Os custos de subárvore devem ser considerados com um grande grão de sal (e especialmente quando você tem grandes erros de cardinalidade).
SET STATISTICS IO ON; SET STATISTICS TIME ON; a saída é um melhor indicador do desempenho real. A classificação de linha zero não consome 87% dos recursos. Este problema em seu plano é de estimativa de estatísticas. Os custos apresentados no plano real ainda são custos estimados. Não os ajusta para levar em conta o que realmente aconteceu.
Há um ponto no plano em que um filtro reduz 1.911.721 linhas para 0, mas as linhas estimadas daqui para frente são 1.860.310. Depois disso, todos os custos são falsos, culminando no custo de 87% estimado em 3.348.560 linhas de classificação.
O erro de estimativa de cardinalidade pode ser reproduzido fora do
Merge declaração olhando para o plano estimado para o Full Outer Join com predicados equivalentes (fornece a mesma estimativa de 1.860.310 linhas). SELECT *
FROM TargetTable T
FULL OUTER JOIN @tSource S
ON S.Key1 = T.Key1 and S.Key2 = T.Key2
WHERE
CASE WHEN S.Key1 IS NOT NULL
/*Matched by Source*/
THEN CASE WHEN T.Key1 IS NOT NULL
/*Matched by Target*/
THEN CASE WHEN [T].[Data1]<>S.[Data1] OR
[T].[Data2]<>S.[Data2] OR
[T].[Data3]<>S.[Data3]
THEN (1)
END
/*Not Matched by Target*/
ELSE (4)
END
/*Not Matched by Source*/
ELSE CASE WHEN [T].[Key1]example@sqldat.com
THEN (3)
END
END IS NOT NULL
Dito isto, no entanto, o plano até o filtro em si parece bastante sub-ótimo. Ele está fazendo uma varredura completa de índice clusterizado quando talvez você queira um plano com 2 buscas de intervalo de índice clusterizado. Um para recuperar a única linha correspondente à chave primária da junção na origem e o outro para recuperar o
T.Key1 = @id range (embora talvez isso seja para evitar a necessidade de classificar em ordem de chave clusterizada posteriormente?) 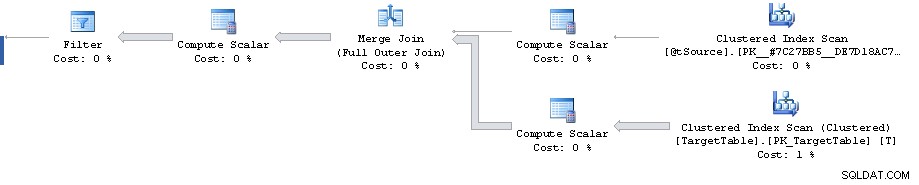
Talvez você possa tentar esta reescrita e ver se funciona melhor ou pior
;WITH FilteredTarget AS
(
SELECT T.*
FROM TargetTable AS T WITH (FORCESEEK)
JOIN @tSource S
ON (T.Key1 = S.Key1
AND S.Key2 = T.Key2)
OR T.Key1 = @id
)
MERGE FilteredTarget AS T
USING @tSource S
ON (T.Key1 = S.Key1
AND S.Key2 = T.Key2)
-- Only update if the Data columns do not match
WHEN MATCHED AND S.Key1 = T.Key1 AND S.Key2 = T.Key2 AND
(T.Data1 <> S.Data1 OR
T.Data2 <> S.Data2 OR
T.Data3 <> S.Data3) THEN
UPDATE SET T.Data1 = S.Data1,
T.Data2 = S.Data2,
T.Data3 = S.Data3
-- Note from original poster: This extra "safety clause" turned out not to
-- affect the behavior or the execution plan, so I removed it and it works
-- just as well without, but if you find yourself in a similar situation
-- you might want to give it a try.
-- WHEN MATCHED AND (S.Key1 <> T.Key1 OR S.Key2 <> T.Key2) AND T.Key1 = @id THEN
-- DELETE
-- Insert when missing in the target
WHEN NOT MATCHED BY TARGET THEN
INSERT (Key1, Key2, Data1, Data2, Data3)
VALUES (Key1, Key2, Data1, Data2, Data3)
WHEN NOT MATCHED BY SOURCE AND T.Key1 = @id THEN
DELETE;