Existem outras discussões de stackoverflow sobre este mesmo tópico (links na parte inferior). Conforme observado nos comentários acima, pode ter algo a ver com índices e o otimizador ficar confuso e usar o errado.
Meu primeiro pensamento é que você está fazendo um select top serviceid from (select *....) e o otimizador pode ter dificuldade em enviar a consulta para as consultas internas e usar o índice.
Considere reescrevê-lo como
select top 10 ServiceRequestID
from big_table_1
inner join big_table_2 cap2
on cap1.servicerequestid = cap2.customerreferencenumber
and big_table_1.statusid = 2
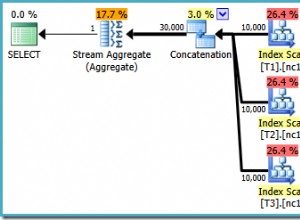
Em sua consulta, o banco de dados provavelmente está tentando mesclar os resultados e devolvê-los e, em seguida, limitá-lo aos 10 primeiros na consulta externa. Na consulta acima, o banco de dados terá apenas que reunir os 10 primeiros resultados, pois os resultados estão sendo mesclados, economizando muito tempo. E se servicerequestID estiver indexado, ele certamente o usará. Em seu exemplo, a consulta está procurando a coluna servicerequestid em um conjunto de resultados que já foi retornado em um formato virtual não indexado.
Espero que isso faça sentido. Embora hipoteticamente o otimizador deva pegar qualquer formato em que colocarmos o SQL e descobrir a melhor maneira de retornar valores todas as vezes, a verdade é que a maneira como montamos nosso SQL pode realmente afetar a ordem em que certas etapas são executadas no DB.
SELECT TOP é lento, independentemente de ORDER BY
Por que fazer um top(1) em uma coluna indexada no SQL Server é lento?