
Este post faz parte do tutorial Oracle SQL e estaríamos discutindo funções analíticas no oracle (Over by partition) com exemplos, explicação detalhada.
Já estudamos sobre a função Oracle Aggregate como avg ,sum ,count. Vamos dar um exemplo
Primeiro vamos criar os dados de amostra
CREATE TABLE "DEPT"
( "DEPTNO" NUMBER(2,0),
"DNAME" VARCHAR2(14),
"LOC" VARCHAR2(13),
CONSTRAINT "PK_DEPT" PRIMARY KEY ("DEPTNO")
)
CREATE TABLE "EMP"
( "EMPNO" NUMBER(4,0),
"ENAME" VARCHAR2(10),
"JOB" VARCHAR2(9),
"MGR" NUMBER(4,0),
"HIREDATE" DATE,
"SAL" NUMBER(7,2),
"COMM" NUMBER(7,2),
"DEPTNO" NUMBER(2,0),
CONSTRAINT "PK_EMP" PRIMARY KEY ("EMPNO"),
CONSTRAINT "FK_DEPTNO" FOREIGN KEY ("DEPTNO")
REFERENCES "DEPT" ("DEPTNO") ENABLE
);
SQL> desc emp
Name Null? Type
---- ---- -----
EMPNO NOT NULL NUMBER(4)
ENAME VARCHAR2(10)
JOB VARCHAR2(9)
MGR NUMBER(4)
HIREDATE DATE
SAL NUMBER(7,2)
COMM NUMBER(7,2)
DEPTNO NUMBER(2)
SQL> desc dept
Name Null? Type
---- ----- ----
DEPTNO NOT NULL NUMBER(2)
DNAME VARCHAR2(14)
LOC VARCHAR2(13)
insert into DEPT values(10, 'ACCOUNTING', 'NEW YORK');
insert into dept values(20, 'RESEARCH', 'DALLAS');
insert into dept values(30, 'RESEARCH', 'DELHI');
insert into dept values(40, 'RESEARCH', 'MUMBAI');
commit;
insert into emp values( 7839, 'Allen', 'MANAGER', 7839, to_date('17-11-1981','dd-mm-yyyy'), 20, null, 10 );
insert into emp values( 7782, 'CLARK', 'MANAGER', 7839, to_date('9-06-1981','dd-mm-yyyy'), 0, null, 10 );
insert into emp values( 7934, 'MILLER', 'MANAGER', 7839, to_date('23-01-1982','dd-mm-yyyy'), 0, null, 10 );
insert into emp values( 7788, 'SMITH', 'ANALYST', 7788, to_date('17-12-1980','dd-mm-yyyy'), 800, null, 20 );
insert into emp values( 7902, 'ADAM, 'ANALYST', 7832, to_date('23-05-1987','dd-mm-yyyy'), 1100, null, 20 );
insert into emp values( 7876, 'FORD', 'ANALYST', 7566, to_date('3-12-1981','dd-mm-yyyy'), 3000, null, 20 );
insert into emp values( 7369, 'SCOTT', 'ANALYST', 7566, to_date('19-04-1987','dd-mm-yyyy'), 3000, null, 20 );
insert into emp values( 7698, 'JAMES', 'ANALYST', 7788, to_date('03-12-1981','dd-mm-yyyy'), 950, null, 30 );
insert into emp values( 7499, 'MARTIN', 'ANALYST', 7698, to_date('28-09-1981','dd-mm-yyyy'), 1250, null, 30 );
insert into emp values( 7844, 'WARD', 'ANALYST', 7698, to_date('22-02-1981','dd-mm-yyyy'), 1250, null, 30 );
insert into emp values( 7654, 'TURNER', 'ANALYST', 7698, to_date('08-09-1981','dd-mm-yyyy'), 1500, null, 30 );
insert into emp values( 7521, 'ALLEN', 'ANALYST', 7698, to_date('20-02-1981','dd-mm-yyyy'), 1600, null, 30 );
insert into emp values( 7900, 'BLAKE', 'ANALYST', 77698, to_date('01-05-1981','dd-mm-yyyy'), 2850, null, 30 );
