A Durabilidade Atrasada é um recurso recente, mas interessante, do SQL Server 2014; o pitch de elevador de alto nível do recurso é, simplesmente:
- "Troque a durabilidade pelo desempenho."
Alguns antecedentes primeiro. Por padrão, o SQL Server usa um log de gravação antecipada (WAL), o que significa que as alterações são gravadas no log antes de serem autorizadas a serem confirmadas. Em sistemas em que as gravações de log de transações se tornam o gargalo e onde há uma tolerância moderada para perda de dados , agora você tem a opção de suspender temporariamente o requisito de aguardar a liberação e a confirmação do log. Isso acontece para tirar literalmente o D do ACID, pelo menos para uma pequena parte dos dados (mais sobre isso mais tarde).
Você meio que já faz esse sacrifício agora. No modo de recuperação total, há sempre algum risco de perda de dados, é medido apenas em termos de tempo e não de tamanho. Por exemplo, se você fizer backup do log de transações a cada cinco minutos, poderá perder até menos de 5 minutos de dados se algo catastrófico acontecer. Não estou falando de failover simples aqui, mas digamos que o servidor literalmente pega fogo ou alguém tropeça no cabo de alimentação - o banco de dados pode muito bem ser irrecuperável e você pode ter que voltar ao ponto no tempo do último backup de log . E isso supondo que você esteja testando seus backups restaurando-os em algum lugar – no caso de uma falha crítica, você pode não ter o ponto de recuperação que pensa ter. É claro que tendemos a não pensar nesse cenário, porque nunca esperamos coisas ruins™ acontecer.
Como funciona
A durabilidade atrasada permite que as transações de gravação continuem sendo executadas como se o log tivesse sido liberado para o disco; na realidade, as gravações em disco foram agrupadas e adiadas, para serem tratadas em segundo plano. A transação é otimista; ele assume que a liberação do log irá acontecer. O sistema usa um bloco de 60 KB de buffer de log e tenta liberar o log para o disco quando esse bloco de 60 KB estiver cheio (no máximo - isso pode acontecer e geralmente acontecerá antes disso). Você pode definir essa opção no nível do banco de dados, no nível da transação individual ou – no caso de procedimentos compilados nativamente no OLTP na memória – no nível do procedimento. A configuração do banco de dados vence em caso de conflito; por exemplo, se o banco de dados estiver definido como desabilitado, tentar confirmar uma transação usando a opção atrasada será simplesmente ignorado, sem nenhuma mensagem de erro. Além disso, algumas transações são sempre totalmente duráveis, independentemente das configurações do banco de dados ou das configurações de confirmação; por exemplo, transações do sistema, transações entre bancos de dados e operações envolvendo FileTable, Change Tracking, Change Data Capture e Replication.
No nível do banco de dados, você pode usar:
ALTER DATABASE dbname SET DELAYED_DURABILITY = DISABLED | ALLOWED | FORCED;
Se você definir como
ALLOWED , isso significa que qualquer transação individual pode usar a Durabilidade Atrasada; FORCED significa que todas as transações que podem usar a Durabilidade Atrasada (as exceções acima ainda são relevantes neste caso). Você provavelmente desejará usar ALLOWED em vez de FORCED – mas o último pode ser útil no caso de um aplicativo existente em que você deseja usar essa opção e também minimizar a quantidade de código que precisa ser tocada. Uma observação importante sobre ALLOWED é que transações totalmente duráveis podem ter que esperar mais tempo, pois forçarão primeiro a liberação de quaisquer transações duráveis atrasadas. No nível da transação, você pode dizer:
COMMIT TRANSACTION WITH (DELAYED_DURABILITY = ON);
E em um procedimento compilado nativamente OLTP na memória, você pode adicionar a seguinte opção ao
BEGIN ATOMIC quadra:BEGIN ATOMIC WITH (DELAYED_DURABILITY = ON, ...)
Uma pergunta comum é sobre o que acontece com a semântica de bloqueio e isolamento. Nada muda, realmente. Bloqueio e bloqueio ainda acontecem, e as transações são confirmadas da mesma maneira e com as mesmas regras. A única diferença é que, ao permitir que a confirmação ocorra sem esperar que o log seja liberado no disco, quaisquer bloqueios relacionados são liberados muito mais cedo.
