Motivo do problema :
TOKEN método no SSIS usa a implementação de strtok função em C++ . Reuni essas informações ao ler o livro Microsoft® SQL Server® 2012 Integration Services forte>
. É mencionado como nota na página 113 (Gosto deste livro! Muitas informações interessantes. ). Procurei a implementação de
strtok função e encontrei os seguintes links. INFO:strtok():C Function -- Documentation Supplement - O exemplo de código neste link mostra que a função ignora caracteres delimitadores consecutivos.
As respostas para as seguintes perguntas SO indicam que
strtok função foi projetada para ignorar delimitadores consecutivos. Precisa saber quando nenhum dado aparece entre dois separadores de token usando strtok()
comportamento de strtok_s com delimitadores consecutivos
Acho que o
TOKEN e TOKENCOUNT as funções estão funcionando conforme o design, mas se é assim que o SSIS deve se comportar pode ser uma questão para a equipe do Microsoft SSIS. Post original - A seção acima é uma atualização:
Criei um pacote simples no SSIS 2012 com base em suas entradas de dados. Como você descreveu em sua pergunta, o
TOKEN função não se comporta como pretendido. Concordo com você que a função não parece funcionar. Esta postagem não uma resposta ao seu problema original. Aqui está uma maneira alternativa de escrever a expressão de uma maneira relativamente mais simples. Isso só funcionará se o último segmento em seu registro de entrada sempre tiver um valor (digamos A1 , B2 , C3 etc.).
A expressão pode ser reescrita como :
Essa instrução tomará o registro de entrada como parâmetro, o acento circunflexo delimitador (^) como segundo parâmetro. O terceiro parâmetro calcula o número total de segmentos nos registros quando dividido pelo delimitador. Se você tiver dados no último segmento, é garantido que você tenha dois segmentos. Você pode então subtrair 1 para buscar o penúltimo segmento.
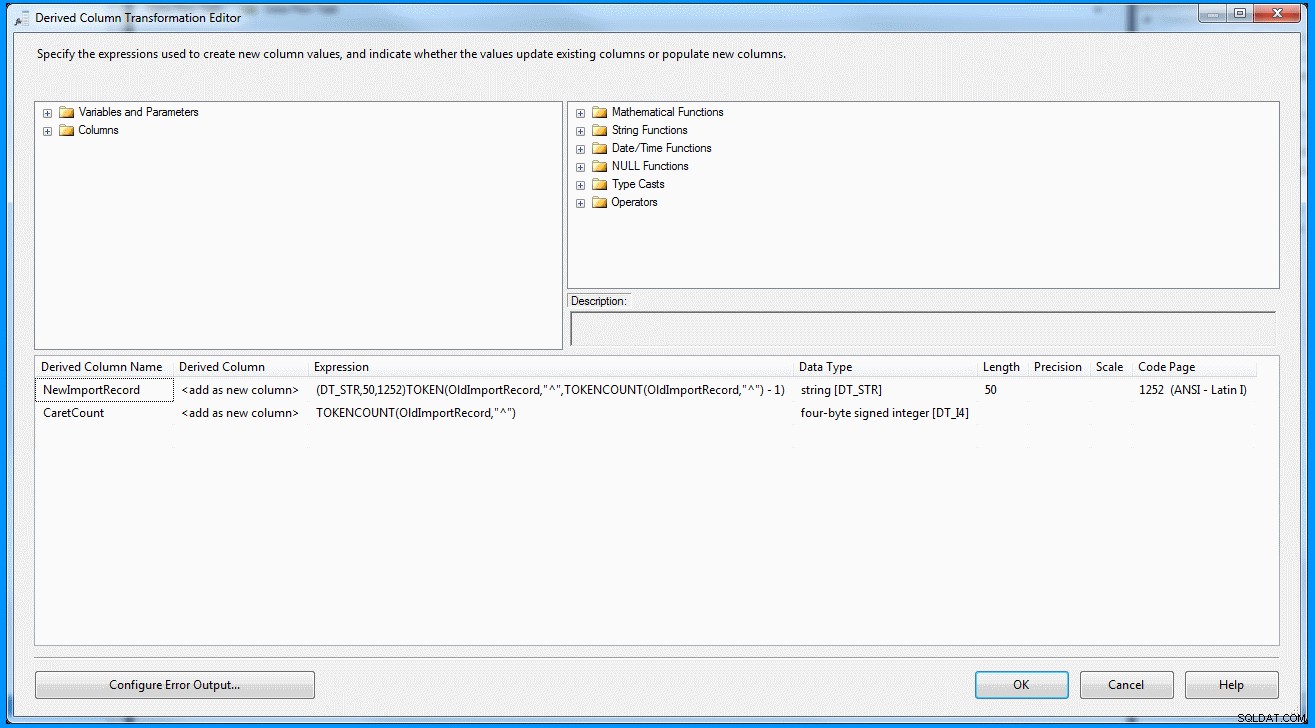
(DT_STR,50,1252)TOKEN(OldImportRecord,"^",TOKENCOUNT(OldImportRecord,"^") - 1)
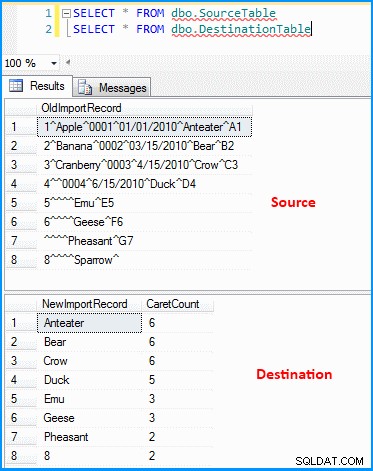
Eu criei um pacote simples com tarefa de fluxo de dados. A origem OLE DB recupera os dados e a transformação derivada analisa e divide os dados conforme a captura de tela abaixo. A saída é então inserida na tabela de destino. Você pode ver as tabelas de origem e destino na última captura de tela. A tabela de destino tem duas colunas. A primeira coluna armazena os dados do penúltimo segmento e a contagem de segmentos com base no delimitador (que novamente não está correto). Você pode notar que o último registro não buscou os resultados corretos. Se o último registro não tiver o valor
8 , a expressão acima falhará porque a expressão será avaliada como índice zero. Espero que ajude a simplificar sua expressão.
Se você não tiver notícias de mais ninguém, recomendo registrar esse problema no site do Microsoft Connect> .
Criar tabela e preencher scripts :
CREATE TABLE [dbo].[SourceTable](
[OldImportRecord] [varchar](50) NOT NULL
) ON [PRIMARY]
GO
CREATE TABLE [dbo].[DestinationTable](
[NewImportRecord] [varchar](50) NOT NULL,
[CaretCount] [int] NOT NULL
) ON [PRIMARY]
GO
INSERT INTO dbo.SourceTable (OldImportRecord) VALUES
('1^Apple^0001^01/01/2010^Anteater^A1'),
('2^Banana^0002^03/15/2010^Bear^B2'),
('3^Cranberry^0003^4/15/2010^Crow^C3'),
('4^^0004^6/15/2010^Duck^D4'),
('5^^^^Emu^E5'),
('6^^^^Geese^F6'),
('^^^^Pheasant^G7'),
('8^^^^Sparrow^');
GO
Transformação de coluna derivada dentro da tarefa de fluxo de dados :
Dados nas tabelas de origem e destino :