As interrupções de produção são quase garantidas em algum momento. Aceitar esse fato e analisar a linha do tempo e o cenário de falha da interrupção do banco de dados pode ajudar a preparar, diagnosticar e recuperar melhor da próxima. Para mitigar o impacto do tempo de inatividade, as organizações precisam de um plano apropriado de recuperação de desastres (DR). O planejamento de DR é uma tarefa crítica para muitos SysOps/DevOps, mas mesmo sendo previsto; muitas vezes não existe.
Nesta postagem do blog, analisaremos diferentes cenários de backup e falha nos sistemas de banco de dados MongoDB. Também orientaremos você pelos procedimentos de recuperação e failover para cada cenário respectivo. Esses casos de uso variam desde a restauração de um único nó, a restauração de um nó em um replicaSet existente e a propagação de um novo nó em um replicaSet. Espero que isso lhe dê uma boa compreensão dos riscos que você pode enfrentar e o que considerar ao projetar sua infraestrutura.
Antes de começarmos a discutir possíveis cenários de falha, vamos dar uma olhada em como o MongoDB armazena dados e quais tipos de backup estão disponíveis.
Como o MongoDB armazena dados
MongoDB é um banco de dados orientado a documentos. Em vez de armazenar seus dados em tabelas feitas de linhas individuais (como faz um banco de dados relacional), ele armazena dados em coleções feitas de documentos individuais. No MongoDB, um documento é um grande blob JSON sem formato ou esquema específico. Além disso, os dados podem ser distribuídos em diferentes nós de cluster com compartilhamento ou replicados para servidores escravos com replicaSet.
MongoDB permite gravações e atualizações muito rápidas por padrão. A desvantagem é que muitas vezes você não é notificado explicitamente sobre falhas. Por padrão, a maioria dos drivers faz gravações assíncronas e inseguras. Isso significa que o driver não retorna um erro diretamente, semelhante a INSERT DELAYED com MySQL. Se você quiser saber se algo foi bem-sucedido, verifique manualmente se há erros usando getLastError.
Para um desempenho ideal, é preferível usar SSD em vez de HDD para armazenamento. É necessário cuidar se o seu armazenamento é local ou remoto e tomar as medidas necessárias. É melhor usar o RAID para proteção de defeitos de hardware e esquemas de recuperação, mas não confie totalmente nele, pois não oferece proteção contra falhas adversas. O hardware certo é o bloco de construção do seu aplicativo para otimizar o desempenho e evitar um grande desastre.
Corrupção de dados no nível do disco ou arquivos de dados ausentes podem impedir que instâncias do mongod sejam iniciadas, e os arquivos de diário podem ser insuficientes para serem recuperados automaticamente.
Se você estiver executando com o journaling ativado, quase nunca há necessidade de executar o reparo, pois o servidor pode usar os arquivos de journal para restaurar os arquivos de dados para um estado limpo automaticamente. No entanto, você ainda pode precisar executar o reparo nos casos em que precisar se recuperar da corrupção de dados no nível do disco.
Se o journaling não estiver habilitado, sua única opção pode ser executar o comando repair. mongod --repair deve ser usado apenas se você não tiver outras opções, pois a operação remove (e não salva) quaisquer dados corrompidos durante o processo de reparo. Este tipo de operação deve ser sempre precedida de backup.
Cenário de recuperação de desastres do MongoDB
Em um plano de recuperação de falhas, seu objetivo de ponto de recuperação (RPO) é um parâmetro de recuperação chave que determina a quantidade de dados que você pode perder. O RPO é listado no tempo, de milissegundos a dias e depende diretamente do seu sistema de backup. Ele considera a idade dos dados de backup que você deve recuperar para retomar as operações normais.
Para estimar o RPO, você precisa se fazer algumas perguntas. Quando é feito o backup dos meus dados? Qual é o SLA associado à recuperação dos dados? A restauração de um backup dos dados é aceitável ou os dados precisam estar online e prontos para serem consultados a qualquer momento?
As respostas a essas perguntas ajudarão a determinar que tipo de solução de backup você precisa.
Soluções de backup do MongoDB
As técnicas de backup têm impactos variados no desempenho do banco de dados em execução. Algumas soluções de backup degradam o desempenho do banco de dados o suficiente para que você precise agendar backups para evitar picos de uso ou janelas de manutenção. Você pode decidir implantar novos servidores secundários apenas para oferecer suporte a backups.
As três soluções mais comuns para fazer backup de seu servidor/cluster MongoDB são...
- Mongodump/Mongorestore - backup lógico.
- Mongo Management System (Cloud) - Os bancos de dados de produção podem ser copiados usando o MongoDB Ops Manager ou, se estiver usando o serviço MongoDB Atlas, você pode usar uma solução de backup totalmente gerenciada.