Quando você deve usá-lo
Além do benefício obtido ao permitir que as transações prossigam sem esperar que a gravação de log aconteça, você também obtém menos gravações de log de tamanhos maiores. Isso pode funcionar muito bem se o seu sistema tiver uma alta proporção de transações que sejam realmente menores que 60 KB e, principalmente, quando o disco de log estiver lento (embora eu tenha encontrado benefícios semelhantes no SSD e no HDD tradicional). Não funciona tão bem se suas transações forem, na maioria das vezes, maiores que 60 KB, se normalmente forem de longa duração ou se você tiver alta taxa de transferência e alta simultaneidade. O que pode acontecer aqui é que você pode preencher todo o buffer de log antes que a liberação termine, o que significa apenas transferir suas esperas para um recurso diferente e, em última análise, não melhorar o desempenho percebido pelos usuários do aplicativo.
Em outras palavras, se seu log de transações não for atualmente um gargalo, não ative esse recurso. Como você pode saber se seu log de transações é atualmente um gargalo? O primeiro indicador seria alto
WRITELOG espera, principalmente quando combinado com PAGEIOLATCH_** . Paul Randal (@PaulRandal) tem uma ótima série de quatro partes sobre identificação de problemas de log de transações, bem como configuração para desempenho ideal:- Cortando a gordura do log de transações
- Cortando mais gordura do log de transações
- Problemas de configuração do registro de transações
- Monitoramento do registro de transações
Consulte também esta postagem no blog de Kimberly Tripp (@KimberlyLTripp), 8 etapas para melhorar a taxa de transferência do log de transações e a postagem no blog da equipe SQL CAT, Diagnosticando problemas de desempenho do log de transações e limites do Log Manager.
Esta investigação pode levar você à conclusão de que vale a pena investigar a Durabilidade Atrasada; pode não. Testar sua carga de trabalho será a maneira mais confiável de ter certeza. Como muitas outras adições em versões recentes do SQL Server (*tosse* Hekaton ), esse recurso NÃO foi projetado para melhorar todas as cargas de trabalho e, conforme observado acima, pode realmente piorar algumas cargas de trabalho. Veja esta postagem no blog de Simon Harvey para outras perguntas que você deve fazer sobre sua carga de trabalho para determinar se é viável sacrificar alguma durabilidade para obter um melhor desempenho.
Potencial de perda de dados
Vou mencionar isso várias vezes e enfatizar sempre que o fizer:Você precisa ser tolerante à perda de dados . Em um disco com bom desempenho, o máximo que você deve esperar perder em uma catástrofe – ou mesmo em um desligamento planejado e normal – é de até um bloco completo (60 KB). No entanto, no caso de seu subsistema de E/S não conseguir acompanhar, é possível que você perca até o buffer de log inteiro (~7 MB).
Para esclarecer, a partir da documentação (grifo meu):
Para durabilidade atrasada, não há diferença entre um desligamento inesperado e um desligamento/reinicialização esperado do SQL Server . Assim como eventos catastróficos, você deve planejar a perda de dados . Em um desligamento/reinicialização planejado, algumas transações que não foram gravadas no disco podem primeiro ser salvas no disco, mas você não deve planejar isso. Planeje como se um desligamento/reinicialização, planejado ou não, perdesse os dados da mesma forma que um evento catastrófico.
Portanto, é muito importante que você avalie o risco de perda de dados com a necessidade de aliviar os problemas de desempenho do log de transações. Se você administra um banco ou qualquer coisa que lide com dinheiro, pode ser muito mais seguro e apropriado mover seu log para um disco mais rápido do que jogar os dados usando esse recurso. Se você está tentando melhorar o tempo de resposta em seu aplicativo Web Gamerz Chat Room, talvez o risco seja menos grave.
Você pode controlar esse comportamento até certo ponto para minimizar o risco de perda de dados. Você pode forçar todas as transações duráveis atrasadas a serem liberadas para o disco de duas maneiras:
- Confirme qualquer transação totalmente durável.
- Ligue para
sys.sp_flush_logmanualmente.
