Em nossos blogs anteriores, justificamos por que você precisa de um failover de banco de dados e explicamos como funciona um mecanismo de failover. Estou compartilhando isso caso você tenha dúvidas sobre por que você deve configurar um mecanismo de failover para seu banco de dados MySQL. Se você fizer isso, por favor, leia nossos posts anteriores.
Como configurar o failover automático
A vantagem de usar MySQL ou MariaDB para gerenciar automaticamente seu failover é que existem ferramentas disponíveis que você pode usar e implementar em seu ambiente. Desde soluções de código aberto até soluções de nível empresarial. A maioria das ferramentas não é apenas capaz de failover, existem outros recursos, como alternância, monitoramento e recursos avançados que podem oferecer mais recursos de gerenciamento para seu cluster de banco de dados MySQL. Abaixo, veremos os mais comuns que você pode usar.
Usando MHA (Alta Disponibilidade Mestre)
Abordamos este tópico com MHA com seus problemas mais comuns e como corrigi-los. Também comparamos MHA com MRM ou com MaxScale.
Configurar com MHA para alta disponibilidade pode não ser fácil, mas é eficiente de usar e flexível, pois há parâmetros ajustáveis que você pode definir para personalizar seu failover. O MHA foi testado e usado. Mas à medida que a tecnologia avança, o MHA está ficando para trás, pois não suporta GTID para MariaDB e não tem feito nenhuma atualização nos últimos 2 ou 3 anos.
Ao executar o script masterha_manager,
masterha_manager --conf=/etc/app1.cnfOnde uma amostra /etc/app1.cnf deve ter a seguinte aparência,
[server default]
user=cmon
password=pass
ssh_user=root
# working directory on the manager
manager_workdir=/var/log/masterha/app1
# working directory on MySQL servers
remote_workdir=/var/log/masterha/app1
[server1]
hostname=node1
candidate_master=1
[server2]
hostname=node2
candidate_master=1
[server3]
hostname=node3
no_master=1Parâmetros como no_master e candidate_master devem ser cruciais ao definir a lista de permissões de nós desejados como seu mestre de destino e nós que você não deseja que sejam mestres.
Uma vez definido, você está pronto para ter failover para seu banco de dados MySQL caso ocorra uma falha no primário ou no mestre. O script masterha_manager gerencia o failover (automático ou manual), toma decisões sobre quando e onde fazer o failover e gerencia a recuperação do escravo durante a promoção do mestre candidato para aplicação de logs de retransmissão diferencial. Se o banco de dados mestre morrer, o MHA Manager irá coordenar com o agente MHA Node, pois aplica logs de retransmissão diferencial aos escravos que não têm os eventos binlog mais recentes do mestre.
Confira o que o agente MHA Node faz e seus scripts envolvidos. Basicamente, é o script que o MHA Manager invocará quando ocorrer o failover. Ele aguardará seu mandato do MHA Manager enquanto procura o escravo mais recente que contém os eventos de log binário e copia os eventos ausentes do escravo usando scp e os aplica a si mesmo. Conforme mencionado, ele aplica logs de retransmissão, limpa logs de retransmissão ou salva logs binários.
Se você quiser saber mais sobre parâmetros ajustáveis e como personalizar seu gerenciamento de failover, confira a página wiki de Parâmetros para MHA.
Usando o orquestrador
Orchestrator é uma ferramenta de gerenciamento de alta disponibilidade e replicação do MySQL e MariaDB. É lançado por Shlomi Noach sob os termos da Licença Apache, versão 2.0. Este é um software de código aberto e lida com failover automático, mas há muitas coisas que você pode personalizar ou fazer para gerenciar seu banco de dados MySQL/MariaDB além de recuperação ou failover automático.
A instalação do Orchestrator pode ser fácil ou direta. Depois de baixar os pacotes específicos necessários para seu ambiente de destino, você estará pronto para registrar seu cluster e nós a serem monitorados pelo Orchestrator. Ele fornece uma interface do usuário para a qual isso é muito fácil de gerenciar, mas possui muitos parâmetros ajustáveis ou um conjunto de comandos que você pode usar para obter seu gerenciamento de failover.
