Esses testes (banco de dados AdventureWorks2008R2) mostram o que acontece:
SET NOCOUNT ON;
SET STATISTICS IO ON;
PRINT 'Test #1';
SELECT p.BusinessEntityID, p.LastName
FROM Person.Person p
WHERE p.LastName LIKE '%be%';
PRINT 'Test #2';
DECLARE @Pattern NVARCHAR(50);
SET @Pattern=N'%be%';
SELECT p.BusinessEntityID, p.LastName
FROM Person.Person p
WHERE p.LastName LIKE @Pattern;
SET STATISTICS IO OFF;
SET NOCOUNT OFF;
Resultados:
Test #1
Table 'Person'. Scan count 1, logical reads 106
Test #2
Table 'Person'. Scan count 1, logical reads 106
Os resultados de
SET STATISTICS IO mostra que LIO são as mesmas .Mas os planos de execução são bem diferentes: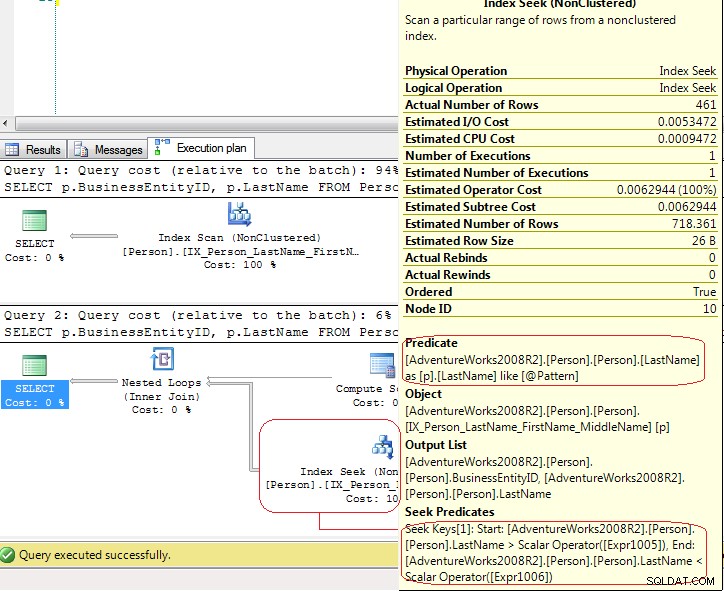
No primeiro teste, o SQL Server usa um
Index Scan explícito, mas no segundo teste o SQL Server usa um Index Seek que é uma Index Seek - range scan . No último caso, o SQL Server usa um Compute Scalar operador para gerar esses valores [Expr1005] = Scalar Operator(LikeRangeStart([@Pattern])),
[Expr1006] = Scalar Operator(LikeRangeEnd([@Pattern])),
[Expr1007] = Scalar Operator(LikeRangeInfo([@Pattern]))
e, a
Index Seek operador usa um Seek Predicate (otimizado) para uma range scan (LastName > LikeRangeStart AND LastName < LikeRangeEnd ) mais outro Predicate não otimizado (LastName LIKE @pattern ). Minha resposta:não é uma
Index Seek "real" . É uma Index Seek - range scan que, neste caso, tem o mesmo desempenho que Index Scan . Veja, também, a diferença entre
Index Seek e Index Scan (debate semelhante):Então… é uma Busca ou uma Varredura?
. Editar 1: O plano de execução para
OPTION(RECOMPILE) (veja a recomendação de Aaron, por favor) mostra, também, um Index Scan (em vez de Index Seek ):