Em postagens anteriores do blog, abordamos tópicos para monitorar seu cluster Galera, seja MySQL ou MariaDB. Embora as versões de tecnologia não sejam muito diferentes, o MariaDB Cluster tem algumas mudanças importantes desde a versão 10.4.2. Nesta versão, ele oferece suporte ao Galera Cluster 4 e possui alguns ótimos novos recursos que veremos neste post do blog.
Para iniciantes que ainda não estão familiarizados com o MariaDB Cluster, é um cluster multimestre praticamente síncrono para MariaDB. Ele está disponível apenas no Linux e suporta apenas os mecanismos de armazenamento XtraDB/InnoDB (embora haja suporte experimental para MyISAM - consulte a variável de sistema wsrep_replicate_myisam).
O software é um pacote de tecnologia que é desenvolvido pelo MariaDB Server, patch MySQL-wsrep para MySQL Server e MariaDB Server desenvolvido pela Codership (suporta SO semelhante ao Unix) e a biblioteca do provedor Galera wsrep.
Você pode comparar este produto com o MySQL Group Replication ou com o MySQL InnoDB Cluster, que visa fornecer alta disponibilidade. (Embora eles diferem de forma diversa em princípios e abordagens para fornecer HA.)
Agora que abordamos o básico, neste blog, forneceremos dicas que consideramos úteis ao monitorar seu cluster MariaDB.
Os fundamentos do cluster MariaDB
Quando você começa a usar o MariaDB Cluster, você precisa identificar exatamente qual é o seu propósito e por que você escolheu o MariaDB Cluster em primeiro lugar. Primeiro você precisa digerir quais são os recursos e seus benefícios ao usar o MariaDB Cluster. A razão para identificá-los é porque eles são essencialmente o que precisa ser monitorado e verificado para que você determine o desempenho, as condições normais de saúde e se está funcionando de acordo com seus planos.
Essencialmente, é identificado como sem atraso de escravo, sem transações perdidas, escalabilidade de leitura e latências de cliente menores. Em seguida, podem surgir perguntas como, como isso não causa atraso no escravo ou transações perdidas? Como torna a leitura escalável ou com latências menores no lado do cliente? Essas áreas são uma das principais áreas que você precisa observar e monitorar especialmente para uso em produção pesada.
Embora o próprio MariaDB Cluster possa ser personalizado de acordo. Aplicar alterações no comportamento padrão, como pc.weight ou pc.ignore_quorum, ou mesmo usar multicast com UDP para um grande número de nós, pode afetar a maneira como você monitora a natureza do seu cluster MariaDB. Mas, por outro lado, as variáveis de status mais essenciais geralmente são o lado positivo aqui, sabendo que o estado e o fluxo do cluster estão indo bem ou se degradando, mostrando um possível problema que leva a uma falha catastrófica de antemão.
Sempre monitore a atividade do servidor (rede, disco, carga, memória e CPU)
Monitorar a atividade do servidor também pode ser uma tarefa complexa se você tiver uma pilha muito complicada que está entrelaçada na arquitetura do banco de dados. No entanto, para um cluster MariaDB, é sempre melhor ter seus nós sempre configurados da forma mais dedicada e simples possível. Embora isso não o limite de usar todos os recursos sobressalentes, abaixo estão as áreas-chave comuns que você deve analisar.
Rede
O Galera Cluster 4 apresenta a replicação de streaming como um dos principais recursos e alterações da versão anterior. Como a replicação de streaming resolve as desvantagens que tinha nas versões anteriores, mas permite gerenciar mais de 2 GB de conjuntos de gravação desde o Galera Cluster 4. Isso permite que grandes transações sejam fragmentadas e é altamente recomendável habilitá-lo apenas durante o nível de sessão. Isso significa que monitorar sua atividade de rede é muito importante e crucial para a atividade normal do seu cluster MariaDB. Isso ajudará você a identificar qual nó teve o maior ou o maior tráfego de rede com base no período de tempo.
Então, como isso o ajudará a melhorar onde os nós com maior tráfego de rede foram identificados? Bem, isso oferece espaço para melhorias na topologia do banco de dados ou na camada de arquitetura do cluster de banco de dados. O uso de balanceadores de carga ou um proxy de banco de dados permite configurar proativamente o tráfego do banco de dados, especialmente ao determinar quais gravações específicas devem ir para um nó específico. Digamos que dos 3 nós, um deles é mais capaz de lidar com grandes e grandes consultas devido a diferenças com as especificações de hardware. Isso permite que você gerencie mais capex e melhore seu planejamento de capacidade conforme as demandas em um determinado período de tempo mudam.
