Introdução
Arquivos de dados são objetos físicos que constituem a parte mais importante do sistema de banco de dados, pois contêm dados reais. Você pode pensar em um banco de dados como uma coleção de arquivos de dados. Uma instância fornece os meios de montar e acessar esses arquivos.
Aqui, gerenciar arquivos de dados é entender como monitorar e redimensionar arquivos de dados existentes e como adicionar ou remover os arquivos de dados de um banco de dados.
Os códigos T-SQL para essas operações estão presentes na documentação da Microsoft. No entanto, neste artigo, gostaríamos de discutir as táticas de gerenciamento desses arquivos para aqueles que ainda executam instalações locais do SQL Server.
Tipos de arquivos de dados e possíveis problemas
Para cada novo banco de dados criado no SQL Server, devemos ter pelo menos dois arquivos criados – um arquivo de dados primário e um arquivo de log.
- O arquivo de dados principal tem a extensão .MDF.
- O arquivo de log tem a extensão .LDF.
- Quando adicionamos arquivos de dados a um banco de dados SQL Server, normalmente usamos a extensão .NDF.
Observação :é possível criar os arquivos de dados no SQL Server sem nenhuma extensão, mas essa não é a melhor prática. Usar .mdf, .ndf e .ldf serve para distinguir esses arquivos quando os visualizamos em nível de sistema operacional.
Obviamente, os arquivos de dados são criados quando você cria um banco de dados. Você pode fazer isso com o CREATE DATABASE comando. Embora pareça tão fácil, você deve estar ciente dos possíveis problemas.
Dependendo do tamanho do banco de dados e de seus arquivos de dados associados, você pode enfrentar problemas de fragmentação e outros problemas com o tempo de backup e movimentação de seus dados. Acontece que os arquivos de dados não estão dimensionados corretamente.
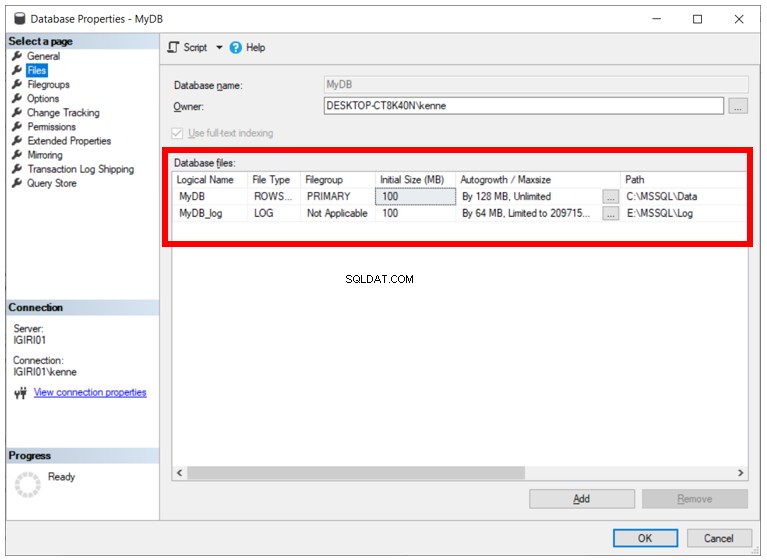
Dê uma olhada na ilustração abaixo. Ele mostra o resultado da execução de CREATE DATABASE e fornece o nome do banco de dados (MyDB).
