Um exemplo em que isso pode fazer a diferença é que pode impedir uma otimização de desempenho que evita a adição de informações de versão de linha a tabelas com gatilhos posteriores.
Isso é coberto por Paul White aqui
O tamanho real dos dados armazenados é irrelevante – é o tamanho potencial que importa.
Da mesma forma, se usando tabelas com otimização de memória desde 2016, foi possível usar colunas LOB ou combinações de larguras de coluna que poderiam exceder o limite de linhas, mas com uma penalidade.
(Max) colunas são sempre armazenadas fora da linha. Para outras colunas, se o tamanho da linha de dados na definição da tabela puder exceder 8.060 bytes, o SQL Server enviará as maiores colunas de comprimento variável para fora da linha. Novamente, não depende da quantidade de dados que você armazena lá.
Isso pode ter um grande efeito negativo no consumo de memória e no desempenho
Outro caso em que a declaração excessiva de larguras de coluna pode fazer uma grande diferença é se a tabela será processada usando o SSIS. A memória alocada para colunas de comprimento variável (não BLOB) é fixa para cada linha em uma árvore de execução e é de acordo com o comprimento máximo declarado das colunas, o que pode levar ao uso ineficiente de buffers de memória (exemplo). Embora o desenvolvedor do pacote SSIS possa declarar um tamanho de coluna menor do que a origem, essa análise é melhor feita antecipadamente e aplicada lá.
De volta ao próprio mecanismo do SQL Server, um caso semelhante é que, ao calcular a concessão de memória para alocar para
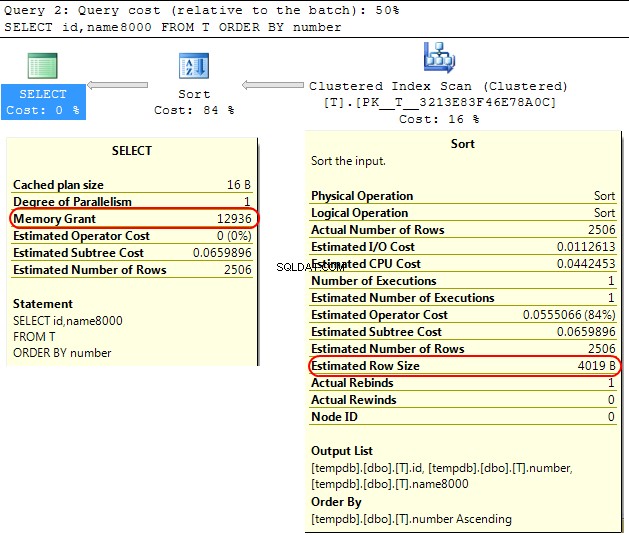
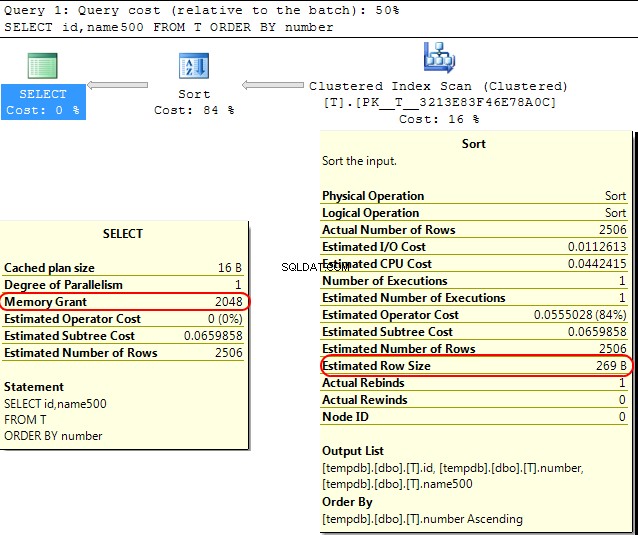
SORT operações O SQL Server assume que varchar(x) as colunas consumirão em média x/2 bytes. Se a maior parte do seu
varchar colunas estão mais cheias do que isso pode levar ao sort operações derramando para tempdb . No seu caso, se o seu
varchar colunas são declaradas como 8000 bytes, mas na verdade tem conteúdo muito menor do que sua consulta será alocada memória que não requer, o que é obviamente ineficiente e pode levar a esperas por concessões de memória. Isso é abordado na Parte 2 do SQL Workshops Webcast 1, que pode ser baixado aqui ou veja abaixo.
use tempdb;
CREATE TABLE T(
id INT IDENTITY(1,1) PRIMARY KEY,
number int,
name8000 VARCHAR(8000),
name500 VARCHAR(500))
INSERT INTO T
(number,name8000,name500)
SELECT number, name, name /*<--Same contents in both cols*/
FROM master..spt_values
SELECT id,name500
FROM T
ORDER BY number
SELECT id,name8000
FROM T
ORDER BY number