Disco
Como a atividade de rede também é importante para o desempenho do disco, especialmente durante o tempo de liberação. Também é melhor determinar o desempenho do tempo comprometido e da recuperação quando a alta carga de pico é atingida. Há momentos em que você estoca seu host de banco de dados não apenas sendo dedicado a uma atividade do Galera Cluster, mas também combinando outras ferramentas como docker, proxies SQL, como ProxySQL ou MaxScale. Isso lhe dá controle com servidores de baixa carga e permite que você use os recursos sobressalentes disponíveis que podem ser utilizados para outros fins benéficos, especialmente para sua pilha de arquitetura de banco de dados. Depois de determinar qual nó no monitoramento tem a carga mais baixa, mas ainda é capaz de gerenciar sua utilização de E/S de disco, você pode selecionar o nó específico enquanto observa o tempo passar. Novamente, isso ainda oferece um melhor gerenciamento com seu planejamento de capacidade.
CPU, memória e atividade de carga
Deixe-me colocar brevemente essas três áreas a serem observadas durante o monitoramento. Nesta seção, é sempre melhor que você tenha uma melhor observabilidade das seguintes áreas de uma só vez. É mais rápido e fácil de entender, especialmente descartando um gargalo de desempenho ou identificando bugs que fazem com que seus nós parem e que também podem afetar os outros nós e a possibilidade de cair no cluster.
Então, como CPU, memória e atividade de carga durante o monitoramento ajudam seu cluster MariaDB? Bem, como eu mencionei acima, essas são uma das poucas coisas ainda um grande fator para verificações de rotina diária. Agora, isso também ajuda a identificar se são ocorrências periódicas ou aleatórias. Se periódico, pode estar relacionado a backups executados em um de seus nós Galera ou é uma consulta enorme que requer otimização. Por