Há um bug de regressão no SQL Server 2012 e no SQL Server 2014 em que, se você reconstruir um índice online em paralelo e também ocorrer um erro fatal, como um tempo limite de bloqueio, poderá ocorrer perda ou corrupção de dados . Este deve ser um cenário relativamente raro (Phil Brammer tem uma reprodução simples no Connect # 795134), mas perda de dados é perda de dados e não estou preparado para jogar. A correção é descrita em KB #2969896:CORREÇÃO:A perda de dados no índice clusterizado ocorre quando você executa o índice de compilação online no SQL Server 2012.
Nem todo mundo precisa se preocupar com essa questão. Se você não estiver executando a edição Enterprise (ou equivalente), não poderá executar reconstruções paralelas ou online em primeiro lugar (e provavelmente há algumas pessoas no Enterprise que não estão reconstruindo ou não reconstruindo online). Se você tiver
MAXDOP em toda a instância definido como 1, eles não podem ficar paralelos, a menos que você o substitua no nível da instrução. Mas, se você estiver em 2012 ou 2014, executando uma edição adequada e suas reconstruções online puderem ser paralelas, você estará vulnerável a esse problema. Como mencionei acima, esse problema pode se manifestar no SQL Server 2012 RTM, Service Pack 1 e até mesmo no Service Pack 2, lançado em 10 de junho. O bug não foi corrigido até muito tempo depois que o código do SP2 foi congelado, então o SP2 não não inclui esta correção ou qualquer uma das correções do SP1 CU #10 ou #11. Eu blogei sobre isso aqui. A ramificação RTM está oficialmente sem suporte, então você não verá uma correção lá. O problema também pode ocorrer no SQL Server 2014.
Agora há atualizações cumulativas disponíveis para o SQL Server 2012 Service Pack 1 e 2, bem como para o SQL Server 2014. Um breve resumo das opções que recomendo:
Se sua ramificação / @@VERSION for…
| …você deveria… | ||||
|---|---|---|---|---|---|
| |||||
| |||||
| Não faça nada; você já tem a correção. | |||||
| |||||
| Não faça nada; você já tem a correção. | |||||
| SQL Server 2014 RTM |
| ||||
| Não faça nada; você já tem a correção. | |||||
| * Se você instalar o hotfix do SP1 ou a atualização cumulativa nº 11 e depois instalar o SP2, você desfará essas alterações, incluindo esta correção. | |||||
Soluções para o avesso ao hotfix/CU
Como todas as ramificações afetadas (bem, exceto 2012 RTM) têm um hotfix sob demanda e/ou uma atualização cumulativa que soluciona o problema, a resposta fácil é apenas instalar a atualização relevante. No entanto, você pode estar em um cenário em que a política da sua empresa ou os ciclos de teste impedem que você implante essas atualizações rapidamente, ou talvez nunca. Então, quais outras opções você tem?
- Você pode parar de realizar reconstruções até que haja um novo service pack disponível para sua ramificação (talvez você possa ficar com
REORGANIZEpor enquanto). Infelizmente, se você estiver em uma empresa "somente service pack", suas opções são muito limitadas:você pode lutar mais para mudar essa política ou pode esperar pelo SQL Server 2012 Service Pack 3 (que pode levar muito tempo ou pode simplesmente nunca vem – veja a FAQ nº 21 aqui) ou SQL Server 2014 Service Pack 1 (que provavelmente não veremos antes de 2015 chegar). - Você pode definir o
max degree of parallelismem toda a instância para 1, no entanto, isso pode ter um efeito negativo no restante de sua carga de trabalho - pense em coisas como DBCC multithread, consultas paralelas em ou entre tabelas particionadas e outras operações em que você pode querer reduzir o paralelismo, mas não eliminá-lo completamente. Além disso, essa configuração não afetará uma reconstrução online com, digamos, umMAXDOP = 8explícito codificado no comando, pois isso substituirá osp_configureconfiguração.
- Você pode adicionar o
WITH (MAXDOP = 1)opção manualmente para todos os seus comandos de reconstrução. (Observação:você não precisa fazer isso para índices XML, pois eles executam inerentemente single-thread, mas eu apenas aplicaria a todas as reconstruções para consistência e para evitar qualquer lógica condicional desnecessária.)
- Você pode definir seus trabalhos de manutenção de índice para serem executados como um login específico e, em seguida, usar o Resource Governor para criar um grupo de carga de trabalho que limite o
MAX_DOPdesse login para 1, independentemente do que eles estão fazendo. Tenho um exemplo disso no white paper de 2008 que escrevi com Boris Baryshnikov, Using the Resource Governor, na seção intitulada "Limiting Parallelism for Intensive Background Jobs".