Isso permite que você volte a controlar a perda de dados em termos de tempo, em vez de tamanho; você pode agendar a descarga a cada 5 segundos, por exemplo. Mas você vai querer encontrar o seu ponto ideal aqui; lavar com muita frequência pode compensar o benefício de Durabilidade Atrasada em primeiro lugar. De qualquer forma, você ainda precisará ser tolerante à perda de dados , mesmo que valha apenas
Você pensaria que
CHECKPOINT pode ajudar aqui, mas esta operação na verdade não garante tecnicamente que o log será liberado para o disco. Interação com HA/DR
Você pode se perguntar como a Durabilidade Atrasada funciona com recursos de HA/DR, como envio de logs, replicação e Grupos de Disponibilidade. Com a maioria deles funciona inalterado. O envio e a replicação de logs reproduzirão os registros de log que foram protegidos, portanto, existe o mesmo potencial de perda de dados. Com AGs no modo assíncrono, não estamos esperando o reconhecimento secundário de qualquer maneira, então ele se comportará da mesma forma que hoje. Com o síncrono, no entanto, não podemos confirmar no primário até que a transação seja confirmada e protegida no log remoto. Mesmo nesse cenário, podemos ter algum benefício localmente por não ter que esperar a gravação do log local, ainda temos que esperar pela atividade remota. Portanto, nesse cenário há menos benefícios e potencialmente nenhum; exceto talvez no raro cenário em que o disco de log do primário é muito lento e o disco de log do secundário é muito rápido. Suspeito que as mesmas condições sejam verdadeiras para espelhamento sincronizado/assíncrono, mas você não receberá nenhum compromisso oficial meu sobre como um novo recurso brilhante funciona com um obsoleto. :-)
Observações de desempenho
Este não seria um grande post aqui se eu não mostrasse algumas observações reais de desempenho. Configurei 8 bancos de dados para testar os efeitos de dois padrões de carga de trabalho diferentes com os seguintes atributos:
- Modelo de recuperação:simples x completo
- Local do registro:SSD x HDD
- Durabilidade:atrasada x totalmente durável
Eu sou muito, muito, muito
model :USE model; GO CREATE TABLE dbo.TheTable ( TheID INT IDENTITY(1,1) PRIMARY KEY, TheDate DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP, RowGuid UNIQUEIDENTIFIER NOT NULL DEFAULT NEWID() );
Então eu construí um conjunto de comandos SQL dinâmicos para construir esses 8 bancos de dados, em vez de criar os bancos de dados individualmente e depois mexer nas configurações:
-- C and D are SSD, G is HDD
DECLARE @sql NVARCHAR(MAX) = N'';
;WITH l AS (SELECT l FROM (VALUES('D'),('G')) AS l(l)),
r AS (SELECT r FROM (VALUES('FULL'),('SIMPLE')) AS r(r)),
d AS (SELECT d FROM (VALUES('FORCED'),('DISABLED')) AS d(d)),
x AS (SELECT l.l, r.r, d.d, n = CONVERT(CHAR(1),ROW_NUMBER() OVER
(ORDER BY d.d DESC, l.l)) FROM l CROSS JOIN r CROSS JOIN d)
SELECT @sql += N'
CREATE DATABASE dd' + n + ' ON '
+ '(name = ''dd' + n + '_data'','
+ ' filename = ''C:\SQLData\dd' + n + '.mdf'', size = 1024MB)
LOG ON (name = ''dd' + n + '_log'','
+ ' filename = ''' + l + ':\SQLLog\dd' + n + '.ldf'', size = 1024MB);
ALTER DATABASE dd' + n + ' SET RECOVERY ' + r + ';
ALTER DATABASE dd' + n + ' SET DELAYED_DURABILITY = ' + d + ';'
FROM x ORDER BY d, l;
PRINT @sql;
-- EXEC sp_executesql @sql; Sinta-se à vontade para executar este código você mesmo (com o
EXEC ainda comentado) para ver que isso criaria 4 bancos de dados com Delayed Durability OFF (dois em recuperação COMPLETA, dois em SIMPLE, um de cada com log em disco lento e um de cada com log em SSD). Repita esse padrão para 4 bancos de dados com Durabilidade Atrasada FORCED – fiz isso para simplificar o código no teste, em vez de refletir o que eu faria na vida real (onde provavelmente gostaria de tratar algumas transações como críticas e outras como, bem, menos do que crítico). Para verificação de sanidade, executei a seguinte consulta para garantir que os bancos de dados tivessem a matriz de atributos correta:
SELECT d.name, d.recovery_model_desc, d.delayed_durability_desc, log_disk = CASE WHEN mf.physical_name LIKE N'D%' THEN 'SSD' else 'HDD' END FROM sys.databases AS d INNER JOIN sys.master_files AS mf ON d.database_id = mf.database_id WHERE d.name LIKE N'dd[1-8]' AND mf.[type] = 1; -- log
Resultados:
| nome | recovery_model | delayed_durability | log_disk |
|---|---|---|---|
| dd1 | COMPLETO | FORÇADO | SSD |
| dd2 | Simples | FORÇADO | SSD |
| dd3 | COMPLETO | FORÇADO | HDD |
| dd4 | Simples | FORÇADO | HDD |
| dd5 | COMPLETO | DESATIVADO | SSD |
| dd6 | Simples | DESATIVADO | SSD |
| dd7 | COMPLETO | DESATIVADO | HDD |
| dd8 | Simples | DESATIVADO | HDD |
Configuração relevante dos 8 bancos de dados de teste
Também executei o teste de forma limpa várias vezes para garantir que um arquivo de dados de 1 GB e um arquivo de log de 1 GB seriam suficientes para executar todo o conjunto de cargas de trabalho sem introduzir nenhum evento de crescimento automático na equação. Como prática recomendada, sempre me esforço para garantir que os sistemas dos clientes tenham espaço alocado suficiente (e alertas adequados integrados) para que nenhum evento de crescimento ocorra em um momento inesperado. No mundo real eu sei que isso nem sempre acontece, mas é o ideal.