- Instantâneos do banco de dados (backup em nível de disco)
Mongodump/Mongorestore
Ao executar um mongodump, todas as coleções nos bancos de dados designados serão despejadas como saída BSON. Se nenhum banco de dados for especificado, o MongoDB despejará todos os bancos de dados, exceto os bancos de dados administrativo, de teste e local, pois são reservados para uso interno.
Por padrão, o mongodump criará um diretório chamado dump, com um diretório para cada banco de dados contendo um arquivo BSON por coleção nesse banco de dados. Alternativamente, você pode dizer ao mongodump para armazenar o backup em um único arquivo morto. O parâmetro archive concatenará a saída de todos os bancos de dados e coleções em um único fluxo de dados binários. Além disso, o parâmetro gzip pode comprimir naturalmente este arquivo, usando gzip. No ClusterControl, transmitimos todos os nossos backups, então habilitamos os parâmetros archive e gzip.
Semelhante ao mysqldump com MySQL, se você criar um backup no MongoDB, ele congelará as coleções enquanto despeja o conteúdo no arquivo de backup. Como o MongoDB não suporta transações (alterado na versão 4.2), você não pode fazer um backup 100% totalmente consistente a menos que crie o backup com o parâmetro oplog. Habilitar isso no backup inclui as transações do oplog que estavam em execução durante o backup.
Para melhor automação e Você pode executar o MongoDB a partir da linha de comando ou usar ferramentas externas como ClusterControl. O ClusterControl é uma opção recomendada para gerenciamento de backup e automação de backup, pois permite criar estratégias avançadas de backup para vários sistemas de banco de dados de código aberto.
ClusterControl permite que você carregue seu backup na nuvem. Ele suporta backup completo e restaura a criptografia do mongodump. Se você quiser ver como funciona, há uma demonstração em nosso site.
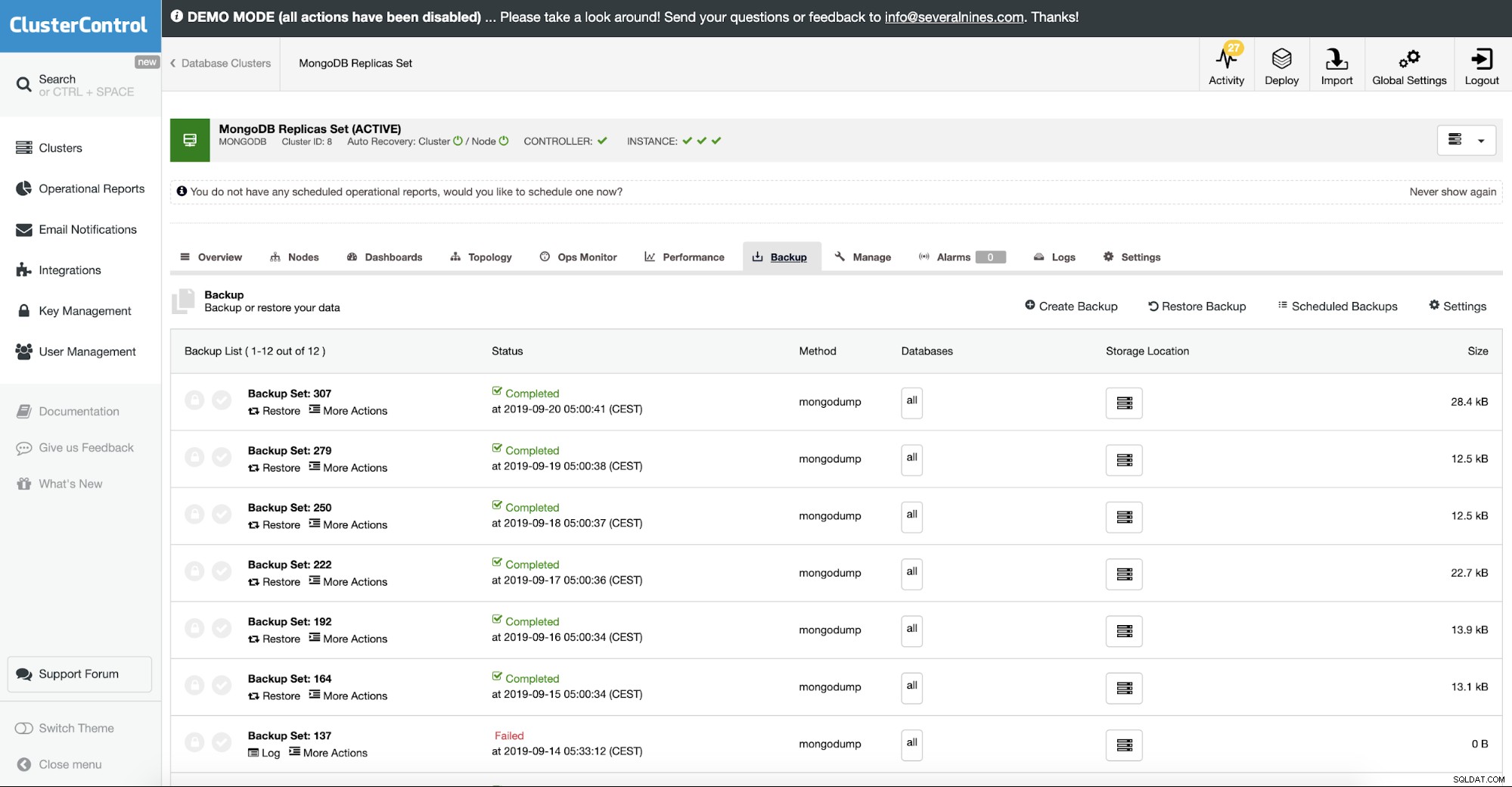
Restaurando o MongoDB de um backup
Existem basicamente duas maneiras de usar um dump no formato BSON:
- Execute o mongod diretamente do diretório de backup
- Execute o mongorestore e restaure o backup
Execute o mongod diretamente de um backup
Um pré-requisito para executar o mongod diretamente do backup é que o destino do backup seja um dump padrão e não esteja compactado em gzip.
