Em alguma mesa de teste, meu plano original é o seguinte.
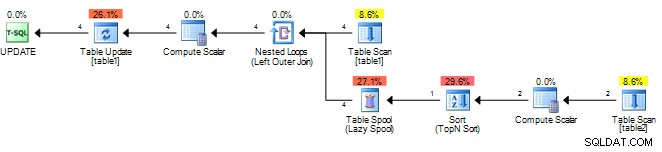
Ele apenas calcula o resultado uma vez e o armazena em um sppol e, em seguida, reproduz esse resultado. Você pode tentar o seguinte para que o SQL Server veja a subconsulta como correlacionada e precisando ser reavaliada para cada linha externa.
UPDATE table1
SET table2Id = (SELECT TOP 1 table2Id
FROM table2
ORDER BY Newid(),
table1.table1Id)
Para mim isso dá esse plano sem o carretel.
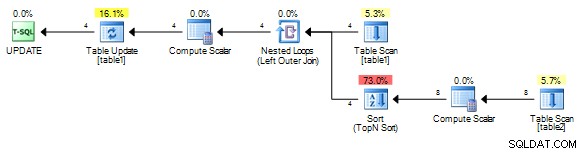
É importante correlacionar em um campo exclusivo de
table1 no entanto, mesmo que um carretel seja adicionado, ele sempre deve ser rebobinado em vez de rebobinado (reproduzindo o último resultado), pois o valor de correlação será diferente para cada linha. Se as tabelas forem grandes isto será lento pois o trabalho necessário é um produto das duas linhas da tabela (para cada linha em
table1 ele precisa fazer uma varredura completa de table2 )