exemplo, consultas inválidas sem índices adequados ou uso desequilibrado de recuperação de dados, como fazer uma comparação de string para uma string tão grande. Isso pode ser inegavelmente inaplicável para bancos de dados do tipo OLTP, como o MariaDB Cluster, especialmente se for realmente a natureza e os requisitos do seu aplicativo. Melhor usar outras ferramentas analíticas, como MariaDB Columnstore, ou outras ferramentas de processamento analítico de terceiros (Apache Spark, Kafka ou MongoDB, etc.) para recuperação de dados de strings grandes e/ou correspondência de strings.
Então, com todas essas áreas-chave sendo monitoradas, a questão é:como isso deve ser monitorado? Tem que ser monitorado pelo menos por minuto. Com monitoramento refinado, ou seja, por segundo de métricas coletivas pode ser intensivo em recursos e muito ganancioso em termos de seus recursos. Embora meio minuto de coletividade seja aceitável, especialmente se seus dados e RPO (objetivo de ponto de recuperação) forem muito baixos, você precisa de métricas de dados mais granulares e em tempo real. É muito importante que você seja capaz de supervisionar toda a imagem do cluster de banco de dados. Além disso, também é melhor e importante que, sempre que as métricas que você estiver monitorando, você tenha a ferramenta certa para chamar sua atenção quando as coisas estiverem em perigo ou mesmo apenas avisos. O uso da ferramenta adequada, como o ClusterControl, ajuda a gerenciar essas áreas-chave a serem monitoradas. Estou usando aqui uma versão gratuita ou edição da comunidade do ClusterControl e me ajuda a monitorar meus nós sem nenhum incômodo desde a instalação até o monitoramento de nós com apenas alguns cliques. Por exemplo, veja as capturas de tela abaixo:

A visualização é uma visão geral mais refinada e rápida do que está acontecendo atualmente. Um gráfico mais granular também pode ser usado,
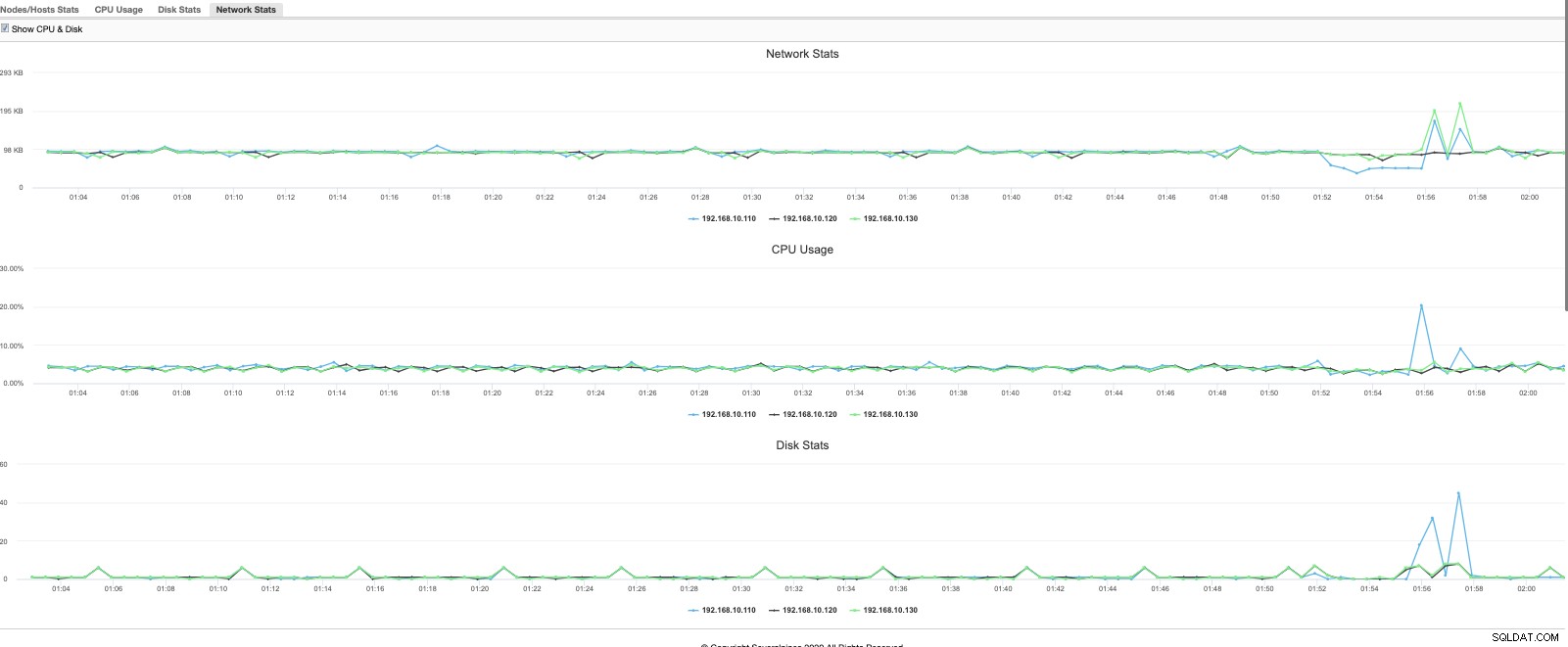
ou com um modelo de dados mais poderoso e rico que também suporta linguagem de consulta pode fornecer a você uma análise do desempenho do seu cluster MariaDB com base em dados históricos comparando seu desempenho em tempo hábil. Por exemplo,
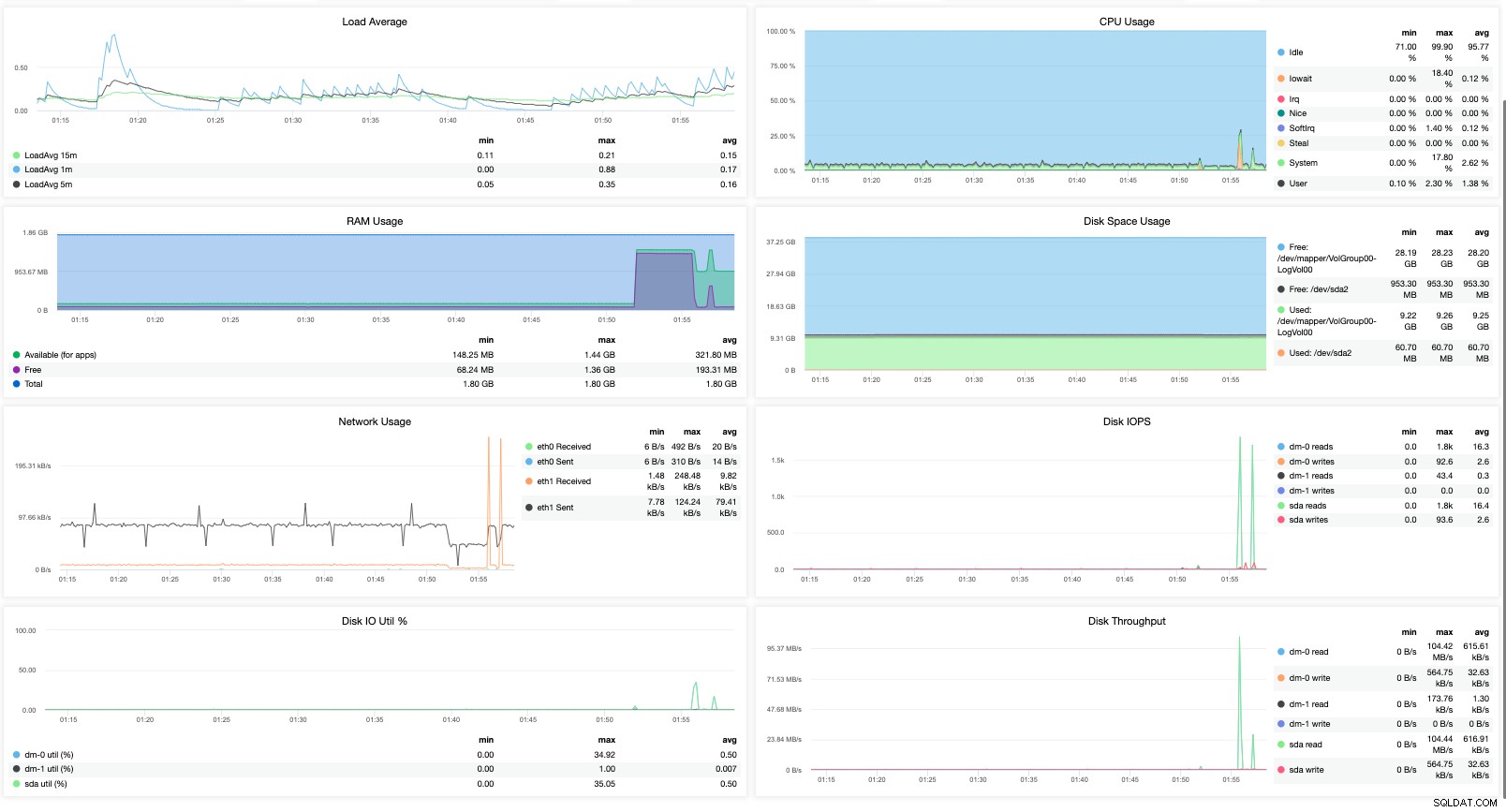
Isso apenas fornece métricas mais visíveis. Assim você vê o quão importante é realmente ter a ferramenta certa ao monitorar seu MariaDB Cluster.
Garantir o monitoramento coletivo de suas variáveis estatísticas de cluster MariaDB
De tempos em tempos, não pode ser inevitável que as versões do MariaDB Cluster produzam novas estatísticas para monitorar ou aprimorar a natureza do monitoramento do banco de dados, fornecendo mais variáveis de status e valores refinados a serem observados. Conforme mencionei acima, estou usando o ClusterControl para monitorar meus nós neste blog de exemplo. No entanto, isso não significa que é a melhor ferramenta disponível. Quero dizer, o PMM da Percona é muito rico quando se trata de monitoramento coletivo para cada variável estatística que sempre que o MariaDB Cluster tiver variáveis estatísticas mais recentes para oferecer, você pode aproveitar isso e também alterá-lo, pois o PMM é uma ferramenta de código aberto. É uma grande vantagem que você também tenha toda a visibilidade do seu MariaDB Cluster, pois cada aspecto conta especialmente em um banco de dados baseado em produção que atende a centenas de milhares de solicitações por minuto.
Mas vamos ser mais específicos sobre o problema aqui. Quais são essas variáveis estatísticas para analisar? Há muitos com os quais contar para um MariaDB Cluster, mas focando novamente nos recursos e benefícios que acreditamos que você usa o MariaDB Cluster no que ele tem a oferecer, então nos concentraremos nisso.
