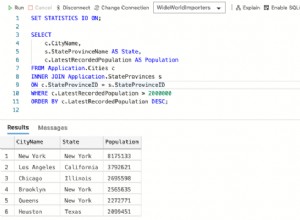
Demonstração de uma possível explicação.
Criar script de tabela
SELECT *
INTO #T
FROM master.dbo.spt_values
CREATE NONCLUSTERED INDEX [IX_T] ON #T ([name] DESC,[number] DESC);
Consulta um (retorna 35 resultados)
WITH cte AS
(
SELECT *, ROW_NUMBER() OVER (ORDER BY NAME) AS rn
FROM #T
)
SELECT c1.number,c1.[type]
FROM cte c1
JOIN cte c2 ON c1.rn=c2.rn AND c1.number <> c2.number
Consulta dois (igual a antes, mas adicionar c2.[type] à lista de seleção faz com que ela retorne 0 resultados);
WITH cte AS
(
SELECT *, ROW_NUMBER() OVER (ORDER BY NAME) AS rn
FROM #T
)
SELECT c1.number,c1.[type] ,c2.[type]
FROM cte c1
JOIN cte c2 ON c1.rn=c2.rn AND c1.number <> c2.number
Por quê?
row_number() para NAMEs duplicados não é especificado, portanto, apenas escolhe o que se encaixa no melhor plano de execução para as colunas de saída necessárias. Na segunda consulta, isso é o mesmo para ambas as invocações cte, na primeira ele escolhe um caminho de acesso diferente com uma numeração_de_linha diferente resultante.
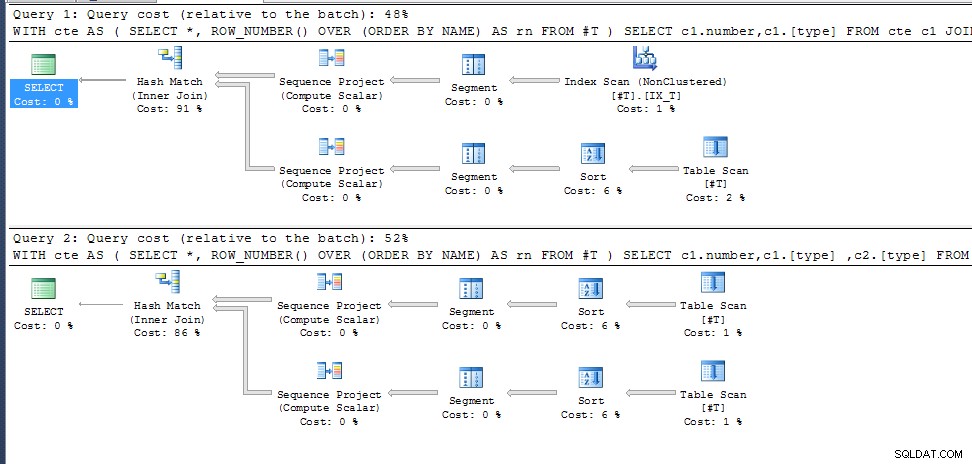
Solução sugerida
Você está se juntando ao CTE em
ROW_NUMBER() over (order by t.[Date]) Ao contrário do que se esperava, o CTE provavelmente não se materializar o que garantiria consistência para a autojunção e, portanto, você assume uma correlação entre
ROW_NUMBER() em ambos os lados que podem não existir para registros onde uma duplicata [Date] existe nos dados. E se você tentar
ROW_NUMBER() over (order by t.[Date], t.[id]) para garantir que, no caso de datas empatadas, a row_numbering esteja em uma ordem consistente garantida. (Ou alguma outra coluna/combinação de colunas que pode diferenciar registros se id não fizer isso)