Configurei o sistema para ser monitorado com o SQL Sentry – isso me permitiria mostrar facilmente a maioria das métricas de desempenho que eu queria destacar. Mas também criei uma tabela temporária para armazenar métricas de lote, incluindo duração e saída muito específica de sys.dm_io_virtual_file_stats:
SELECT test = 1, cycle = 1, start_time = GETDATE(), *
INTO #Metrics
FROM sys.dm_io_virtual_file_stats(DB_ID('dd1'), 2) WHERE 1 = 0; Isso me permitiria registrar o horário de início e término de cada lote individual e medir deltas no DMV entre o horário de início e o horário de término (confiável apenas neste caso porque sei que sou o único usuário no sistema).
Muitas pequenas transações
O primeiro teste que eu queria fazer era um monte de pequenas transações. Para cada banco de dados, eu queria terminar com 500.000 lotes separados de uma única inserção cada:
INSERT #Metrics SELECT 1, 1, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID('dd1'), 2);
GO
INSERT dbo.TheTable DEFAULT VALUES;
GO 500000
INSERT #Metrics SELECT 1, 2, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID('dd1'), 2); Lembre-se, eu tento ser
;WITH x AS
(
SELECT TOP (8) number FROM master..spt_values
WHERE type = N'P' ORDER BY number
)
SELECT CONVERT(NVARCHAR(MAX), N'') + N'
INSERT #Metrics SELECT 1, 1, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID(''dd' + RTRIM(number+1) + '''), 2);
GO
INSERT dbo.TheTable DEFAULT VALUES;
GO 500000
INSERT #Metrics SELECT 1, 2, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID(''dd' + RTRIM(number+1) + '''), 2);'
FROM x; Executei este teste e, em seguida, examinei o
#Metrics tabela com a seguinte consulta:SELECT
[database] = db_name(m1.database_id),
num_writes = m2.num_of_writes - m1.num_of_writes,
write_bytes = m2.num_of_bytes_written - m1.num_of_bytes_written,
bytes_per_write = (m2.num_of_bytes_written - m1.num_of_bytes_written)*1.0
/(m2.num_of_writes - m1.num_of_writes),
io_stall_ms = m2.io_stall_write_ms - m1.io_stall_write_ms,
m1.start_time,
end_time = m2.start_time,
duration = DATEDIFF(SECOND, m1.start_time, m2.start_time)
FROM #Metrics AS m1
INNER JOIN #Metrics AS m2
ON m1.database_id = m2.database_id
WHERE m1.cycle = 1 AND m2.cycle = 2
AND m1.test = 1 AND m2.test = 1; Isso gerou os seguintes resultados (e confirmei através de vários testes que os resultados eram consistentes):
| banco de dados | escreve | bytes | bytes/gravação | io_stall_ms | start_time | end_time | duração (segundos) |
|---|---|---|---|---|---|---|---|
| dd1 | 8.068 | 261.894.656 | 32.460,91 | 6.232 | 2014-04-26 17:20:00 | 2014-04-26 17:21:08 | 68 |
| dd2 | 8.072 | 261.682.688 | 32.418,56 | 2.740 | 2014-04-26 17:21:08 | 2014-04-26 17:22:16 | 68 |
| dd3 | 8.246 | 262.254.592 | 31.803,85 | 3.996 | 2014-04-26 17:22:16 | 2014-04-26 17:23:24 | 68 |
| dd4 | 8.055 | 261.688.320 | 32.487,68 | 4.231 | 2014-04-26 17:23:24 | 2014-04-26 17:24:32 | 68 |
| dd5 | 500.012 | 526.448.640 | 1.052,87 | 35.593 | 2014-04-26 17:24:32 | 2014-04-26 17:26:32 | 120 |
| dd6 | 500.014 | 525.870.080 | 1.051,71 | 35.435 | 2014-04-26 17:26:32 | 2014-04-26 17:28:31 | 119 |
| dd7 | 500.015 | 526.120.448 | 1.052,20 | 50.857 | 2014-04-26 17:28:31 | 2014-04-26 17:30:45 | 134 |
| dd8 | 500.017 | 525.886.976 | 1.051,73 | 49.680 | 133 |
Transações pequenas:duração e resultados de sys.dm_io_virtual_file_stats
Definitivamente algumas observações interessantes aqui:
- O número de operações de gravação individuais era muito pequeno para os bancos de dados de durabilidade atrasada (~60 vezes para os tradicionais).