Vamos considerar que você finalmente configurou e O registro do cluster adicionando nosso nó primário ou mestre pode ser feito pelo comando abaixo,
$ orchestrator -c discover -i pupnode21:3306
2021-01-07 12:32:31 DEBUG Hostname unresolved yet: pupnode21
2021-01-07 12:32:31 DEBUG Cache hostname resolve pupnode21 as pupnode21
2021-01-07 12:32:31 DEBUG Connected to orchestrator backend: orchestrator:example@sqldat.com(127.0.0.1:3306)/orchestrator?timeout=1s
2021-01-07 12:32:31 DEBUG Orchestrator pool SetMaxOpenConns: 128
2021-01-07 12:32:31 DEBUG Initializing orchestrator
2021-01-07 12:32:31 INFO Connecting to backend 127.0.0.1:3306: maxConnections: 128, maxIdleConns: 32
2021-01-07 12:32:31 DEBUG Hostname unresolved yet: 192.168.40.222
2021-01-07 12:32:31 DEBUG Cache hostname resolve 192.168.40.222 as 192.168.40.222
2021-01-07 12:32:31 DEBUG Hostname unresolved yet: 192.168.40.223
2021-01-07 12:32:31 DEBUG Cache hostname resolve 192.168.40.223 as 192.168.40.223
pupnode21:3306Agora, adicionamos nosso cluster.
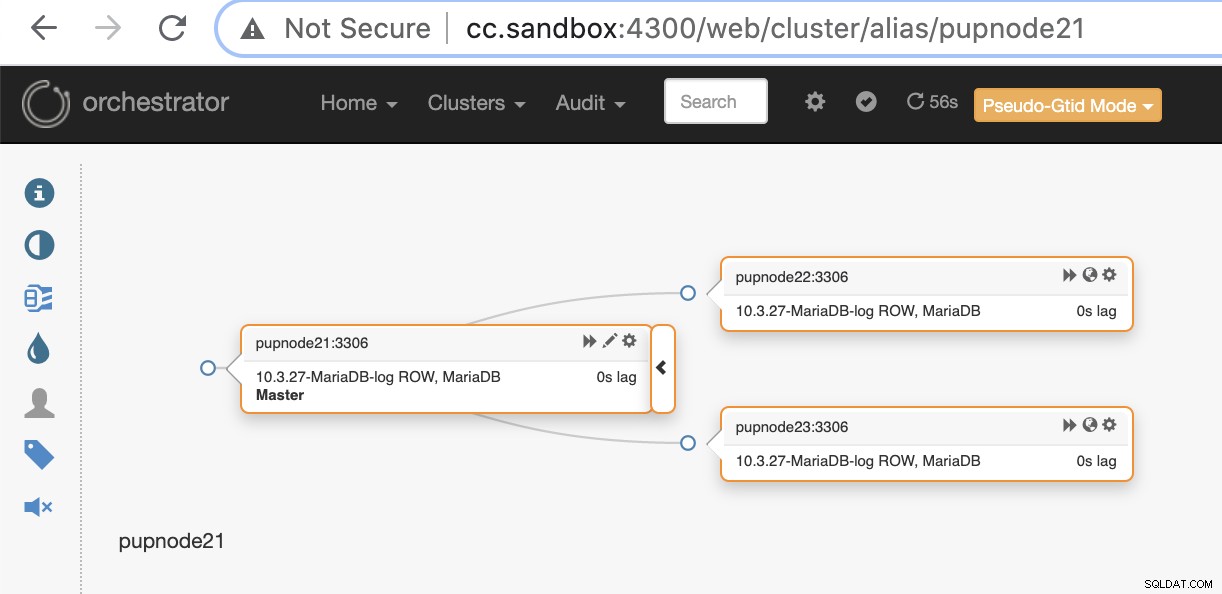
Se um nó primário falhar (falha de hardware ou travamento encontrado), o orquestrador irá detectar e localizar o nó mais avançado a ser promovido como nó principal ou mestre.
