funcionar de forma confiável, até mesmo data centers inteiros podem não estar acessíveis devido a algum tipo de interrupção. Isso pode acontecer se você trabalha com um provedor de serviços menor com um único data center ou um fornecedor global como a Amazon Web Services. Portanto, não é seguro manter todos os seus ovos em uma única cesta - você deve certificar-se de ter uma cópia de seu backup armazenada em algum local externo. ClusterControl suporta Amazon S3, Google Storage e Azure Cloud Storage.
Para aqueles que desejam implementar suas próprias políticas de DR, os backups do ClusterControl são armazenados em um diretório bem estruturado. Você também tem a opção de enviar seu backup para a nuvem. Veja imagem abaixo:
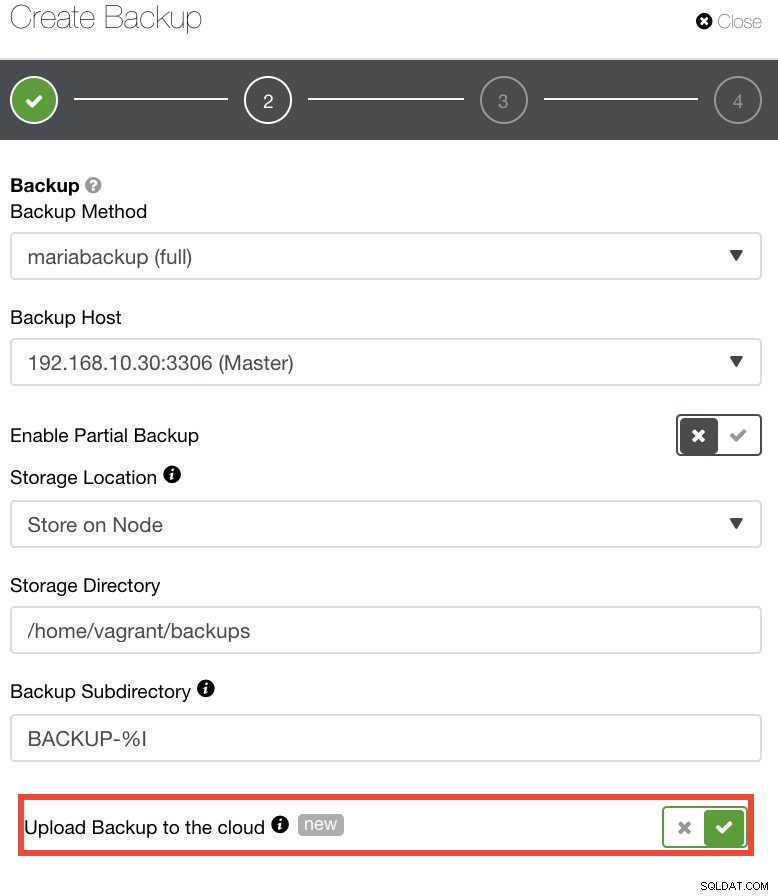
Você pode selecionar e fazer upload para Amazon Web Services, Google Cloud e Microsoft Azure. Veja imagem abaixo:
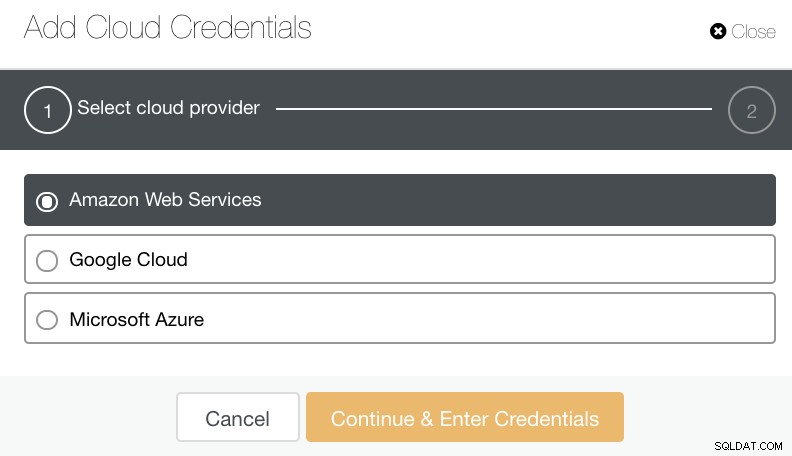
Como uma boa prática ao arquivar seus backups de banco de dados, certifique-se de que seu destino de nuvem de destino seja baseado na mesma região que seus servidores de banco de dados, ou pelo menos a mais próxima. Garanta que ele ofereça alta disponibilidade, durabilidade e escalabilidade; pois você precisa considerar com que frequência e de imediato você precisa de seus dados.
Além de criar um backup lógico ou físico para seu DR, criar um snapshot completo de seus dados (por exemplo, usando LVM Snapshot, Amazon EBS Snapshots ou Volume Snapshots se estiver usando o sistema de arquivos Veritas) no nó específico pode aumentar sua recuperação de backup. Você também pode usar WAL (para Postgres) para seu Point In Time Recovery (PITR) ou seus logs binários do MySQL para seu PITR. Assim, você deve considerar que pode ser necessário criar seu próprio arquivamento para seu PITR. Portanto, não há problema em criar e implantar seu próprio conjunto de scripts e lidar com DR de acordo com seus requisitos exatos.
Outra ótima maneira de implementar uma política de recuperação de desastres é usar um escravo de replicação assíncrona - algo que mencionamos anteriormente nesta postagem do blog. Você pode implantar esse escravo assíncrono em um local remoto, talvez em algum outro data center, e depois usá-lo para fazer backups e armazená-los localmente nesse escravo. Claro, você gostaria de fazer um backup local do seu cluster para tê-lo localmente se precisar recuperar o cluster. A movimentação de dados entre data centers pode levar muito tempo, portanto, ter arquivos de backup disponíveis localmente pode economizar algum tempo. Caso você perca o acesso ao seu cluster de produção principal, ainda poderá ter acesso ao escravo. Essa configuração é muito flexível - primeiro, você tem um host MySQL em execução com seus dados de produção, portanto, não deve ser muito difícil implantar seu aplicativo completo no site de DR. Você também terá backups de seus dados de produção que podem ser usados para expandir seu ambiente de DR.
Por último e mais importante, um backup que não foi testado continua sendo um backup não verificado, também conhecido como Schroedinger Backup. Para garantir que você tenha um backup funcionando, você precisa realizar um teste de recuperação. O ClusterControl oferece uma maneira de verificar e testar automaticamente seu backup.
Esperamos que isso forneça informações suficientes para criar um procedimento de backup seguro e confiável para seus bancos de dados de código aberto.