- O número total de bytes gravados foi reduzido pela metade usando a durabilidade atrasada (presumo que todas as gravações no caso tradicional continham muito espaço desperdiçado).
- O número de bytes por gravação foi muito maior para Durabilidade Atrasada. Isso não foi muito surpreendente, pois todo o objetivo do recurso é agrupar gravações em lotes maiores.
- A duração total dos travamentos de E/S foi volátil, mas aproximadamente uma ordem de magnitude menor para Durabilidade Atrasada. As paralisações em transações totalmente duráveis eram muito mais sensíveis ao tipo de disco.
- Se nada o convenceu até agora, a coluna de duração é muito reveladora. Lotes totalmente duráveis que levam dois minutos ou mais são cortados quase pela metade.
As colunas de horário de início/término me permitiram focar no painel do Performance Advisor para o período preciso em que essas transações estavam acontecendo, onde podemos desenhar muitos indicadores visuais adicionais:
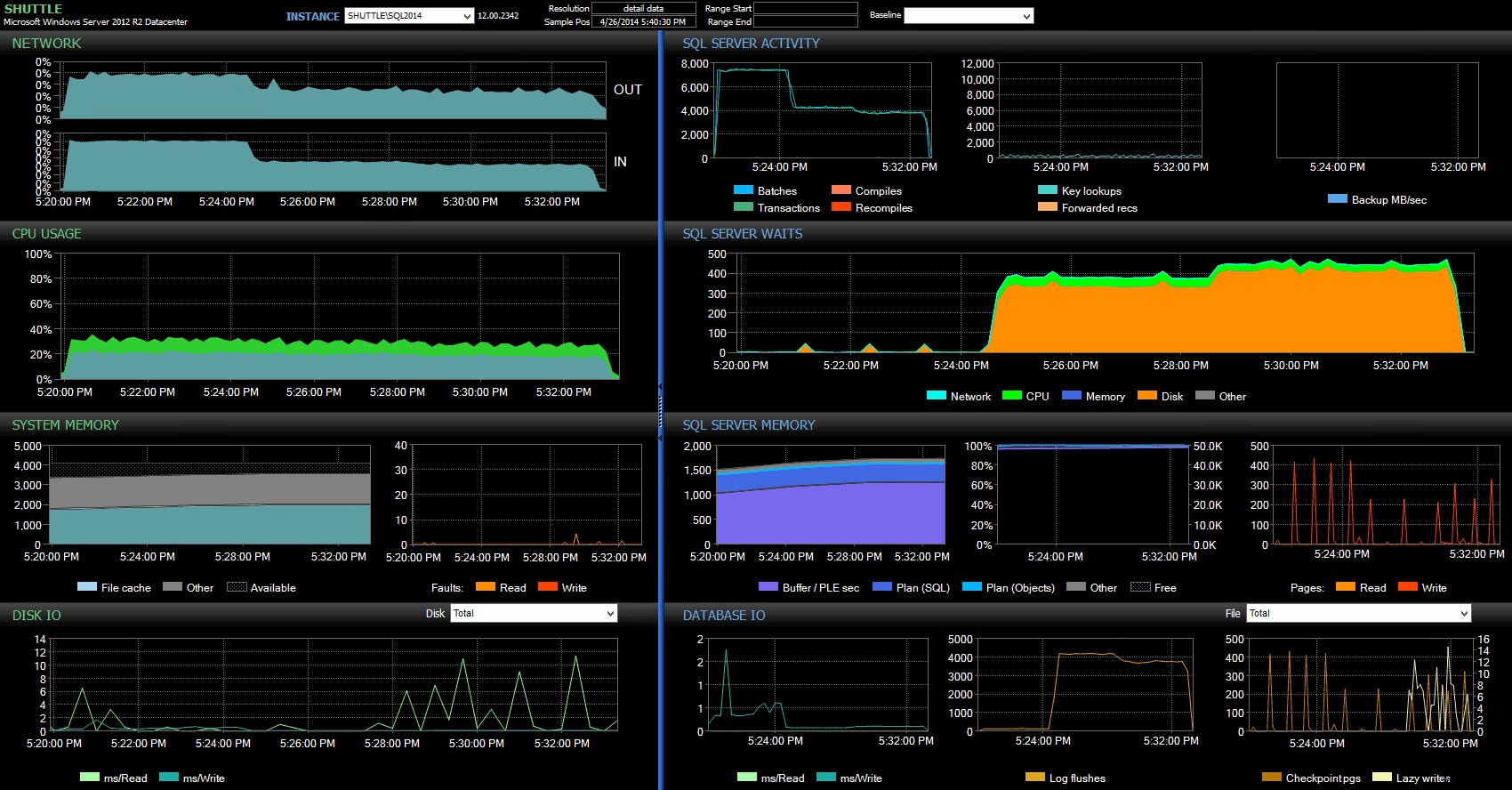
Painel do SQL Sentry – clique para ampliar
Outras observações aqui:
- Em vários gráficos, você pode ver claramente quando a parte de durabilidade sem atraso do lote assumiu (~5:24:32 PM).