O daemon do MongoDB irá então verificar a integridade do diretório de dados, adicionar o banco de dados admin, diários, coleção e catálogos de índice e alguns outros arquivos necessários para executar o MongoDB. Se você executou o WiredTiger como o mecanismo de armazenamento antes, ele agora executará as coleções existentes como MMAP. Para despejos de dados simples ou verificações de integridade, isso funciona bem.
Executando o mongorestore
Uma maneira melhor de restaurar seria obviamente restaurando o nó usando um mongorestore.
mongorestore dump/Isso restaurará o backup nas configurações padrão do servidor (localhost, porta 27017) e substituirá todos os bancos de dados no backup que residam neste servidor. Agora, existem vários parâmetros para manipular o processo de restauração e abordaremos alguns dos mais importantes.
No ClusterControl isso é feito na opção de backup de restauração. Você pode escolher a máquina em que o backup será restaurado e processar o resto. Isso inclui backup criptografado onde normalmente você também precisaria descriptografar seu backup.
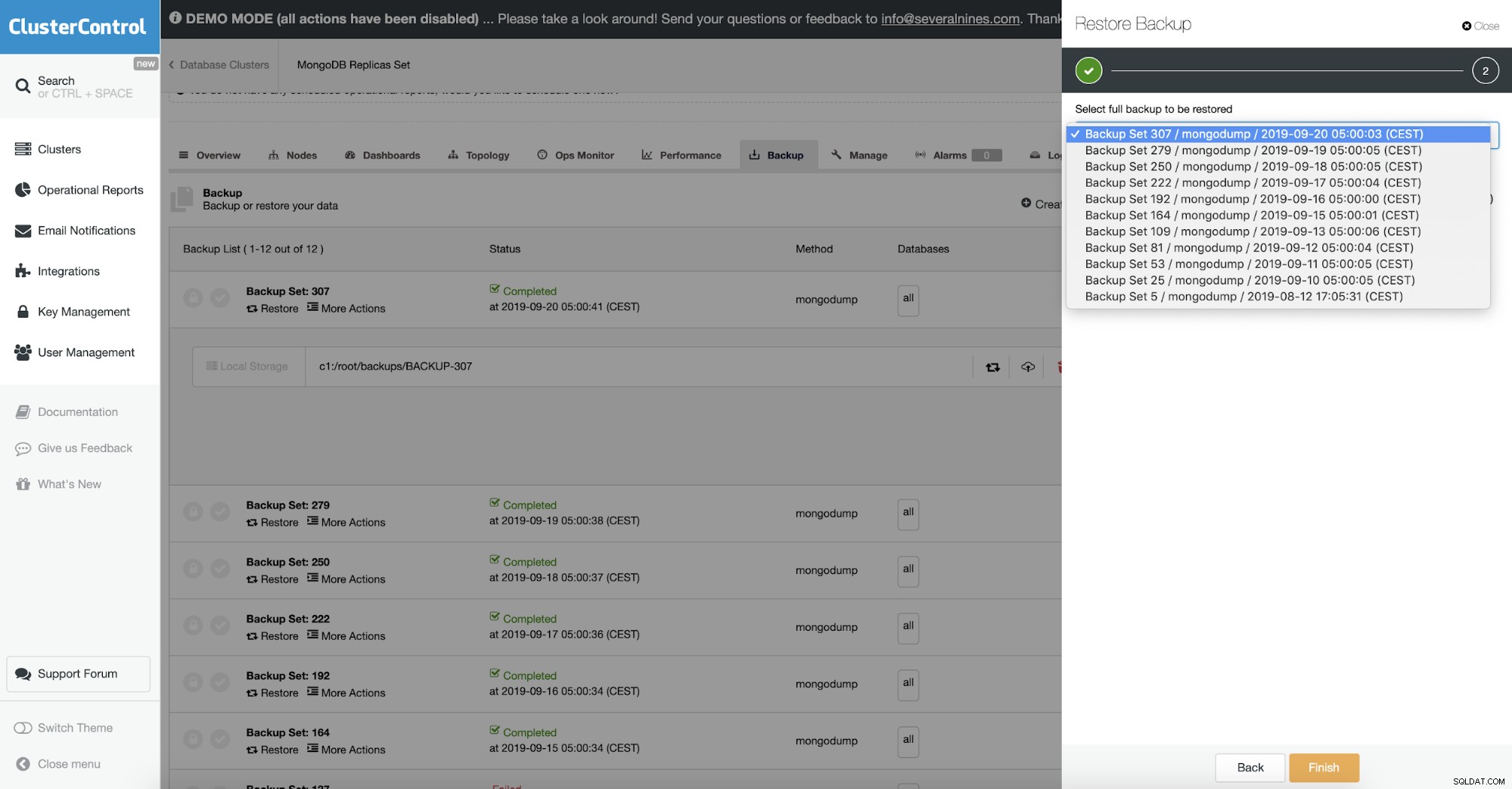
Validação de objeto
Como o backup contém dados BSON, você espera que o conteúdo do backup esteja correto. No entanto, pode ter sido o caso de o documento que foi despejado estar malformado, para começar. O Mongodump não verifica a integridade dos dados que despeja.
Para resolver esse uso -- objcheck que força o mongorestore a validar todas as solicitações dos clientes no recebimento para garantir que os clientes nunca insiram documentos inválidos no banco de dados. Pode ter um pequeno impacto no desempenho.
Oplog Replay
Oplog para seu backup permitirá que você execute um backup consistente e faça uma recuperação pontual. Ative o parâmetro oplogReplay para aplicar o oplog durante o processo de restauração. Para controlar até onde reproduzir o oplog, você pode definir um timestamp no parâmetro oplogLimit. Somente as transações até o carimbo de data/hora serão aplicadas.
Restaurando um conjunto de réplicas completo de um backup
Restaurar um replicaSet não é muito diferente de restaurar um único nó. Ou você precisa configurar o replicaSet primeiro e restaurar diretamente no replicaSet. Ou você restaura um único nó primeiro e depois usa esse nó restaurado para construir um replicaSet.