Galera Cluster - Controle de fluxo
O controle de fluxo do seu cluster MariaDB fornece uma visão geral de como a integridade da replicação funciona em todo o cluster. O processo de replicação no Galera Cluster usa um mecanismo de feedback, o que significa que ele sinaliza para todos os nós desse cluster e sinaliza se o nó deve pausar ou retomar a replicação de acordo com suas necessidades. Isso também evita que qualquer nó fique muito atrasado enquanto os outros estão aplicando as transações recebidas. É assim que o controle de fluxo cumpre sua função dentro do Galera. Agora, isso precisa ser visto e não deve ser negligenciado ao monitorar seu cluster MariaDB. Isso, como mencionado em um dos benefícios ao usar o MariaDB Cluster, é evitar o atraso do escravo. Embora seja muito ingênuo entender sobre o controle de fluxo e o atraso do escravo, mas com controle de fluxo, isso afetará o desempenho do seu cluster Galera quando houver muita fila e confirmações ou liberação de páginas para o disco for muito baixa para esses problemas de disco ou é apenas a consulta em execução é uma consulta ruim. Se você é um iniciante em como o Galera funciona, você pode estar interessado em ler este post externo sobre o que é controle de fluxo no Galera.
Bytes enviados/recebidos
Os bytes enviados ou recebidos correlacionam-se com a atividade de rede e até mesmo é uma das áreas-chave a serem observadas lado a lado com o controle de fluxo. Isso permite determinar qual nó é o mais impactado ou atribuído aos problemas de desempenho que estão sofrendo em seu Galera Cluster. É muito importante, pois você pode verificar se pode haver alguma degradação em termos de hardware, como seu dispositivo de rede ou o dispositivo de armazenamento subjacente, para o qual a sincronização de páginas sujas pode levar muito tempo para ser feita.
Carregamento de cluster
Bem, isso é mais a atividade do banco de dados de quantas alterações ou recuperação de dados foram consultadas ou feitas até agora desde o tempo de atividade do servidor. Ele ajuda a descartar quais tipos de consultas estão afetando principalmente o desempenho do cluster de banco de dados. Isso permite que você forneça espaço para melhorias, especialmente