commit;
Agora o exemplo de funções agregadas será dado como abaixo
select count(*) from EMP; --------- 13 select sum (bytes) from dba_segments where tablespace_name='TOOLS'; ----- 100 SQL> select deptno ,count(*) from emp group by deptno; DEPTNO COUNT(*) ---------- ---------- 30 6 20 4 10 3
Aqui podemos ver que reduz o número de linhas em cada uma das consultas. Agora vem as perguntas o que fazer se precisarmos ter todas as linhas retornadas com count(*) também
Para esse oráculo forneceu um conjunto de funções analíticas. Então, para resolver o último problema, podemos escrever como
select empno ,deptno , count(*) over (partition by deptno) from emp group by deptno;
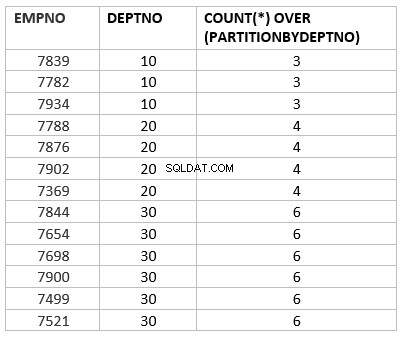
Aqui count(*) over (partição por dept_no) é a versão analítica da função de agregação de contagem. O principal trabalho de chave que é diferente por função agregada é sobre partição por
As funções analíticas calculam um valor agregado com base em um grupo de linhas. Eles diferem das funções de agregação porque retornam várias linhas para cada grupo. O grupo de linhas é chamado de janela e é definido pela cláusula_analítica.
Aqui está a sintaxe geral
analytic_function([ arguments ]) OVER ([ query_partition_clause ] [ order_by_clause [ windowing_clause ] ])
Exemplo
count(*) over (partition by deptno) avg(Sal) over (partition by deptno)
Vamos repassar cada parte
query_partition_clause
Definiu o grupo de linhas. Pode gostar abaixo
partição por deptno :grupo de linhas do mesmo deptno
ou
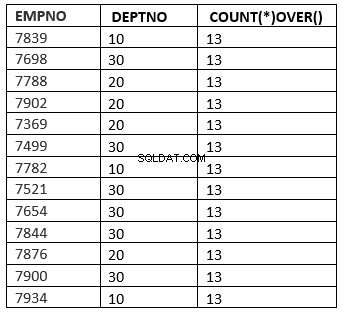
() :Todas as linhas
SQL> select empno ,deptno , count(*) over () from emp;
[ order_by_clause [ windowing_clause ] ]
Essa cláusula é usada quando você deseja ordenar as linhas na partição. Isso é particularmente útil se você quiser que a função analítica considere a ordem das linhas.
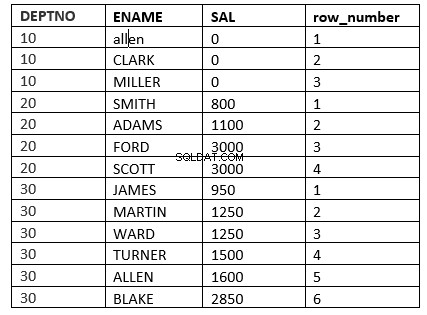
O exemplo será a função row_number
SQL> select deptno, ename, sal, row_number() over (partition by deptno order by sal) "row_number" from emp;
Outro exemplo seria
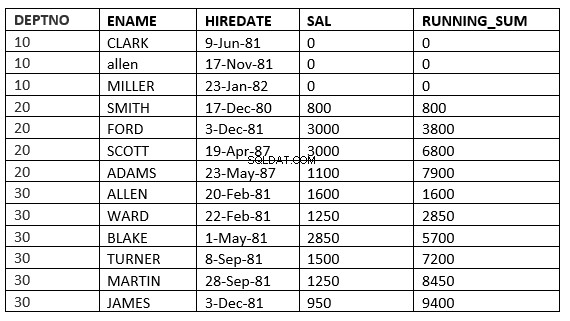
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE) running_sum from emp;
Cláusula_de janela
Isso é sempre usado com a cláusula order by e dá mais controle sobre o conjunto de linhas do grupo
Com a cláusula Windowing, para cada linha, é definida uma janela deslizante de linhas. A janela determina o intervalo de linhas usado para realizar os cálculos para a linha atual. Os tamanhos das janelas podem ser baseados em um número físico de linhas ou em um intervalo lógico, como tempo.
