Quando você realiza sua consulta, os dados são lidos na memória em blocos. Esses blocos permanecem na memória, mas ficam "envelhecidos". Isso significa que os blocos são marcados com o último acesso e quando o Sql Server requer outro bloco para uma nova consulta e o cache de memória está cheio, o bloco menos usado recentemente (o mais antigo) é expulso da memória. (Na maioria dos casos - os blocos de varredura de tabelas completas são instantaneamente envelhecidos para evitar que varreduras de tabelas completas sobrecarreguem a memória e sufoquem o servidor).
O que está acontecendo aqui é que os blocos de dados na memória da primeira consulta ainda não foram expulsos da memória, então podem ser usados para sua segunda consulta, o que significa que o acesso ao disco é evitado e o desempenho é aprimorado.
Então, o que sua pergunta está realmente perguntando é "posso obter os blocos de dados de que preciso na memória sem lê-los na memória (realmente fazendo uma consulta)?". A resposta é não, a menos que você queira armazenar em cache as tabelas inteiras e mantê-las na memória permanentemente, o que, a partir do tempo de consulta (e, portanto, do tamanho dos dados) que você está descrevendo, provavelmente não é uma boa ideia.
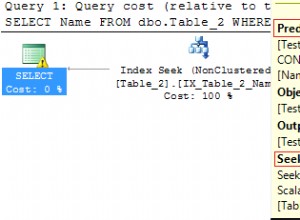
Sua melhor aposta para melhorar o desempenho é analisar seus planos de execução de consulta e verificar se a alteração de seus índices pode fornecer um resultado melhor. Existem duas áreas principais que podem melhorar o desempenho aqui:
- criar um índice em que a consulta possa usar um para evitar consultas ineficientes e verificações de tabela completas
- adicionar mais colunas a um índice para evitar uma segunda leitura de disco. Por exemplo, você tem uma consulta que retorna as colunas A e B com uma cláusula where em A e C e tem um índice na coluna A. Sua consulta usará o índice da coluna A exigindo uma leitura de disco, mas exigirá um segundo disco hit para obter as colunas B e C. Se o índice tiver todas as colunas A, B e C nele, o segundo hit de disco para obter os dados pode ser evitado.