no balanceamento da carga de suas solicitações de banco de dados. O uso do ProxySQL ajuda você com uma abordagem mais refinada e granular para roteamento de consulta. Embora o MaxScale também ofereça esse recurso, o ProxySQL tem mais granularidade, embora também tenha algum impacto ou custo no desempenho. O impacto ocorre quando você tem apenas um ProxySQL como proxy SQL para resolver o roteamento de consulta e pode ser difícil quando o tráfego intenso está em andamento. Tendo custo, se você adicionar mais nós ProxySQL para equilibrar mais o tráfego que um KeepAlived subjacente. Embora, este seja um combo perfeito, mas pode ser executado a baixo custo até que seja necessário. No entanto, como você será capaz de determinar se necessário, certo? Essa é a questão que permanece aqui, portanto, um olhar atento para monitorar essas áreas-chave é muito importante, não apenas para observabilidade, mas também para melhorar o desempenho de seu cluster de banco de dados com o passar do tempo.
Dessa forma, existem muitas variáveis a serem observadas em um cluster MariaDB. A coisa mais importante aqui que você deve levar em consideração é a ferramenta que você está usando para monitorar seu cluster de banco de dados. Como mencionado anteriormente, prefiro usar a licença de versão gratuita do ClusterControl (Community Edition) aqui neste blog, pois ela me fornece mais formas de flexibilidade para olhar em um Galera Cluster. Veja o exemplo abaixo,
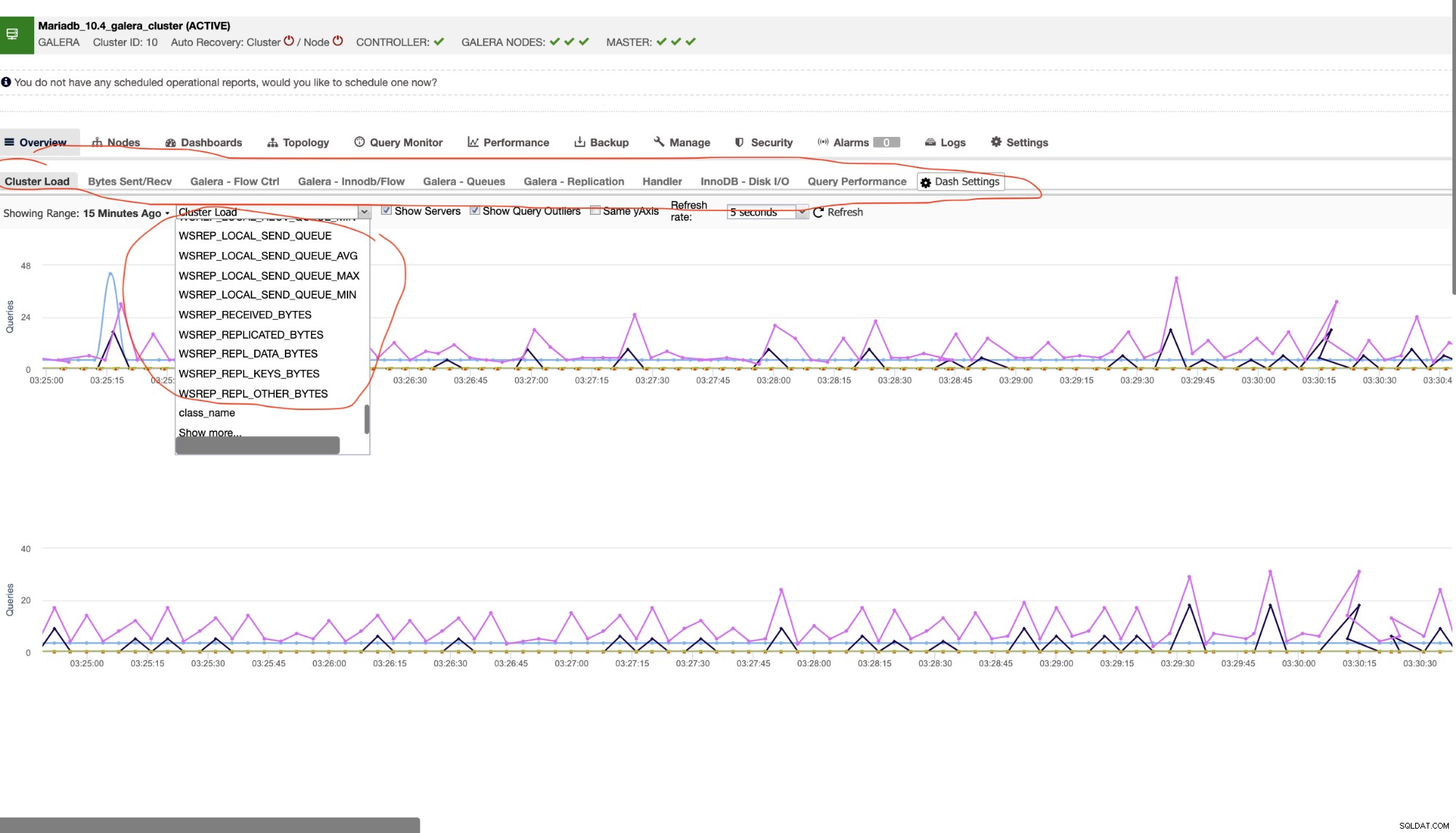
Marquei ou circulei em vermelho as guias que me permitem supervisionar visualmente a saúde do meu cluster MariaDB. Digamos que, se seu aplicativo for ganancioso ao usar replicação de streaming de tempos em tempos e enviar um grande número de fragmentos (transferência de rede grande) para interatividade de cluster, é melhor determinar o quão bem seus nós podem lidar com o estresse. Especialmente durante o teste de estresse antes de enviar alterações específicas em seu aplicativo, é sempre melhor tentar e testar para determinar o gerenciamento de capacidade de seu produto de aplicativo e determinar se seus nós e design de banco de dados atuais podem lidar com a carga de seus requisitos de aplicativo.