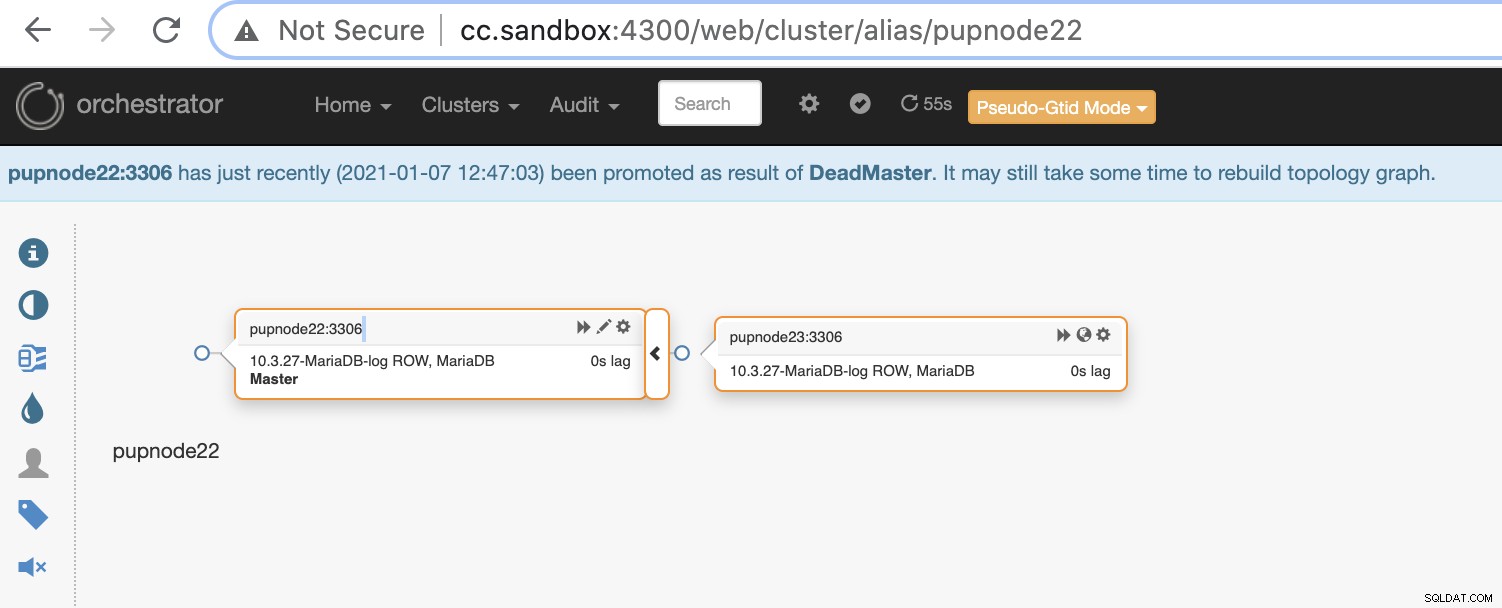
Agora, temos dois nós restantes no cluster enquanto o primário está inativo .
$ orchestrator-client -c topology -i pupnode21:3306
pupnode21:3306 [unknown,invalid,10.3.27-MariaDB-log,rw,ROW,>>,downtimed]
$ orchestrator-client -c topology -i pupnode22:3306
pupnode22:3306 [0s,ok,10.3.27-MariaDB-log,rw,ROW,>>]
+ pupnode23:3306 [0s,ok,10.3.27-MariaDB-log,ro,ROW,>>,GTID]Usando MaxScale
MariaDB MaxScale tem suporte como um balanceador de carga de banco de dados. Ao longo dos anos, o MaxScale cresceu e amadureceu, ampliado com vários recursos avançados e isso inclui failover automático. Desde que o MariaDB MaxScale 2.2 foi lançado, ele apresenta vários novos recursos, incluindo gerenciamento de failover de cluster de replicação. Você pode ler nosso blog anterior sobre o mecanismo de failover MaxScale.
