Captura de tela nº1 mostra alguns pontos para distinguir entre a
Merge Join transformation e Lookup transformation . Em relação à pesquisa:
Se você quiser encontrar linhas correspondentes na fonte 2 com base na entrada da fonte 1 e se souber que haverá apenas uma correspondência para cada linha de entrada, sugiro usar a operação de pesquisa. Um exemplo seria você
OrderDetails tabela e você deseja encontrar o Order Id correspondente e Customer Number , então Lookup é uma opção melhor. Em relação à junção de mesclagem:
Se você deseja realizar junções como buscar todos os endereços (casa, trabalho, outro) de
Address tabela para um determinado cliente no Customer table, então você tem que ir com Merge Join porque o cliente pode ter 1 ou mais endereços associados a eles. Um exemplo para comparar:
Aqui está um cenário para demonstrar as diferenças de desempenho entre
Merge Join e Lookup . Os dados usados aqui são uma junção de um para um, que é o único cenário comum entre eles para comparação. -
Eu tenho três tabelas chamadasdbo.ItemPriceInfo,dbo.ItemDiscountInfoedbo.ItemAmount. Os scripts de criação para essas tabelas são fornecidos na seção Scripts SQL.
-
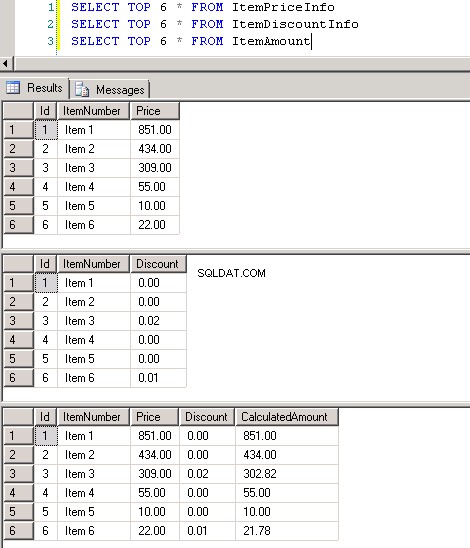
Tabelasdbo.ItemPriceInfoedbo.ItemDiscountInfoambos têm 13.349.729 linhas. Ambas as tabelas têm o ItemNumber como coluna comum. ItemPriceInfo tem informações de preço e ItemDiscountInfo tem informações de desconto. Captura de tela nº2 mostra a contagem de linhas em cada uma dessas tabelas. Captura de tela nº3 mostra as 6 primeiras linhas para dar uma ideia sobre os dados presentes nas tabelas.
-
Criei dois pacotes SSIS para comparar o desempenho das transformações Merge Join e Lookup. Ambos os pacotes precisam pegar as informações das tabelasdbo.ItemPriceInfoedbo.ItemDiscountInfo, calcule o valor total e salve-o na tabeladbo.ItemAmount.
-
Primeiro pacote usadoMerge Jointransformação e dentro dela usou INNER JOIN para combinar os dados. Capturas de tela #4 e #5 mostre a execução do pacote de amostra e a duração da execução. Demorou05minutos14segundos719milissegundos para executar o pacote baseado na transformação Merge Join.
-
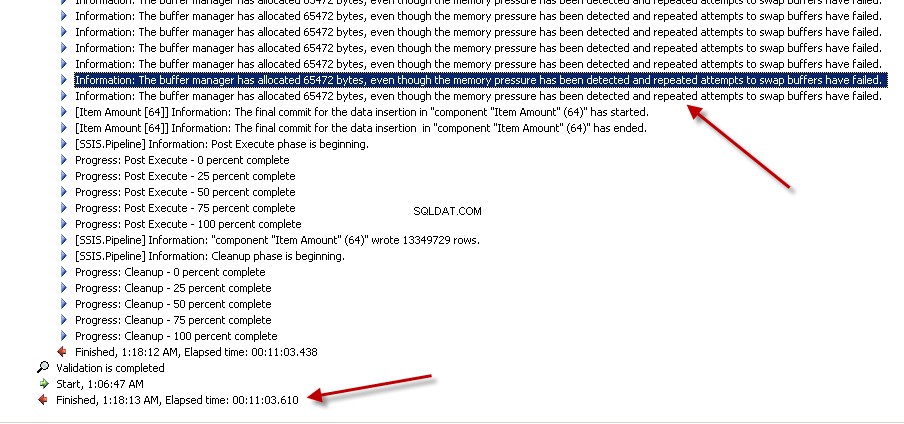
Segundo pacote usadoLookuptransformação com cache completo (que é a configuração padrão). capturas de tela #6 e #7 mostre a execução do pacote de amostra e a duração da execução. Demorou11minutos03segundos610milissegundos para executar o pacote baseado em transformação Lookup. Você pode encontrar a mensagem de aviso Informações:The buffer manager has allocated nnnnn bytes, even though the memory pressure has been detected and repeated attempts to swap buffers have failed.Aqui está um link que fala sobre como calcular o tamanho do cache de pesquisa. Durante a execução deste pacote, embora a tarefa de fluxo de dados tenha sido concluída mais rapidamente, a limpeza do pipeline levou muito tempo.