- Não há impacto observável na CPU ou na memória ao usar a durabilidade atrasada.
- Você pode ver um tremendo impacto nos lotes/transações por segundo no primeiro gráfico em Atividade do SQL Server.
- As esperas do SQL Server atingem o limite quando as transações totalmente duráveis são iniciadas. Estes eram compostos quase exclusivamente por
WRITELOGesperas, com um pequeno número dePAGEIOLOATCH_EXePAGEIOLATCH_UPespera por uma boa medida. - O número total de liberações de log nas operações de Durabilidade Atrasada foi bem pequeno (baixo 100s/s), enquanto isso saltou para mais de 4.000/s para o comportamento tradicional (e um pouco menor para a duração do HDD do teste).
Menos transações maiores
Para o próximo teste, eu queria ver o que aconteceria se realizássemos menos operações, mas garantimos que cada instrução afetasse uma quantidade maior de dados. Eu queria que este lote fosse executado em cada banco de dados:
CREATE TABLE dbo.Rnd
(
batch TINYINT,
TheID INT
);
INSERT dbo.Rnd SELECT TOP (1000) 1, TheID FROM dbo.TheTable ORDER BY NEWID();
INSERT dbo.Rnd SELECT TOP (10) 2, TheID FROM dbo.TheTable ORDER BY NEWID();
INSERT dbo.Rnd SELECT TOP (300) 3, TheID FROM dbo.TheTable ORDER BY NEWID();
GO
INSERT #Metrics SELECT 1, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID('dd1'), 2);
GO
UPDATE t SET TheDate = DATEADD(MINUTE, 1, TheDate)
FROM dbo.TheTable AS t
INNER JOIN dbo.Rnd AS r
ON t.TheID = r.TheID
WHERE r.batch = 1;
GO 10000
UPDATE t SET RowGuid = NEWID()
FROM dbo.TheTable AS t
INNER JOIN dbo.Rnd AS r
ON t.TheID = r.TheID
WHERE r.batch = 2;
GO 10000
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID FROM dbo.Rnd WHERE batch = 3);
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID+1 FROM dbo.Rnd WHERE batch = 3);
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID-1 FROM dbo.Rnd WHERE batch = 3);
GO
INSERT #Metrics SELECT 2, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID('dd1'), 2); Então, novamente, usei o método lazy para produzir 8 cópias deste script, uma por banco de dados:
;WITH x AS (SELECT TOP (8) number FROM master..spt_values WHERE type = N'P' ORDER BY number)
SELECT N'
USE dd' + RTRIM(Number+1) + ';
GO
CREATE TABLE dbo.Rnd
(
batch TINYINT,
TheID INT
);
INSERT dbo.Rnd SELECT TOP (1000) 1, TheID FROM dbo.TheTable ORDER BY NEWID();
INSERT dbo.Rnd SELECT TOP (10) 2, TheID FROM dbo.TheTable ORDER BY NEWID();