- Se você estiver usando a solução de manutenção de índice de Ola Hallengren, poderá adicionar o
@MaxDopparâmetro para suas chamadas paradbo.IndexOptimize:
EXEC dbo.IndexOptimize /* other parameters */ @MaxDop = 1; - Se você estiver usando o SQL Sentry Fragmentation Manager, poderá ditar o nível de
MAXDOPpara usar em Configurações - e você pode fazer isso em toda a empresa, por instância, por banco de dados ou até mesmo por índice individual (neste caso, você provavelmente deseja definir isso por instância, para todas as instâncias sem uma correção disponível):
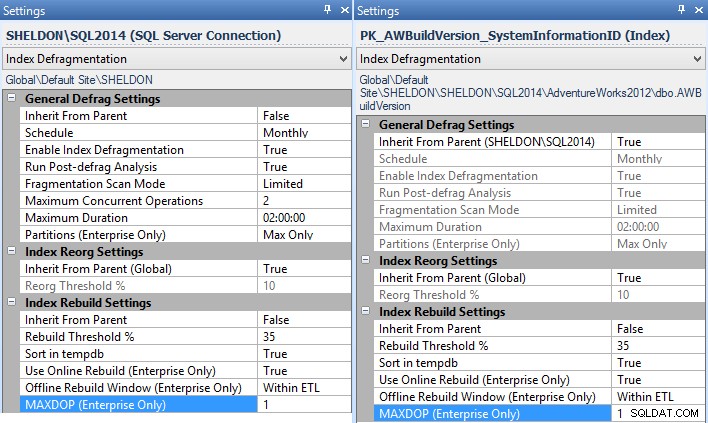
Configurações do Gerenciador de fragmentação para a instância (esquerda) e um índice individual (direita).
- Se você estiver usando Planos de Manutenção para suas recompilações de índice, terá que alterá-los para usar Executar Tarefas de Instrução T-SQL e escrever seu
ALTER INDEX ... WITH (ONLINE = ON, MAXDOP = 1);comandos manualmente (assim pode mudar para uma solução automatizada). Veja, a tarefa de reconstrução de índice não tem uma propriedade exposta paraMAXDOP, embora tenha sido solicitado várias vezes (mais recentemente em 2012, por Alberto Morillo, e já em 2006, por Linchi Shea). E veja todas essas outras propriedades úteis que eles expõem, comoAdvSortInTempdb,ObjectTypeSelectioneTaskAllowesDatbaseSelection[sic!]:
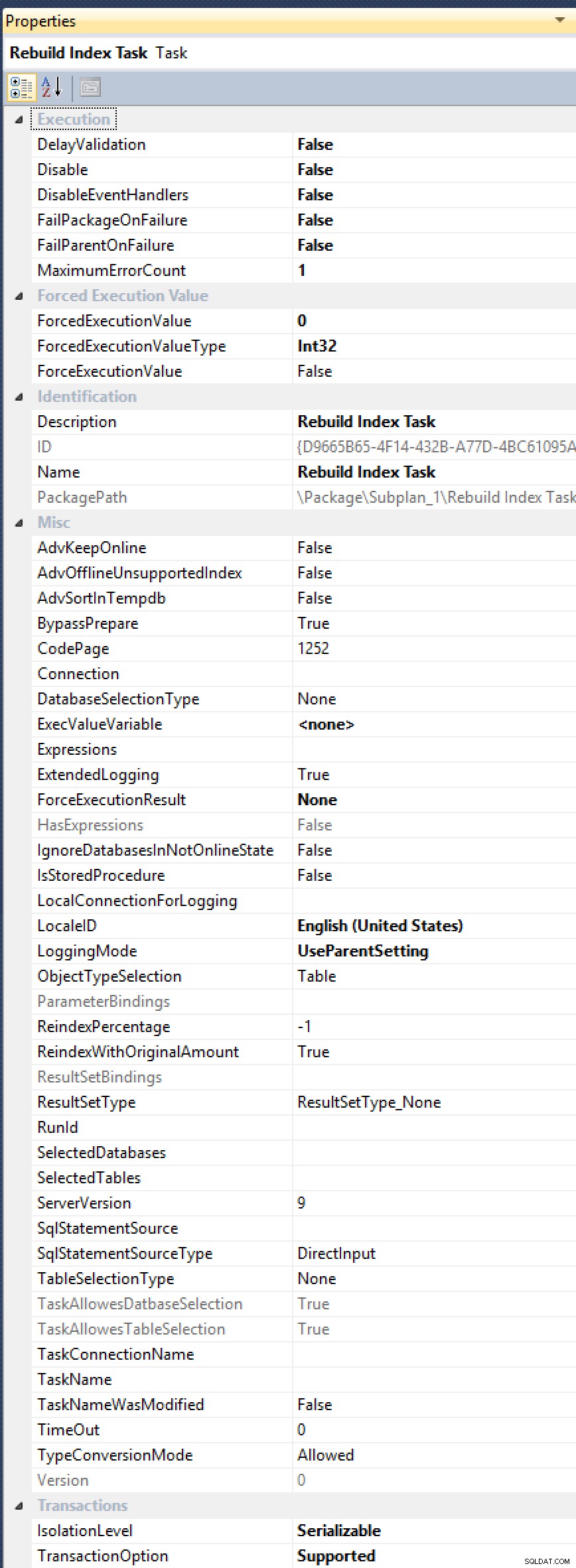
Todas essas opções, mas ainda não há cura para MAXDOP.