Em geral todos os seus pontos estão corretos.
NLS_NCHAR_CHARACTERSET define o conjunto de caracteres para NVARCHAR2 , et. al. colunas enquanto NLS_CHARACTERSET é usado para VARCHAR2 .
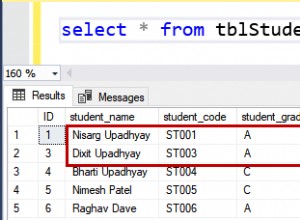
Por que é possível que você veja caracteres chineses comUS7ASCII?
A razão é que seu conjunto de caracteres do banco de dados e seu conjunto de caracteres do cliente (ou seja, consulte
NLS_LANG value) são ambos US7ASCII . Seu banco de dados usa US7ASCII e "pensa" também que o cliente envia dados usando US7ASCII . Assim não faz nenhuma conversão das strings, os dados são transferidos bit a bit do cliente para o servidor e vice-versa. Devido a esse fato, você pode usar caracteres que na verdade não são suportados pelo
US7ASCII . Esteja ciente, caso seu cliente use um conjunto de caracteres diferente (por exemplo, quando você usa o driver gerenciado ODP.NET em um aplicativo do Windows), os dados serão lixo! Além disso, se você considerar uma migração do conjunto de caracteres do banco de dados, terá o mesmo problema. Outra nota:eu não acho que você teria o mesmo comportamento com outros conjuntos de caracteres, por exemplo se seu banco de dados e seu cliente usarem
WE8ISO8859P1 por exemplo. Também esteja ciente de que você realmente tem uma configuração errada. Seu banco de dados usa o conjunto de caracteres US7ASCII , seu NLS_LANG valor também é US7ASCII (provavelmente não está definido e o Oracle o padroniza para US7ASCII ), mas o conjunto de caracteres real do SQL*Plus, resp. seu cmd.exe terminal é provavelmente CP950 ou CP936. Se você gosta de definir tudo corretamente, você pode definir sua variável de ambiente
NLS_LANG=.ZHT16MSWIN950 (CP936 parece não ser suportado pelo Oracle) ou altere sua página de código antes de executar sqlplus.exe com o comando chcp 437 . Com essas configurações adequadas, você não verá nenhum caractere chinês como provavelmente esperaria.