Mesmo em uma edição comunitária do ClusterControl, consigo reunir resultados granulares e mais refinados da integridade do meu Cluster MariaDB. Ver abaixo,
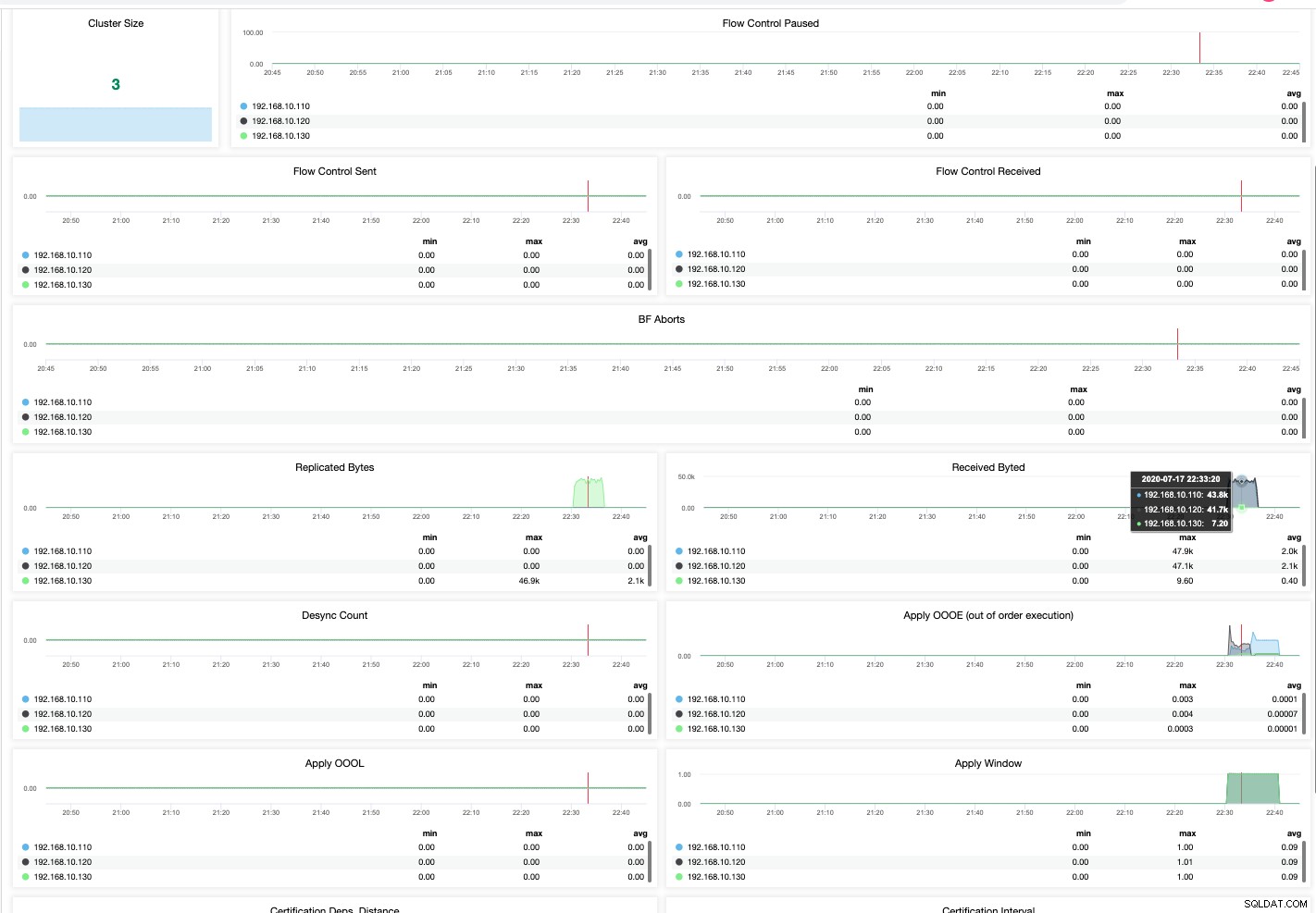
É assim que você deve abordar o monitoramento do seu Cluster MariaDB. Uma visualização perfeita é sempre mais fácil e rápida de gerenciar. Quando as coisas dão errado, você não pode perder sua produtividade e também o tempo de inatividade pode afetar seus negócios. Embora o acesso gratuito não forneça o luxo e o conforto ao gerenciar bancos de dados de alto tráfego, ter alarmes, notificações e gerenciamento de banco de dados em uma área é um complemento fácil de usar que o ClusterControl pode fazer.
Conclusão
O MariaDB Cluster não é tão simples de monitorar em comparação com as configurações tradicionais assíncronas de mestre-escravo do MySQL/MariaDB. Funciona de forma diferente e você deve ter as ferramentas certas para determinar o que está acontecendo e o que está acontecendo em seu cluster de banco de dados. Sempre prepare seu planejamento de capacidade com antecedência antes de executar seu cluster MariaDB sem o monitoramento adequado de antemão. É sempre melhor que a carga e a atividade do banco de dados sejam conhecidas antes de um evento catastrófico.