Ao usar a cláusula order by e nada é fornecido para windowing_clause, abaixo do valor padrão da windowing_clause é tomado partição são as linhas que devem ser usadas na computação”
O exemplo abaixo mostra isso claramente. Essa é a média corrente no departamento
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE) running_sum from emp;
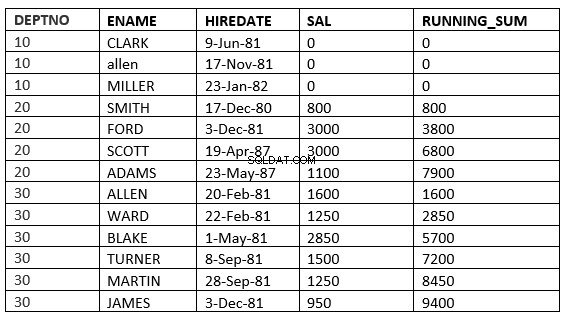
Agora windowing_clause pode ser definido de várias maneiras
Vamos primeiro entender a terminologia
LINHAS especifica a janela em unidades físicas (linhas).
RANGE especifica a janela como um deslocamento lógico. a cláusula de janela RANGE pode ser usada apenas com cláusulas ORDER BY contendo colunas ou expressões de tipos de dados numéricos ou de data
PRECEDING – obter linhas antes da atual.
SEGUINDO – obter linhas após a atual.
UNBOUNDED – quando usado com PRECEDING ou FOLLOWING, retorna tudo antes ou depois. LINHA ATUAL
Portanto, geralmente é definido como
LINHAS ANTERIORES ILIMITADAS :As linhas atuais e anteriores na partição atual são as linhas que devem ser usadas no cálculo
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE ROWS UNBOUNDED PRECEDING) running_sum from emp;
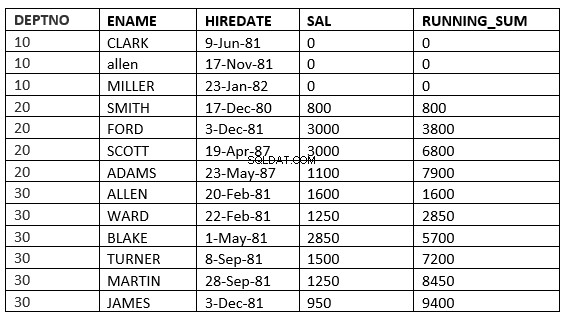
ALCANCE ILIMITADO ANTERIOR :As linhas atuais e anteriores na partição atual são as linhas que devem ser usadas no cálculo. Além disso, como o intervalo é especificado, todos os valores são iguais às linhas atuais.
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE RANGE UNBOUNDED PRECEDING) running_sum from emp;
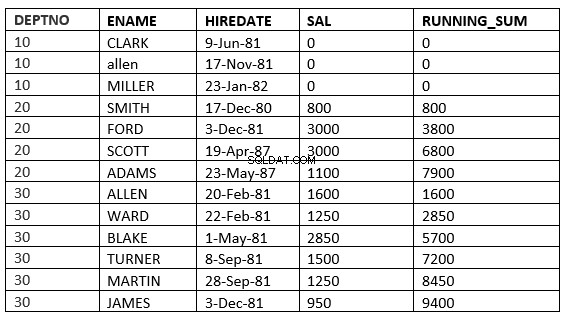
Você pode não ver a diferença entre o intervalo e as linhas, pois a data_contrato é diferente para todos. A diferença ficará mais clara se usarmos sal como ordem por cláusula
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by sal RANGE UNBOUNDED PRECEDING) running_sum from emp;
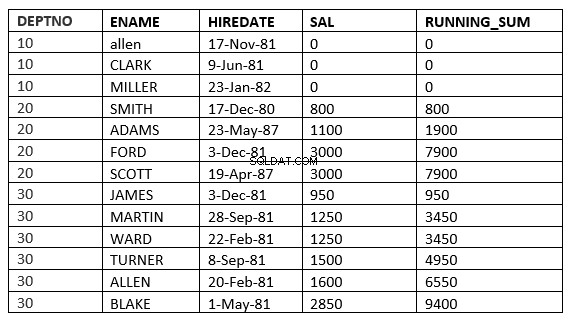
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by sal ROWS UNBOUNDED PRECEDING) running_sum from emp;
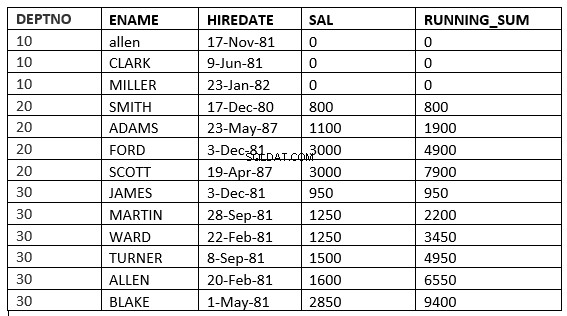
Você pode encontrar a diferença na linha 6
RANGE value_expr PRECEDING :A janela começa com a linha cujo valor ORDER BY é linhas de expressão numérica menores ou anteriores à linha atual e termina com a linha atual sendo processada.
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE RANGE 365 PRECEDING) running_sum from emp;
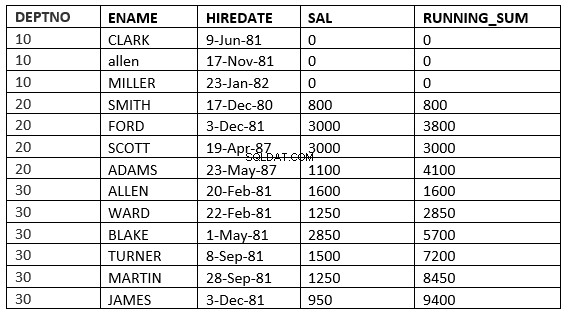
Aqui leva todas as linhas em que o valor contratado cai nos 365 dias anteriores ao valor contratado da linha atual
ROWS value_expr PRECEDENTE :A janela começa com a linha fornecida e termina com a linha atual sendo processada
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE ROWS 2 PRECEDING) running_sum from emp;
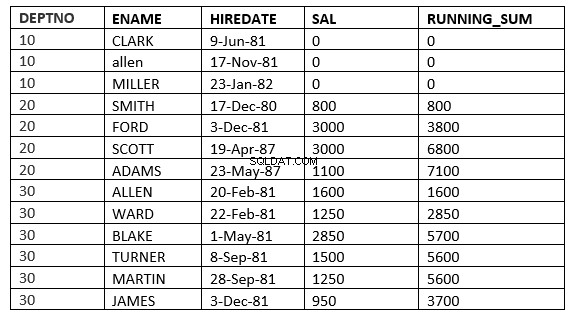
Aqui a janela começa a partir de 2 linhas que precedem a linha atual
RANGE ENTRE CURRENT ROW e value_expr SEGUINDO :A janela começa com a linha atual e termina com a linha cujo valor ORDER BY é linhas de expressão numérica menores que ou seguintes
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE ROWS between current row and 1 FOLLOWING) running_sum from emp;
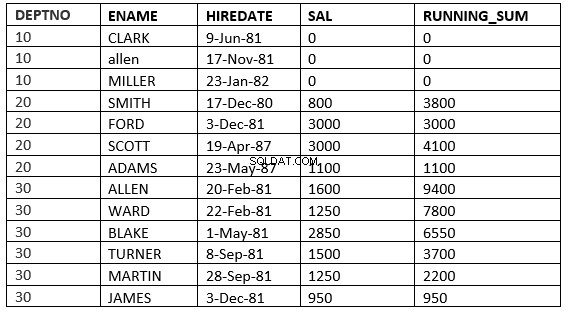
FILAS ENTRE CURRENT ROW e value_expr SEGUINDO :A janela começa com a linha atual e termina com as linhas após a atual