O uso do MaxScale está sob BSL, embora o software esteja disponível gratuitamente, mas exige que você compre pelo menos o serviço com o MariaDB. Pode não ser adequado, mas caso você tenha adquirido os serviços corporativos MariaDB, isso pode ser uma grande vantagem se você precisar de gerenciamento de failover e seus outros recursos.
A instalação do MaxScale é fácil, mas definir a configuração necessária e definir seus parâmetros não é, e requer que você entenda o software. Você pode consultar o guia de configuração deles.
Para uma implantação rápida e rápida, você pode usar o ClusterControl para instalar o MaxScale para você em seu ambiente MySQL/MariaDB existente.
Uma vez instalado, a configuração do banco de dados Moodle pode ser feita apontando seu host para o IP ou nome do host MaxScale e a porta de leitura e gravação. Por exemplo,
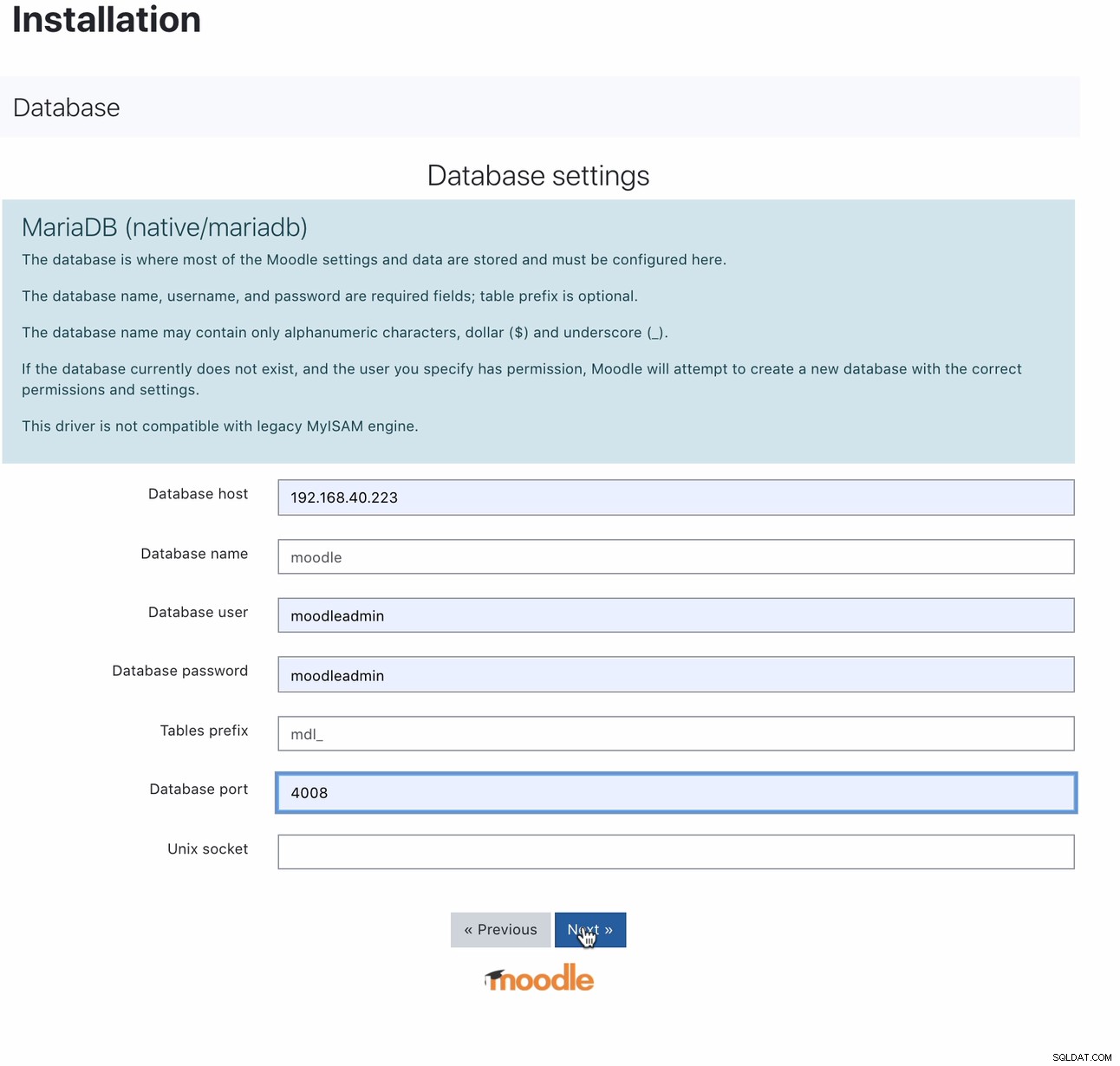
Para qual porta 4008 é sua leitura/gravação para seu ouvinte de serviço. Por exemplo, aqui está a configuração de serviço e ouvinte a seguir para meu MaxScale.
$ cat maxscale.cnf.d/rw-listener.cnf
[rw-listener]
type=listener
protocol=mariadbclient
service=rw-service
address=0.0.0.0
port=4008
authenticator=MySQLAuth
$ cat maxscale.cnf.d/rw-service.cnf
[rw-service]
type=service
servers=DB_123,DB_122,DB_124
router=readwritesplit
user=maxscale_adm
password=42BBD2A4DC1BF9BE05C41A71DEEBDB70
max_slave_connections=100%
max_sescmd_history=15000000
causal_reads=true
causal_reads_timeout=10
transaction_replay=true
transaction_replay_max_size=32Mi
delayed_retry=true
master_reconnection=true
max_connections=0
connection_timeout=0
use_sql_variables_in=master
master_accept_reads=true
disable_sescmd_history=falseDurante a configuração do seu monitor, você não deve esquecer de habilitar o failover automático ou também habilitar o reingresso automático se desejar que o mestre anterior falhe ao reingressar automaticamente ao voltar a ficar online. Fica assim,
$ egrep -r 'auto|^\[' maxscale.cnf.d/replication_monitor.cnf
[replication_monitor]
auto_failover=true
auto_rejoin=1Observe que as variáveis que declarei não são destinadas ao uso em produção, mas apenas para esta postagem do blog e para fins de teste. A coisa boa com MaxScale, uma vez que o primário ou mestre cai, MaxScale é inteligente o suficiente para promover o candidato ideal ou melhor para assumir o papel de mestre. Portanto, não há necessidade de alterar seu IP e porta, pois usamos o host/IP de nosso nó MaxScale e sua porta como nosso endpoint quando o mestre fica inativo. Por exemplo,