Restaure o nó primeiro, depois crie replicaSet
Agora, o segundo e o terceiro nós sincronizarão seus dados do primeiro nó. Após a conclusão da sincronização, nosso replicaSet foi restaurado.
Crie um ReplicaSet primeiro e depois restaure
Diferente do processo anterior, você pode criar o replicaSet primeiro. Primeiro configure todos os três hosts com o replicaSet habilitado, inicie todos os três daemons e inicie o replicaSet no primeiro nó:
Agora que criamos o replicaSet, podemos restaurar diretamente nosso backup nele:
Em nossa opinião, restaurar um replicaSet dessa maneira é muito mais elegante. É mais próximo da maneira como você normalmente configuraria um novo replicaSet do zero e o preencheria com dados (de produção).
Semeando um novo nó em um ReplicaSet
Ao dimensionar um cluster adicionando um novo nó no MongoDB, a sincronização inicial do conjunto de dados deve ocorrer. Com a replicação do MySQL e o Galera, estamos tão acostumados a usar um backup para propagar a sincronização inicial. Com o MongoDB isso é possível, mas apenas fazendo uma cópia binária do diretório de dados. Se você não tiver os meios para fazer um instantâneo do sistema de arquivos, terá que enfrentar o tempo de inatividade em um dos nós existentes. O processo, com tempo de inatividade, é descrito abaixo.
Semeando com um backup
Então, o que aconteceria se você restaurasse o novo nó de um backup do mongodump e, em seguida, ingressasse em um replicaSet? A restauração de um backup deve, em teoria, fornecer o mesmo conjunto de dados. Como esse novo nó foi restaurado a partir de um backup, ele não terá o replicaSetId e o MongoDB notará. Como o MongoDB não vê esse nó como parte do replicaSet, o comando rs.add() sempre acionará a sincronização inicial do MongoDB. A sincronização inicial sempre acionará a exclusão de quaisquer dados existentes no nó MongoDB.
O replicaSetId é gerado ao iniciar um replicaSet e, infelizmente, não pode ser definido manualmente. Isso é uma pena, pois a recuperação de um backup (incluindo a repetição do oplog) teoricamente nos daria um conjunto de dados 100% idêntico. Seria bom se a sincronização inicial fosse opcional no MongoDB para satisfazer este caso de uso.