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE ROWS between current row and 1 FOLLOWING) running_sum from emp;
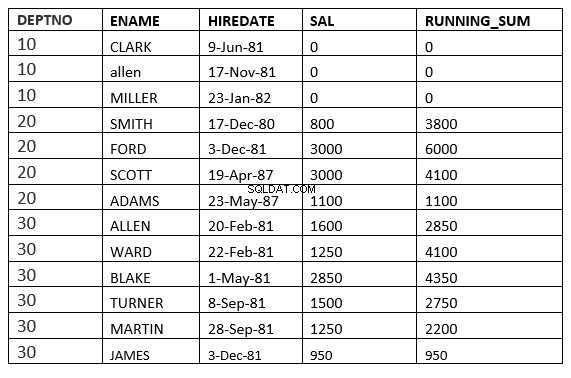
INTERVALO ENTRE O ANTECEDENTE ILIMITADO E O SEGUINTE ILIMITADO
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE RANGE BETWEEN UNBOUNDED PRECEDING and UNBOUNDED FOLLOWING ) running_sum from emp;
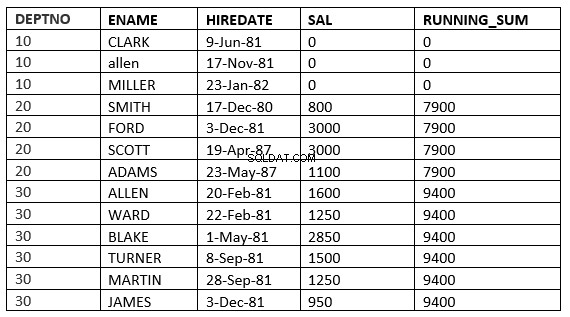
RANGE ENTRE value_expr PRECEDENTE e value_expr SEGUINDO
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE RANGE BETWEEN 365 PRECEDING and 365 FOLLOWING ) running_sum from emp; 2 DEPTNO ENAME HIREDATE SAL RUNNING_SUM ---------- ---------- --------------- ---------- ----------- 10 CLARK 09-JUN-81 0 0 10 ALLEN 17-NOV-81 0 0 10 MILLER 23-JAN-82 0 0 20 SMITH 17-DEC-80 800 3800 20 FORD 03-DEC-81 3000 3800 20 SCOTT 19-APR-87 3000 4100 20 ADAMS 23-MAY-87 1100 4100 30 ALLEN 20-FEB-81 1600 9400 30 WARD 22-FEB-81 1250 9400 30 BLAKE 01-MAY-81 2850 9400 30 TURNER 08-SEP-81 1500 9400 30 MARTIN 28-SEP-81 1250 9400 30 JAMES 03-DEC-81 950 9400 13 rows selected.
Algumas observações importantes
(1)As funções analíticas são o último conjunto de operações executadas em uma consulta, exceto a cláusula ORDER BY final. Todas as junções e todas as cláusulas WHERE, GROUP BY e HAVING são concluídas antes que as funções analíticas sejam processadas. Portanto, as funções analíticas podem aparecer apenas na lista de seleção ou na cláusula ORDER BY.
(2)As funções analíticas são comumente usadas para calcular agregados cumulativos, móveis, centralizados e de relatórios.
Espero que você goste desta explicação detalhada das funções analíticas no oracle (over by Partition Clause)
Artigos relacionados
Função LEAD no Oracle
Função DENSE no Oracle
Função LISTAGG do Oracle
Agregando dados usando funções de grupo
https://docs.oracle.com/cd/E11882_01/ server.112/e41084/functions004.htm