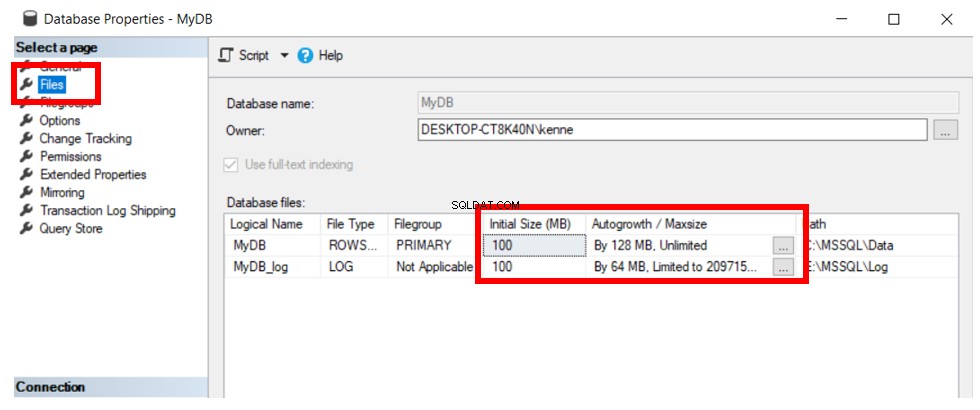
A Listagem 1 mostra os detalhes do banco de dados criado:
-- Listing 1: Create Database Script
USE [master]
GO
/****** Object: Database [MyDB] Script Date: 29/11/2020 10:38:18 pm ******/
CREATE DATABASE [MyDB]
CONTAINMENT = NONE
ON PRIMARY
( NAME = N'MyDB', FILENAME = N'C:\MSSQL\Data\MyDB.mdf' , SIZE = 102400KB , MAXSIZE = UNLIMITED, FILEGROWTH = 131072KB )
LOG ON
( NAME = N'MyDB_log', FILENAME = N'E:\MSSQL\Log\MyDB_log.ldf' , SIZE = 102400KB , MAXSIZE = 2048GB , FILEGROWTH = 65536KB )
GO
IF (1 = FULLTEXTSERVICEPROPERTY('IsFullTextInstalled'))
begin
EXEC [MyDB].[dbo].[sp_fulltext_database] @action = 'enable'
end
GO
Você pode se perguntar de onde o SQL Server obteve todas essas opções, já que tudo o que fizemos foi emitir CREATE DATABASE MyDB.
O SQL Server usa as configurações do banco de dados modelo como valores padrão para qualquer novo banco de dados criado nessa instância. Nesse caso, vemos o tamanho inicial do arquivo de 100 MB. O crescimento automático é de 12 MB e 64 MB, respectivamente, para os arquivos de dados e log.
Os problemas subsequentes
A implicação das configurações destacadas na Figura 1 são:
- O arquivo de dados principal começa no tamanho de 100 MB. É um tamanho pequeno. Assim, dependendo do nível de atividade no banco de dados, ele precisará crescer muito em breve.
- Sempre que houver necessidade de aumento automático o arquivo de dados, o SQL Server precisa adquirir 128 MB do espaço disponível no sistema operacional. Novamente, é pequeno, o que implica que o banco de dados crescerá automaticamente frequentemente . O crescimento do banco de dados é uma operação cara que pode afetar o desempenho se ocorrer com muita frequência. Além disso, o crescimento frequente do banco de dados pode causar um fenômeno chamado fragmentação que, por sua vez, tem o dom de causar grave degradação do desempenho dos bancos de dados. O outro extremo de definir o incremento para um valor alto pode resultar em operações de crescimento demoradas para serem concluídas, dependendo do desempenho do sistema de armazenamento subjacente.
- Os arquivos de banco de dados podem crescer indefinidamente. Isso significa que, com um tempo suficiente permitido, esses arquivos podem consumir todo o espaço do volume onde estão. Para movê-los, você precisa de um volume do tamanho deles ou mais. Outra opção é adicionar armazenamento ao volume quando esses arquivos estiverem parados.
Esses são os principais problemas associados à dependência de valores padrão para a criação de bancos de dados.
Pré-alocação
Dado o impacto do crescimento no desempenho, faria mais sentido dimensionar adequadamente o banco de dados no início do projeto. Dessa forma, acomodamos os requisitos da solução para o futuro próximo.
Suponha que sabemos que nosso banco de dados acabará tendo 1 GB de tamanho. Podemos alocar 1 GB de armazenamento quando o projeto começar. Então, o banco de dados nunca precisa crescer. Elimina os problemas de fragmentação causados pelo crescimento do banco de dados.
A Listagem 2 mostra o script aplicável para esta pré-alocação:
-- Listing 2: Create Database Script with Pre-allocation
USE [master]
GO
/****** Object: Database [MyDB] Script Date: 29/11/2020 10:38:18 pm ******/
CREATE DATABASE [MyDB]
CONTAINMENT = NONE
ON PRIMARY
( NAME = N'MyDB', FILENAME = N'C:\MSSQL\Data\MyDB.mdf' , SIZE = 1024MB , MAXSIZE = 2048MB, FILEGROWTH = 512MB )
LOG ON
( NAME = N'MyDB_log', FILENAME = N'E:\MSSQL\Log\MyDB_log.ldf' , SIZE = 512MB , MAXSIZE = 2048GB , FILEGROWTH = 512MB )
GO
IF (1 = FULLTEXTSERVICEPROPERTY('IsFullTextInstalled'))
begin
EXEC [MyDB].[dbo].[sp_fulltext_database] @action = 'enable'
end
GO
Mencionamos 1 GB de espaço para fins de demonstração. Normalmente, um banco de dados de produção pode exigir 1 TB. O ponto é:alocar o espaço necessário no início. Então você elimina ou reduz significativamente a necessidade de crescimento.
Agora, devemos nos perguntar se realmente queremos um único arquivo de 1 TB em nosso volume. Seria sensato dividi-lo em pedaços menores. Quando ocorrerem operações paralelas, como backups, cada arquivo será endereçado por um único thread de CPU para um sistema multiprocessador. Com um único arquivo, não iria bem.
Novamente, modificamos nosso script para acomodar esse requisito na Listagem 3:
-- Listing 3: Create Database Script with Pre-allocation and
USE [master]
GO
/****** Object: Database [MyDB] Script Date: 29/11/2020 10:38:18 pm ******/
CREATE DATABASE [MyDB]
CONTAINMENT = NONE
ON PRIMARY
( NAME = N'MyDB01', FILENAME = N'C:\MSSQL\Data\MyDB01.mdf' , SIZE = 256MB , MAXSIZE = 512MB, FILEGROWTH = 512MB ) ,
( NAME = N'MyDB02', FILENAME = N'C:\MSSQL\Data\MyDB02.ndf' , SIZE = 256MB , MAXSIZE = 512MB, FILEGROWTH = 512MB )
( NAME = N'MyDB03', FILENAME = N'C:\MSSQL\Data\MyDB03.ndf' , SIZE = 256MB , MAXSIZE = 512MB, FILEGROWTH = 512MB ) ,
( NAME = N'MyDB04', FILENAME = N'C:\MSSQL\Data\MyDB04.ndf' , SIZE = 256MB , MAXSIZE = 512MB, FILEGROWTH = 512MB ) ,
( NAME = N'MyDB05', FILENAME = N'C:\MSSQL\Data\MyDB05.ndf' , SIZE = 256MB , MAXSIZE = 512MB, FILEGROWTH = 512MB )
LOG ON
( NAME = N'MyDB_log', FILENAME = N'E:\MSSQL\Log\MyDB_log.ldf' , SIZE = 512MB , MAXSIZE = 2048GB , FILEGROWTH = 512MB )
GO
IF (1 = FULLTEXTSERVICEPROPERTY('IsFullTextInstalled'))
begin
EXEC [MyDB].[dbo].[sp_fulltext_database] @action = 'enable'
end
GO
Informações Adicionais
Devemos também mencionar que não há valor em usar essa abordagem para arquivos de log. O problema é que o SQL Server sempre grava nos arquivos de log sequencialmente. Além disso, usamos a extensão .ndf para os novos arquivos que estamos adicionando.
A cláusula MAXSIZE garante que nossos arquivos de dados não cresçam indefinidamente. Demos a cada arquivo um nome lógico e físico diferente – a cláusula NAME especifica o nome lógico do arquivo e a cláusula FILENAME especifica o nome físico.
Criar um banco de dados com arquivos de dados maiores levará mais tempo do que de outra forma. Pode ser mais razoável criar primeiro um banco de dados pequeno e depois manipulá-lo com comandos apropriados para redimensionar e adicionar arquivos, até estabelecermos uma estrutura de banco de dados ideal.
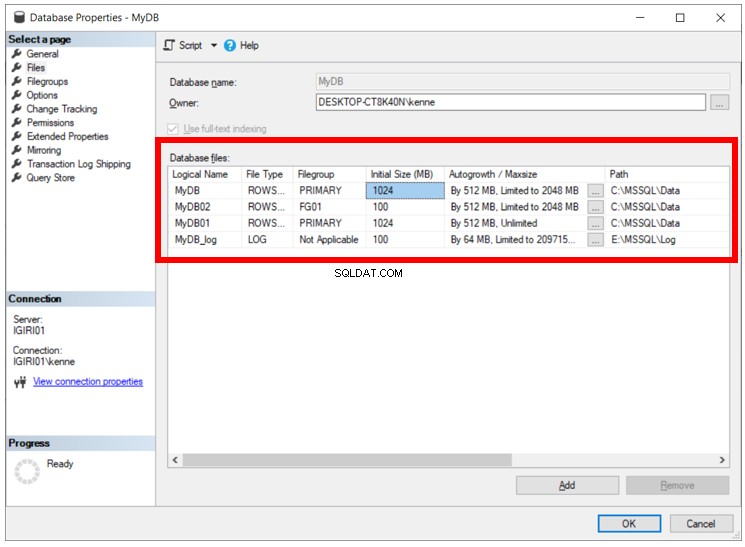
Ao criar o banco de dados com opções explícitas, abordamos as três preocupações levantadas anteriormente neste artigo. A Figura 2 mostra o resultado dessa abordagem:
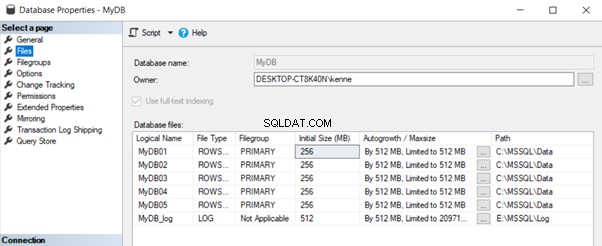
Agora temos um banco de dados devidamente configurado para acomodar o crescimento de dados por um período prolongado sem a necessidade de crescimento do arquivo de dados. Elimina os riscos de fragmentação e ajuda a garantir um melhor gerenciamento dos arquivos de dados.
Gerenciando arquivos de dados
Em vez de criar quatro ou cinco arquivos de dados na instrução CREATE DATABASE, podemos usar as cláusulas MODIFY e ADD da instrução T-SQL ALTER DATABASE.
Mais uma vez, começamos com a declaração mostrada na Listagem 4 abaixo. Ele cria um único banco de dados com o arquivo de dados de 100 MB e um arquivo de log que o acompanha. Nosso objetivo é garantir a pré-alocação estendendo esse arquivo e adicionando mais arquivos.
-- Listing 4: Create Database Script
USE [master]
GO
IF EXISTS (SELECT * FROM sys.databases WHERE name='MyDB')
DROP DATABASE MyDB;
/****** Object: Database [MyDB] Script Date: 29/11/2020 10:38:18 pm ******/
CREATE DATABASE [MyDB]
CONTAINMENT = NONE
ON PRIMARY
( NAME = N'MyDB', FILENAME = N'C:\MSSQL\Data\MyDB.mdf' , SIZE = 102400KB , MAXSIZE = UNLIMITED, FILEGROWTH = 131072KB )
LOG ON
( NAME = N'MyDB_log', FILENAME = N'E:\MSSQL\Log\MyDB_log.ldf' , SIZE = 102400KB , MAXSIZE = 2048GB , FILEGROWTH = 65536KB )
GO
IF (1 = FULLTEXTSERVICEPROPERTY('IsFullTextInstalled'))
begin
EXEC [MyDB].[dbo].[sp_fulltext_database] @action = 'enable'
end
GO
Estender arquivos de dados
A Instrução T-SQL que estende um arquivo de dados é mostrada na Listagem 5. Ela especifica o nome do banco de dados, o nome do arquivo e o tamanho inicial e o incremento desejados. Nesse caso, definimos o SQL Server para alocar 1 GB no início e, em seguida, alocar 512 MB para todos os crescimentos automáticos subsequentes.
-- Listing 5: Extend the Primary Datafile
USE [master]
GO
ALTER DATABASE [MyDB] MODIFY FILE ( NAME = N'MyDB', SIZE = 1048576KB , FILEGROWTH = 524288KB )
GO
A Listagem 6 mostra como seria o código se especificarmos o MAXSIZE de 2 GB:
-- Listing 6: Extend the Primary Datafile with Maximum Size
USE [master]
GO
ALTER DATABASE [MyDB] MODIFY FILE ( NAME = N'MyDB', SIZE = 1048576KB , MAXSIZE = 2097152KB , FILEGROWTH = 524288KB )
GO
Se definirmos a cláusula FILEGROWTH como 0, definiremos nosso SQL Server para NÃO aumentar automaticamente o arquivo de dados . Nesse caso, precisamos emitir comandos explicitamente para aumentar o arquivo de dados ou adicionar outros arquivos.
Adicionando arquivos de dados
A Listagem 7 mostra o código que usamos para adicionar um novo arquivo de dados ao banco de dados. Observe que devemos especificar novamente o nome do arquivo lógico e o nome do arquivo físico que inclui um caminho completo.
Além disso, podemos colocar o arquivo físico em um volume diferente. Para isso, só precisamos mudar o caminho.
-- Listing 7: Add Data Files to the Primary Filegroup
USE [master]
GO
ALTER DATABASE [MyDB] ADD FILE ( NAME = N'MyDB01', FILENAME = N'C:\MSSQL\Data\MyDB01.ndf' , SIZE = 1048576KB , FILEGROWTH = 524288KB ) TO FILEGROUP [PRIMARY]
GO
A extensão e a adição de arquivos de dados também se aplicam ao cenário em que optamos por desabilitar o crescimento automático para nossos bancos de dados (consulte a Figura 4).
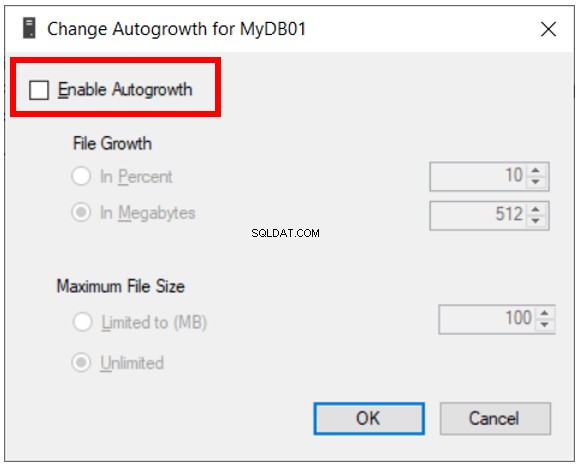
Em seguida, precisamos estender o banco de dados manualmente usando os códigos acima das Listas 5 ou 6, ou adicionar arquivos como na Listagem 7.
Usando grupos de arquivos
Os grupos de arquivos nos permitem gerenciar as coleções de arquivos de dados juntos. Podemos agrupar logicamente alguns arquivos de dados armazenados em discos ou volumes diferentes em um grupo de arquivos. Esse grupo de arquivos cria uma camada de abstração entre as tabelas e índices e os arquivos físicos reais que armazenam os dados.
Portanto, se criarmos uma tabela em um grupo de arquivos, os dados dessa tabela serão distribuídos por todos os arquivos de dados atribuídos ao grupo de arquivos.
Até este ponto, lidamos apenas com o grupo de arquivos PRIMARY. A Listagem 8 mostra como podemos adicionar um novo arquivo MyDB02 para um grupo de arquivos, diferente do grupo de arquivos primário.
A primeira instrução após definir o contexto do banco de dados como mestre cria o novo grupo de arquivos FG01. A próxima instrução adiciona o arquivo a esse novo grupo de arquivos com opções semelhantes às usadas na Listagem 7.
-- Listing 8: Add Data Files to the Primary Filegroup
USE [master]
GO
ALTER DATABASE [MyDB] ADD FILEGROUP [FG01]
GO
ALTER DATABASE [MyDB] ADD FILE ( NAME = N'MyDB02', FILENAME = N'C:\MSSQL\Data\MyDB02.ndf' , SIZE = 102400KB , MAXSIZE = 2097152KB , FILEGROWTH = 524288KB ) TO FILEGROUP [FG01]
GO
Descartando arquivos de dados
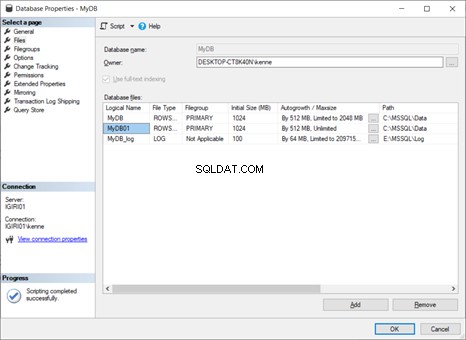
A Figura 5 mostra o resultado das operações que realizamos até agora. Temos três arquivos de dados. Dois deles estão no grupo de arquivos PRIMARY e o terceiro está no grupo de arquivos FG01.
Vamos supor que fizemos algo errado, por exemplo, definir o tamanho de arquivo errado. Em seguida, podemos descartar o grupo de arquivos usando o seguinte código na Listagem 9:
-- Listing 9: Drop Data Files
USE [MyDB]
GO
ALTER DATABASE [MyDB] REMOVE FILE [MyDB02]
GO
Conclusão
Este artigo explorou os tipos de arquivos de banco de dados, as possíveis complicações causadas pelo crescimento dos arquivos de dados e as formas de resolver o problema. Além disso, examinamos os códigos T-SQL para estender arquivos de dados e adicionar novos arquivos de dados a um banco de dados. Também abordamos o uso de grupos de arquivos.
Nosso objetivo é garantir que, quando implantamos bancos de dados, preparamos o banco de dados para armazenar todos os dados necessários para um determinado aplicativo.
Referências
- Arquivos de banco de dados e grupos de arquivos