[192.168.40.223:6603] MaxScale> list servers
┌────────┬────────────────┬──────┬─────────────┬─────────────────┬──────────────────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼────────────────┼──────┼─────────────┼─────────────────┼──────────────────────────┤
│ DB_124 │ 192.168.40.223 │ 3306 │ 0 │ Slave, Running │ 3-2003-876,5-2001-219541 │
├────────┼────────────────┼──────┼─────────────┼─────────────────┼──────────────────────────┤
│ DB_123 │ 192.168.40.221 │ 3306 │ 0 │ Master, Running │ 3-2003-876,5-2001-219541 │
├────────┼────────────────┼──────┼─────────────┼─────────────────┼──────────────────────────┤
│ DB_122 │ 192.168.40.222 │ 3306 │ 0 │ Slave, Running │ 3-2003-876,5-2001-219541 │
└────────┴────────────────┴──────┴─────────────┴─────────────────┴──────────────────────────┘O nó DB_123 que aponta para 192.168.40.221 é o mestre atual. Terminar o nó DB_123 acionará o MaxScale para realizar um failover e ficará assim,
[192.168.40.223:6603] MaxScale> list servers
┌────────┬────────────────┬──────┬─────────────┬─────────────────┬──────────────────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼────────────────┼──────┼─────────────┼─────────────────┼──────────────────────────┤
│ DB_124 │ 192.168.40.223 │ 3306 │ 0 │ Slave, Running │ 3-2003-876,5-2001-219541 │
├────────┼────────────────┼──────┼─────────────┼─────────────────┼──────────────────────────┤
│ DB_123 │ 192.168.40.221 │ 3306 │ 0 │ Down │ 3-2003-876,5-2001-219541 │
├────────┼────────────────┼──────┼─────────────┼─────────────────┼──────────────────────────┤
│ DB_122 │ 192.168.40.222 │ 3306 │ 0 │ Master, Running │ 3-2003-876,5-2001-219541 │
└────────┴────────────────┴──────┴─────────────┴─────────────────┴──────────────────────────┘Enquanto, nosso banco de dados Moodle ainda está funcionando, pois nosso MaxScale aponta para o último mestre que foi promovido.
$ mysql -hmaxscale.local.domain -umoodleuser -pmoodlepassword -P4008
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MariaDB connection id is 9
Server version: 10.3.27-MariaDB-log MariaDB Server
Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
MariaDB [(none)]> select @@hostname;
+------------+
| @@hostname |
+------------+
| 192.168.40.222 |
+------------+
1 row in set (0.001 sec)Usando ClusterControl
O ClusterControl pode ser baixado gratuitamente e oferece licenças para Community, Advance e Enterprise. O failover automático está disponível apenas no Advance e Enterprise. O failover automático é coberto pelo nosso recurso Auto-Recovery, que tenta recuperar um cluster com falha ou um nó com falha. Se você quiser mais detalhes sobre como fazer isso, confira nosso post anterior Como o ClusterControl executa recuperação automática de banco de dados e failover. Oferece parâmetros ajustáveis que são muito convenientes e fáceis de usar. Leia nosso post anterior também sobre Como automatizar o failover de banco de dados com o ClusterControl.
Gerenciar seu failover automático para seu banco de dados Moodle deve exigir pelo menos um IP virtual (VIP) como seu ponto de extremidade para seu cliente de aplicativo Moodle que faz interface com seu back-end de banco de dados. Para fazer isso, você pode implantar Keepalived com HAProxy (ou ProxySQL -- depende da sua escolha de balanceador de carga) sobre ele. Nesse caso, o endpoint do banco de dados Moodle deve apontar para o IP virtual, que é basicamente atribuído pelo Keepalived depois de implantado, da mesma forma que mostramos anteriormente ao configurar o MaxScale. Você também pode verificar este blog sobre como fazê-lo.
Como mencionado acima, os parâmetros ajustáveis estão disponíveis e você pode simplesmente definir através do seu /etc/cmon.d/cmon_ O ClusterControl é muito flexível ao gerenciar o failover para que você possa executar algumas tarefas de pré-failover ou pós-failover.
Conclusão
Existem outras ótimas opções ao configurar e gerenciar automaticamente seu failover para seu banco de dados MySQL para Moodle. Depende do seu orçamento e com o que você provavelmente terá que gastar dinheiro. Usar os de código aberto requer experiência e vários testes para se familiarizar, pois não há suporte que você possa executar quando precisar de ajuda além da comunidade. Com as soluções corporativas, ele tem um preço, mas oferece suporte e facilidade, pois o trabalho demorado pode ser reduzido. Observe que, se o failover for usado incorretamente, poderá causar danos ao banco de dados se não for tratado e gerenciado adequadamente. Concentre-se no que é mais importante e como você é capaz das soluções que está utilizando para gerenciar o failover do banco de dados Moodle.