Outra opção:
SELECT TEST, row_number() OVER (PARTITION BY TEST ORDER BY TEST) FROM TEST1
MINUS
SELECT TEST, row_number() OVER (PARTITION BY TEST ORDER BY TEST) FROM TEST2
Isso seria MENOS com cada duplicata tratada como uma entrada distinta. Observe no exemplo abaixo, se TEST1 tiver dois valores 'C' e TEST2 tiver apenas um, você obterá um na saída.
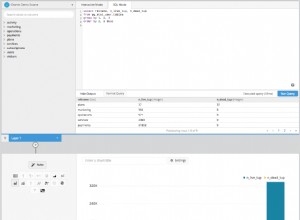
dev> select * from test1;
T
-
A
A
B
C
C
dev> select * from test2;
T
-
B
C
dev> SELECT TEST, row_number() OVER (PARTITION BY TEST ORDER BY TEST) FROM TEST1
2 MINUS
3 SELECT TEST, row_number() OVER (PARTITION BY TEST ORDER BY TEST) FROM TEST2
4 /
T ROW_NUMBER()OVER(PARTITIONBYTESTORDERBYTEST)
- --------------------------------------------
A 1
A 2
C 2