INSERT dbo.Rnd SELECT TOP (300) 3, TheID FROM dbo.TheTable ORDER BY NEWID();
GO
INSERT #Metrics SELECT 2, 1, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID(''dd' + RTRIM(number+1) + ''', 2);
GO
UPDATE t SET TheDate = DATEADD(MINUTE, 1, TheDate)
FROM dbo.TheTable AS t
INNER JOIN dbo.rnd AS r
ON t.TheID = r.TheID
WHERE r.cycle = 1;
GO 10000
UPDATE t SET RowGuid = NEWID()
FROM dbo.TheTable AS t
INNER JOIN dbo.rnd AS r
ON t.TheID = r.TheID
WHERE r.cycle = 2;
GO 10000
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID FROM dbo.rnd WHERE cycle = 3);
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID+1 FROM dbo.rnd WHERE cycle = 3);
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID-1 FROM dbo.rnd WHERE cycle = 3);
GO
INSERT #Metrics SELECT 2, 2, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID(''dd' + RTRIM(number+1) + '''), 2);'
FROM x; Executei este lote e alterei a consulta em
#Metrics acima para ver o segundo teste em vez do primeiro. Os resultados:| banco de dados | escreve | bytes | bytes/gravação | io_stall_ms | start_time | end_time | duração (segundos) |
|---|---|---|---|---|---|---|---|
| dd1 | 20.970 | 1.271.911.936 | 60.653,88 | 12.577 | 2014-04-26 17:41:21 | 2014-04-26 17:43:46 | 145 |
| dd2 | 20.997 | 1.272.145.408 | 60.587,00 | 14.698 | 2014-04-26 17:43:46 | 2014-04-26 17:46:11 | 145 |
| dd3 | 20.973 | 1.272.982.016 | 60.696,22 | 12.085 | 2014-04-26 17:46:11 | 2014-04-26 17:48:33 | 142 |
| dd4 | 20.958 | 1.272.064.512 | 60.695,89 | 11.795 | 143 | ||
| dd5 | 30.138 | 1.282.231.808 | 42.545,35 | 7.402 | 26/04/2014 17:50:56 | 2014-04-26 17:53:23 | 147 |
| dd6 | 30.138 | 1.282.260.992 | 42.546,31 | 7.806 | 2014-04-26 17:53:23 | 2014-04-26 17:55:53 | 150 |
| dd7 | 30.129 | 1.281.575.424 | 42.536,27 | 9.888 | 2014-04-26 17:55:53 | 2014-04-26 17:58:25 | 152 |
| dd8 | 30.130 | 1.281.449.472 | 42.530,68 | 11.452 | 2014-04-26 17:58:25 | 2014-04-26 18:00:55 | 150 |
Transações maiores:duração e resultados de sys.dm_io_virtual_file_stats
Desta vez, o impacto da Durabilidade Atrasada é muito menos perceptível. Vemos um número um pouco menor de operações de gravação, com um número um pouco maior de bytes por gravação, com o total de bytes gravados quase idênticos. Neste caso, vemos que os stalls de E/S são maiores para Durabilidade Atrasada, e isso provavelmente explica o fato de que as durações também eram quase idênticas.
No painel do Performance Advisor, encontramos algumas semelhanças com o teste anterior e também algumas diferenças gritantes:
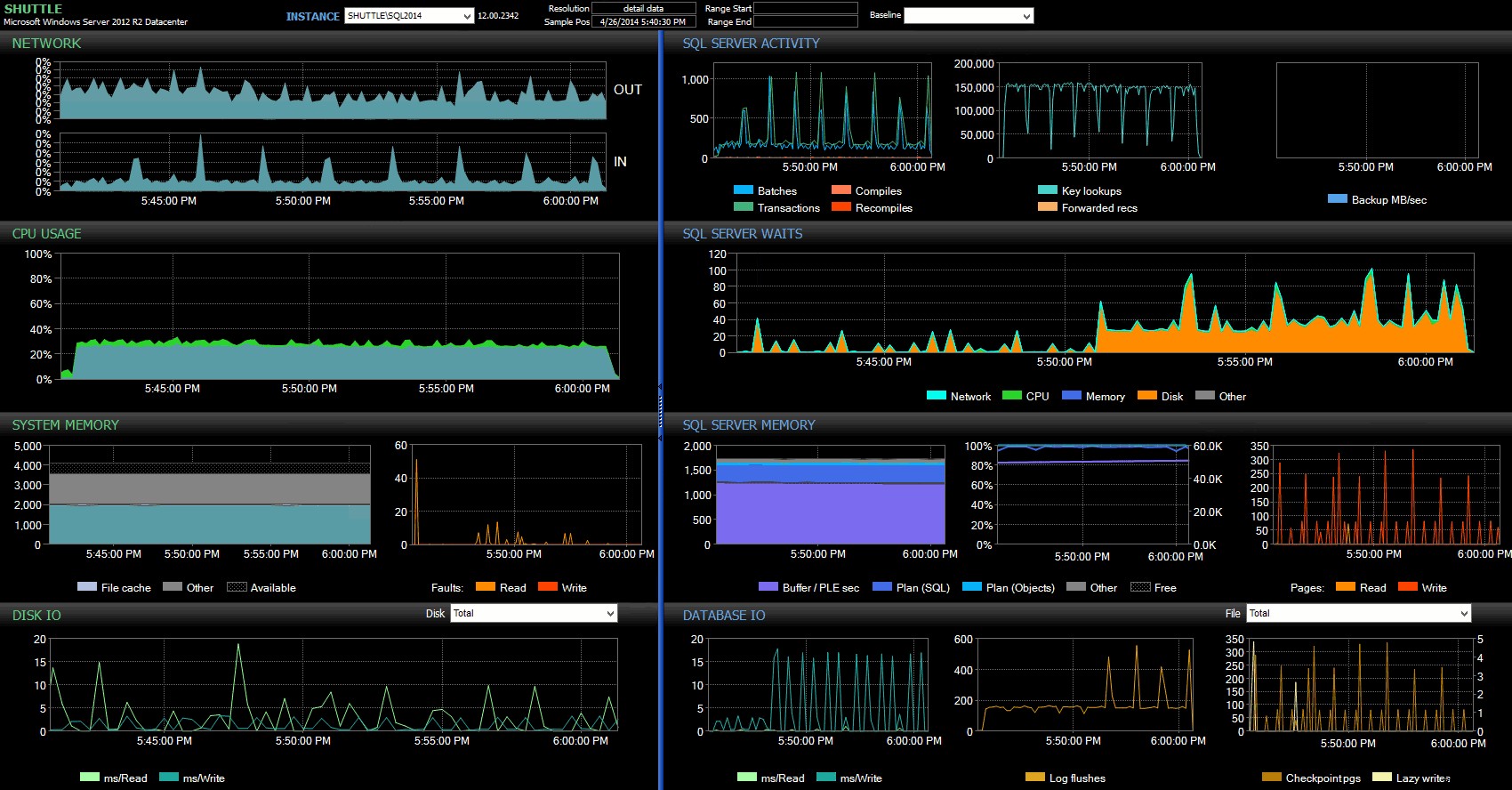
Painel do SQL Sentry – clique para ampliar
Uma das grandes diferenças a destacar aqui é que o delta nas estatísticas de espera não é tão pronunciado quanto no teste anterior – ainda há uma frequência muito maior de
WRITELOG aguarda os lotes totalmente duráveis, mas não chega nem perto dos níveis vistos com as transações menores. Outra coisa que você pode perceber imediatamente é que o impacto observado anteriormente em lotes e transações por segundo não está mais presente. E, finalmente, embora haja mais liberações de log com transações totalmente duráveis do que quando atrasadas, essa disparidade é muito menos pronunciada do que com transações menores. Conclusão
Deve ficar claro que existem certos tipos de carga de trabalho que podem se beneficiar muito da Durabilidade Atrasada - desde, é claro, que você tenha uma tolerância para perda de dados . Esse recurso não está restrito ao OLTP na memória, está disponível em todas as edições do SQL Server 2014 e pode ser implementado com pouca ou nenhuma alteração de código. Certamente pode ser uma técnica poderosa se sua carga de trabalho puder suportá-la. Mas, novamente, você precisará testar sua carga de trabalho para ter certeza de que ela se beneficiará desse recurso e também considerar se isso aumenta sua exposição ao risco de perda de dados.
Como um aparte, isso pode parecer para a multidão do SQL Server como uma nova ideia, mas na verdade a Oracle introduziu isso como "Asynchronous Commit" em 2006 (consulte
COMMIT WRITE ... NOWAIT conforme documentado aqui e publicado no blog em 2007). E a ideia em si já existe há quase 3 décadas; ver breve crônica de Hal Berenson de sua história. Próxima vez
Uma ideia que tenho desenvolvido é tentar melhorar o desempenho do
tempdb forçando a Durabilidade Atrasada lá. Uma propriedade especial de tempdb que o torna um candidato tão tentador é que ele é transitório por natureza – qualquer coisa em tempdb é projetado, explicitamente, para ser lançado após uma ampla variedade de eventos do sistema. Estou dizendo isso agora sem ter a menor ideia se existe uma forma de carga de trabalho em que isso funcione bem; mas pretendo experimentá-lo, e se encontrar algo interessante, pode ter certeza que postarei sobre isso aqui.