-
Isso não significa que a transformação de pesquisa é ruim. É só que ele tem que ser usado com sabedoria. Eu uso isso com bastante frequência em meus projetos, mas, novamente, não lido com mais de 10 milhões de linhas para pesquisa todos os dias. Normalmente, meus trabalhos lidam com entre 2 e 3 milhões de linhas e, para isso, o desempenho é muito bom. Até 10 milhões de linhas, ambas com desempenho igual. Na maioria das vezes, o que tenho notado é que o gargalo acaba sendo o componente de destino e não as transformações. Você pode superar isso tendo vários destinos. Aqui é um exemplo que mostra a implementação de vários destinos.
-
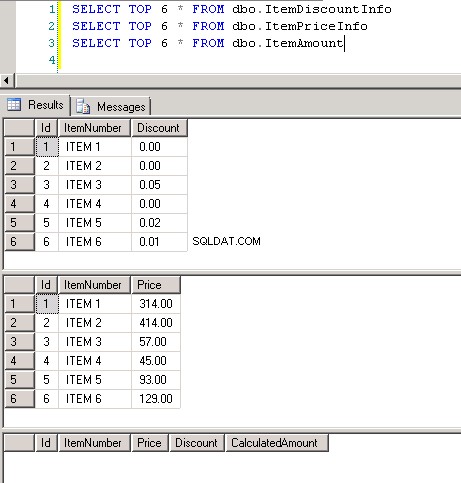
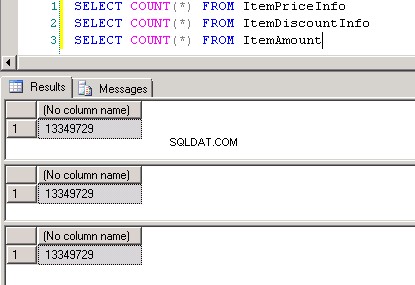
Captura de tela nº8 mostra a contagem de registros em todas as três tabelas. Captura de tela nº9 mostra os 6 principais registros em cada uma das tabelas.
Espero que ajude.
Scripts SQL:
CREATE TABLE [dbo].[ItemAmount](
[Id] [int] IDENTITY(1,1) NOT NULL,
[ItemNumber] [nvarchar](30) NOT NULL,
[Price] [numeric](18, 2) NOT NULL,
[Discount] [numeric](18, 2) NOT NULL,
[CalculatedAmount] [numeric](18, 2) NOT NULL,
CONSTRAINT [PK_ItemAmount] PRIMARY KEY CLUSTERED ([Id] ASC)) ON [PRIMARY]
GO
CREATE TABLE [dbo].[ItemDiscountInfo](
[Id] [int] IDENTITY(1,1) NOT NULL,
[ItemNumber] [nvarchar](30) NOT NULL,
[Discount] [numeric](18, 2) NOT NULL,
CONSTRAINT [PK_ItemDiscountInfo] PRIMARY KEY CLUSTERED ([Id] ASC)) ON [PRIMARY]
GO
CREATE TABLE [dbo].[ItemPriceInfo](
[Id] [int] IDENTITY(1,1) NOT NULL,
[ItemNumber] [nvarchar](30) NOT NULL,
[Price] [numeric](18, 2) NOT NULL,
CONSTRAINT [PK_ItemPriceInfo] PRIMARY KEY CLUSTERED ([Id] ASC)) ON [PRIMARY]
GO
Captura de tela nº 1:

Captura de tela nº 2:
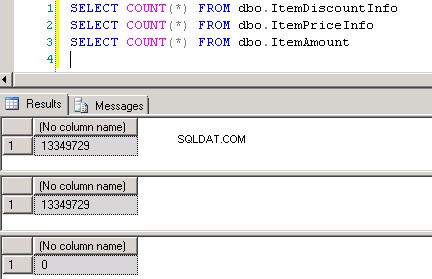
Captura de tela nº 3:
Captura de tela nº 4:
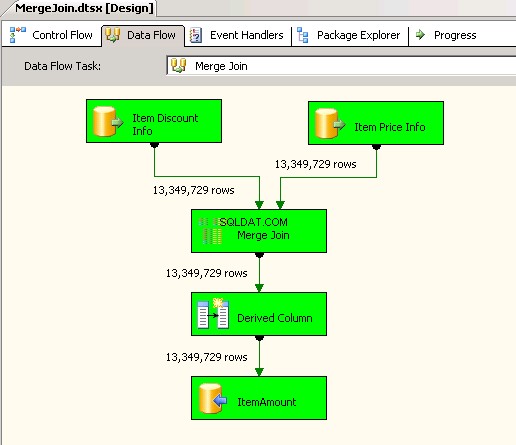
Captura de tela nº 5:

Captura de tela nº 6:
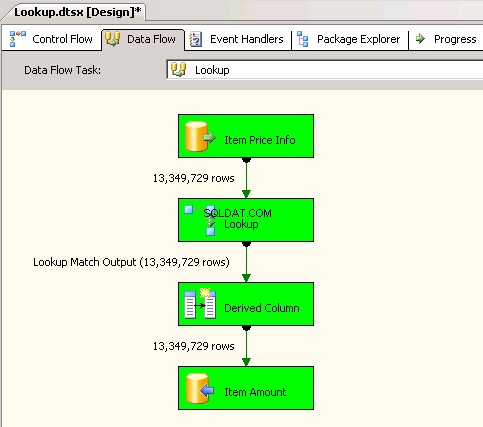
Captura de tela nº 7:
Captura de tela nº 8:
Captura de tela nº 9: