Este artigo trata dos fundamentos da Pesquisa Semântica, incluindo um passo a passo completo da Pesquisa Semântica:começando do zero e terminando com um recurso pronto para uso.
Além disso, os leitores aprenderão sobre alguns dos recursos de pesquisa muito úteis, mas geralmente não conhecidos, disponíveis no SQL Server, como a pesquisa semântica, que demonstraremos com alguns exemplos básicos.
Este artigo também enfatiza a importância da Busca Semântica para uma forma específica de análise que não pode ser realizada com uma busca comum.
O que é pesquisa semântica
Vamos primeiro descobrir o que exatamente é a Pesquisa Semântica e como ela é diferente da Pesquisa de Texto Completo.
Definição da Microsoft
De acordo com a documentação da Microsoft, a Pesquisa Semântica fornece informações detalhadas sobre documentos não estruturados.
Definição alternativa
A Pesquisa Semântica é uma tecnologia ou recurso de pesquisa especial usado para realizar uma pesquisa abrangente ou uma análise comparativa principalmente em dados ou documentos não estruturados, como documentos do MS Word, desde que os dados não estruturados sejam armazenados no banco de dados SQL Server.
Compatibilidade
A Pesquisa Semântica é compatível apenas com o SQL Server 2012 e versões posteriores.
Lembre-se de que a Pesquisa Semântica não é compatível com o banco de dados SQL do Azure ou com as soluções de nuvem do data warehouse do Azure.
Isso significa que você precisa trabalhar com uma VM no Azure ou em uma instância do SQL Server local para utilizar esse recurso poderoso.
Pesquisa semântica x Pesquisa de texto completo
De acordo com a documentação da Microsoft, a pesquisa de texto completo permite consultar as palavras em um documento; a pesquisa semântica permite consultar o significado do documento.
A pesquisa semântica junto com a pesquisa de texto completo representa um recurso conjunto oferecido pelo Microsoft SQL Server, e você pode optar por instalá-los durante a instalação de sua instância do SQL Server ou posteriormente, adicionando novos recursos à sua instância SQL existente.
Pré-requisitos
Vejamos os pré-requisitos para o uso geral da Pesquisa Semântica, juntamente com algumas das coisas necessárias para seguir as orientações neste artigo.
Pesquisa de texto completo instalada
É obrigatório saber como configurar a pesquisa de texto completo, pois a pesquisa de texto completo e a pesquisa semântica são oferecidas como um recurso conjunto.
Consulte o artigo Implementando a pesquisa de texto completo no SQL Server 2016 para iniciantes configurarem a pesquisa de texto completo, que é um pré-requisito para instalar a pesquisa semântica no SQL Server.
Este artigo espera que você tenha instalado a pesquisa de texto completo em sua instância do SQL Server.
dbForge Studio para SQL Server
O uso da Pesquisa Semântica (no passo a passo deste artigo) requer que dados não estruturados sejam armazenados no banco de dados SQL Server e, neste artigo, fizemos isso usando o dbForge Studio para SQL Server em vez de salvar dados não estruturados diretamente no SQL Server.
SQL Server 2016
Estamos usando o SQL Server 2016 neste artigo, mas as etapas devem ser quase as mesmas para qualquer outra versão compatível.
Configurar a pesquisa semântica
Para usar a Pesquisa Semântica ou Pesquisa Semântica Estatística, você pode instalá-lo durante a instalação da Pesquisa de Texto Completo ou posteriormente, adicionando Pesquisa de Texto Completo e Pesquisa Semântica como um novo recurso.
Verificação de pesquisa de texto completo
Verifique o status de instalação da pesquisa de texto completo e da pesquisa semântica executando o seguinte script no banco de dados mestre:
-- Full-Text Search and Semantic Search status
SELECT SERVERPROPERTY('IsFullTextInstalled') as [Full-Text-Search-and-Semantic-Search-Installed];
GO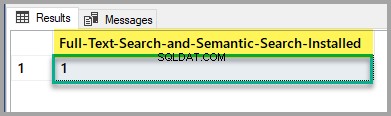
Se a saída for 1, você estará pronto, mas se for 0, consulte o artigo mencionado acima para instalar o recurso de pesquisa de texto completo e pesquisa semântica usando a configuração do SQL Server.
Instalar o banco de dados de estatísticas de linguagem semântica
Instale o Banco de Dados de Estatísticas de Linguagem Semântica pesquisando Microsoft® SQL Server® 2016 Estatísticas de Linguagem Semântica na internet ou clicando no link a seguir.
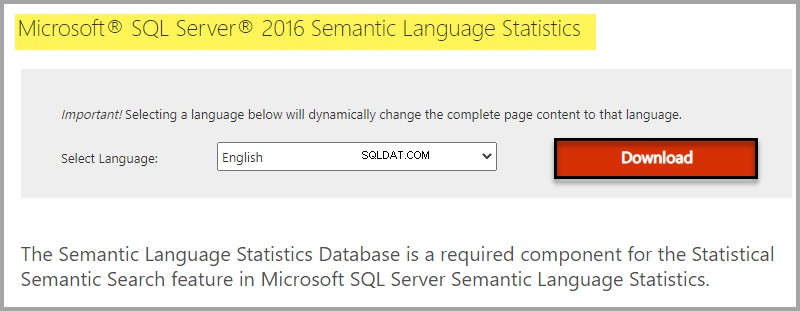
Selecionando o download com base na sua edição do Windows:
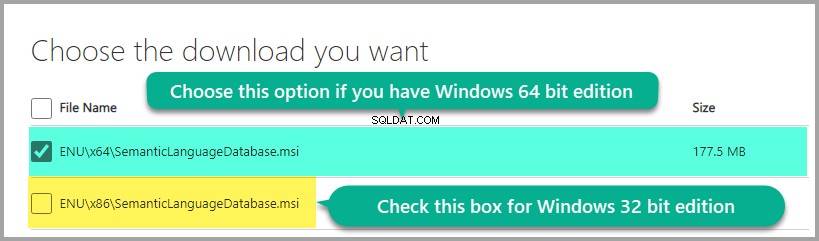
Instale o banco de dados de idiomas:
Clique em Avançar para continuar se estiver de acordo com os termos do contrato de licença:
Deixe as opções padrão como estão, mas é recomendável verificar o custo do disco conforme mostrado abaixo:
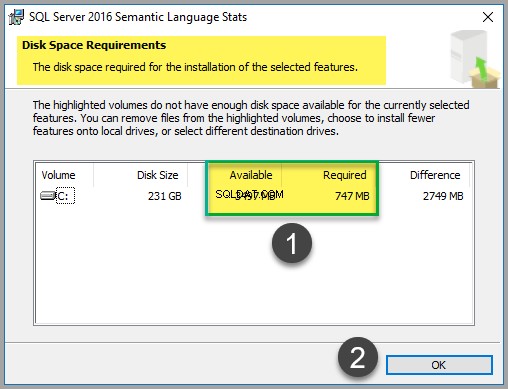
Embora o arquivo ocupe apenas cerca de 747 MB de espaço (no momento da redação deste artigo), verifique o custo do disco para garantir que você tenha espaço suficiente disponível:
Depois de concluir a verificação do custo do disco, clique em OK e clique em Avançar .
Você será solicitado a instalar o arquivo, clique em Instalar (se estiver interessado em fazê-lo):
Clique em Concluir uma vez que a instalação é feita com sucesso, que deve se parecer com a captura de tela abaixo:
Localize a pasta onde o Semantic Language Database foi instalado por padrão (C:\Program Files\Microsoft Semantic Language Database):
Tudo parece bem, então copie o arquivo Data and Log para a pasta Data da sua instância SQL, conforme mostrado abaixo:
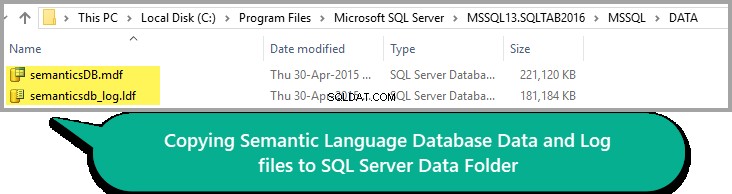
Lembre-se de que o caminho da pasta DATA pode variar de acordo com a versão do SQL Server.
Anexar banco de dados de linguagem semântica à instância SQL
Clique com o botão direito do mouse em Bancos de dados nó em Object Explorer no SSMS (SQL Server Management Studio) e clique em Anexar :
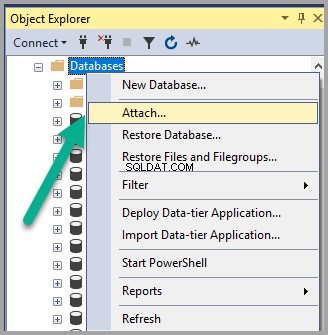
Adicionar Semanticsdb.mdf e clique em OK :
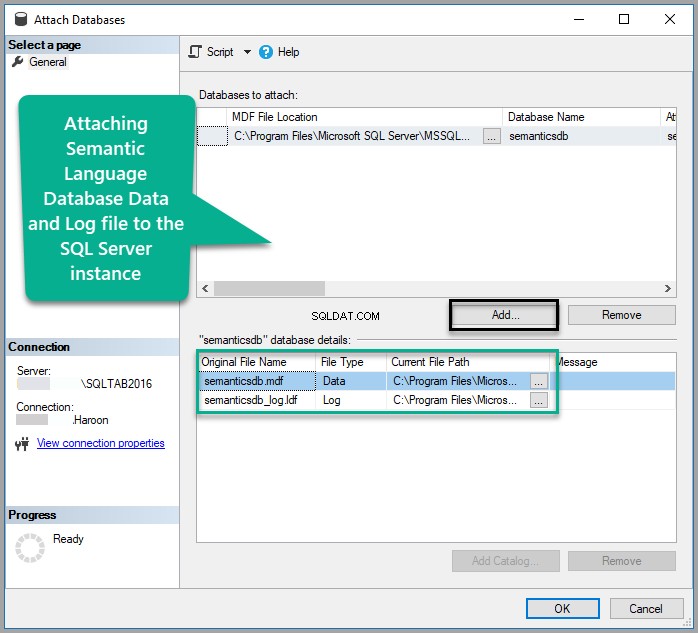
Veja o banco de dados:
Registrar Banco de Dados Semântico
Digite o seguinte script no banco de dados mestre para registrar o Banco de Dados de Estatísticas de Linguagem Semântica:
-- Register Semantic Language Statistics Database
EXEC sp_fulltext_semantic_register_language_statistics_db @dbname = N'semanticsdb';
GOVerifique o status do banco de dados semântico
Verifique o status do banco de dados de estatísticas de linguagem semântica executando o seguinte script no banco de dados mestre:
-- Check Semantic Language Statistics Database status
SELECT * FROM sys.fulltext_semantic_language_statistics_database;
GOA saída não deve estar vazia e seria a seguinte:

Lembre-se de que os valores acima podem diferir em sua máquina, o que é normal desde que você veja uma linha, isso significa que o banco de dados de estatísticas de linguagem semântica foi instalado com sucesso em sua instância SQL.
Usando a pesquisa semântica
Depois que a Pesquisa Semântica estiver configurada, estamos prontos para usá-la no SQL Server.
Cenário de pesquisa semântica
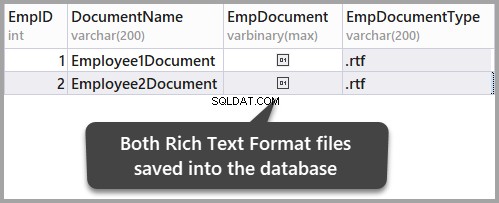
Vamos armazenar os documentos dos funcionários (amostras) em formato rich text no banco de dados SQL Server para serem pesquisados e comparados posteriormente usando a Pesquisa Semântica.
Configurar um banco de dados de exemplos de funcionários
Crie um banco de dados de exemplo com uma única tabela executando o script T-SQL no banco de dados mestre da seguinte maneira:
-- (1) Setup sample database
Create DATABASE EmployeesSample;
GO
USE EmployeesSample
-- (2) Create EmployeesForSemanticSearch table
CREATE TABLE [dbo].[EmployeesForSemanticSearch](
[EmpID] [int] NOT NULL,
[DocumentName] [varchar](200) NULL,
[EmpDocument] [varbinary](max) NULL,
[EmpDocumentType] [varchar](200) NULL,
CONSTRAINT [PK_EmployeesForSemanticSearch_EmpID] PRIMARY KEY CLUSTERED
(
[EmpID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY]
GOVerifique o banco de dados de amostra
Execute o script a seguir apenas para verificar a tabela de banco de dados de exemplo:
-- View all the employees
SELECT efss.EmpID
,efss.DocumentName
,efss.EmpDocument
,efss.EmpDocumentType FROM dbo.EmployeesForSemanticSearch efssA saída é a seguinte:
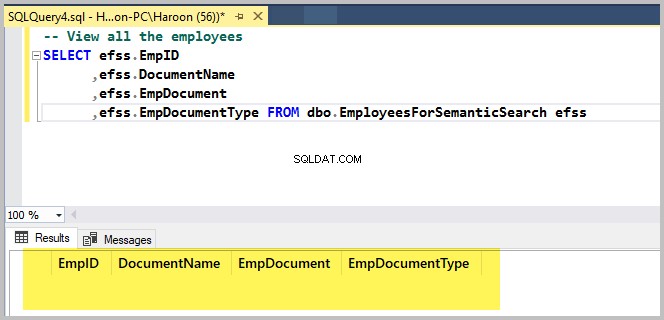
Adicione o primeiro arquivo Rich Text usando o dbForge Studio para SQL Server
Vamos adicionar dados binários às tabelas, que são representados por arquivos rich text, usando o dbForge Studio for SQL Server .
Abra o banco de dados de amostra EmployeesSample no dbForge Studio para SQL Server.
Clique com o botão direito do mouse em EmployeesForSemanticSearch tabela e clique em Recuperar dados:
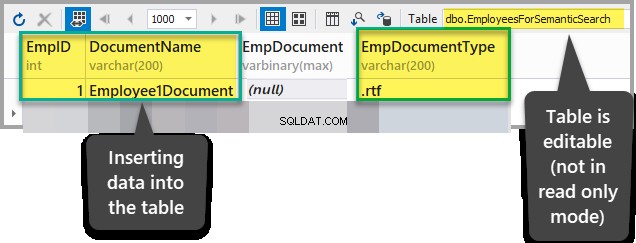
Adicione os seguintes dados ao EmployeesForSemanticSearch tabela, exceto para o EmpDocument coluna depois de garantir que a tabela não esteja no modo somente leitura:
EmpID:1
DocumentName:Employee1Document
EmpDocument:(null)
EmpDocumentType:.rtf
Insira um documento em formato rich text no EmpDocument coluna adicionando o seguinte texto na tabela (clicando nas reticências e adicionando os dados):
This is a research based article and it is a new research which is in process but this is superb in the field of research.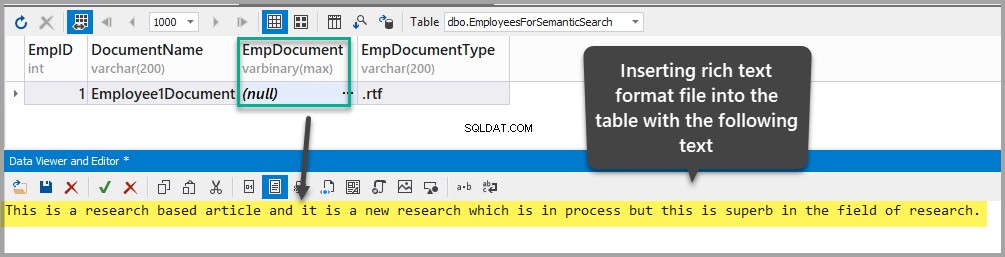
Salve o documento como Employee1Document.rtf em qualquer pasta do Windows adequada:
Aplique as alterações para ver se você armazenou com sucesso um arquivo de rich text na tabela:
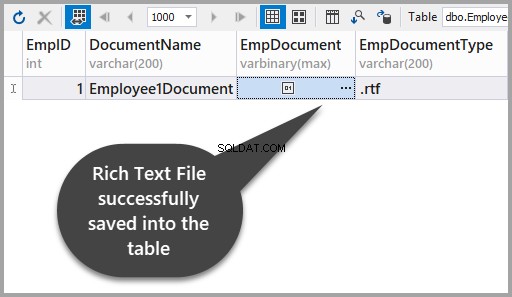
Adicione o segundo arquivo Rich Text usando o dbForge Studio para SQL Server
Em seguida, adicione outro arquivo rich text ao EmployeesForSemanticSearch tabela da mesma forma que acima usando as seguintes informações:
EmpID:2
DocumentName:Employee2Document
EmpDocument:(null)
EmpDocumentType:.rtf
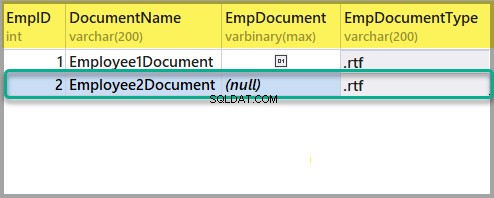
Adicione outro arquivo Rich Text com o seguinte texto:
This is an article which is about facts and figures with little research in it it talks about fact and figures just facts and figures.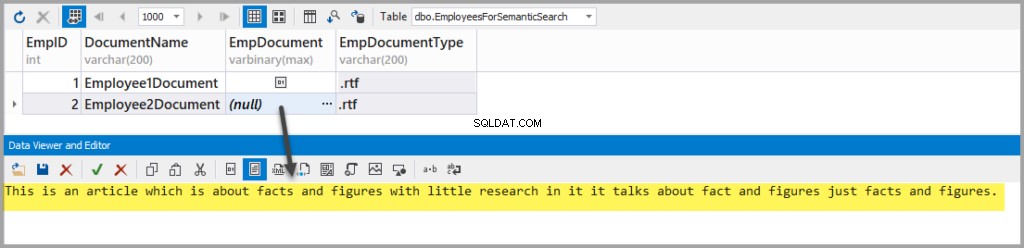
Salve o documento na mesma pasta da seguinte forma:
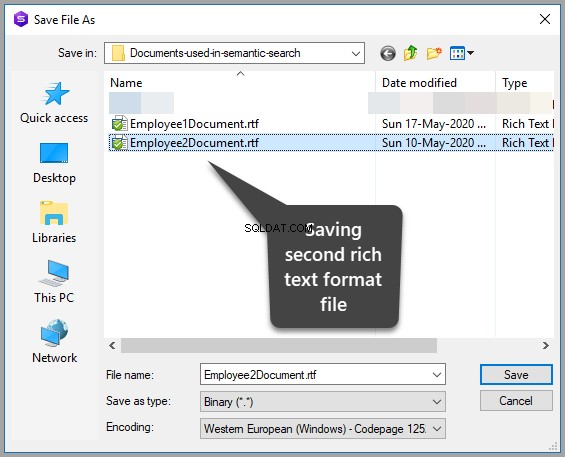
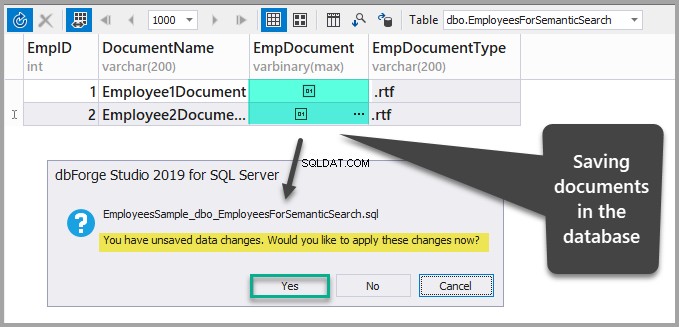
Salve os dados atualizando a tabela e confirmando as alterações que acabou de fazer clicando em sim:
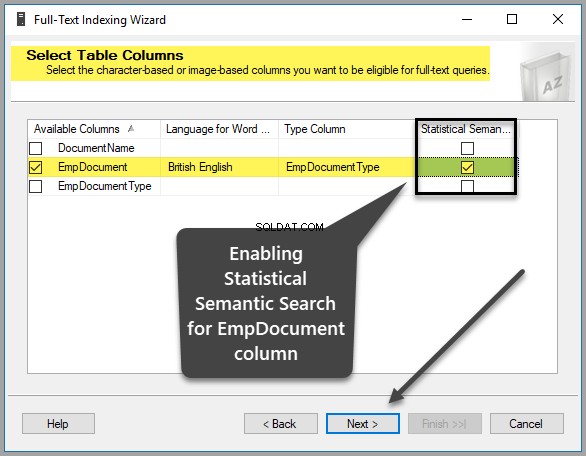
Crie um índice exclusivo, um índice de texto completo e um índice semântico usando o Assistente
De volta ao SSMS (SQL Server Management Studio), clique com o botão direito do mouse na tabela e clique em Índice de texto completo e clique em Definir índice de texto completo… como mostrado abaixo:
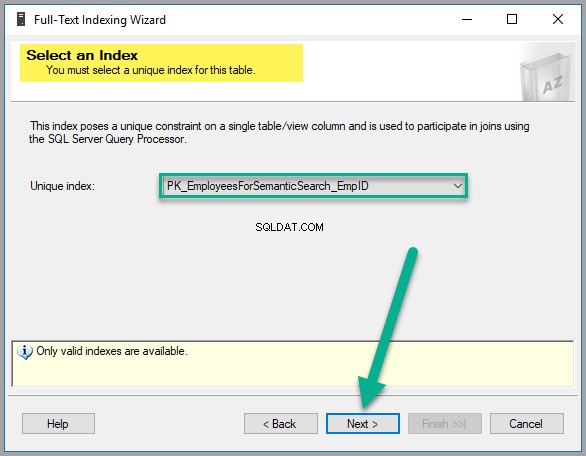
Em seguida, você deve selecionar um índice exclusivo, que na verdade é selecionado por padrão, pois criamos EmpID coluna de chave primária anterior, conforme mostrado abaixo, portanto, clique em Avançar continuar:
Selecione EmpDocument de Colunas Disponíveis , inglês britânico como Linguagem para Word Breaker , EmpDocumentType como Coluna Tipo e verifique a Pesquisa semântica estatística caixa na mesma linha da seguinte forma:
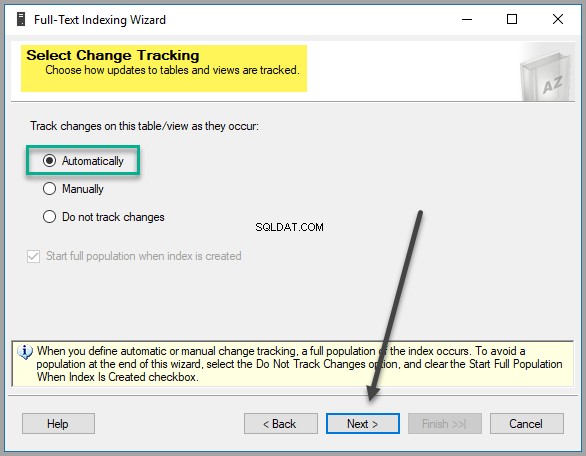
Selecione a opção de controle de alterações deixando-a com as configurações padrão, a menos que você tenha um motivo sólido para alterar essas configurações:
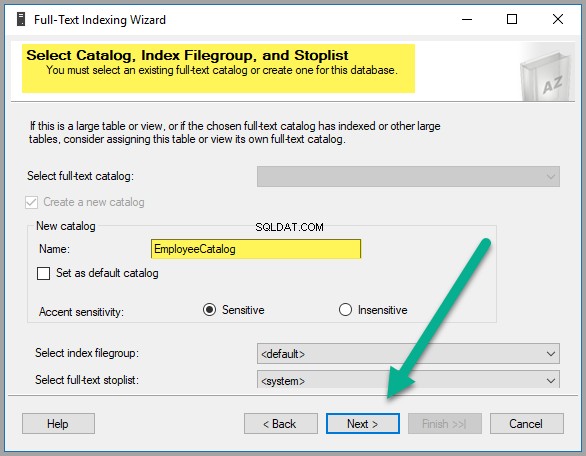
Crie um novo Catálogo como EmployeeCatalog :
Clique em Avançar novamente:
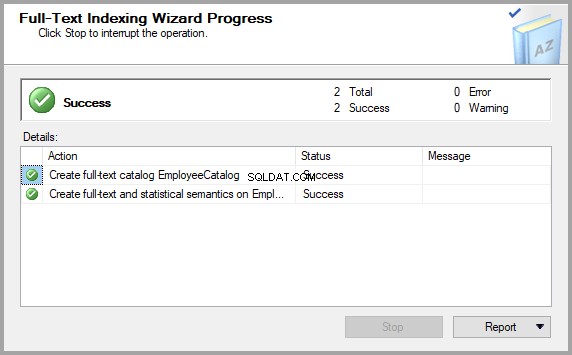
Por fim, depois de mais alguns cliques (clique em Avançar ), a tabela necessária está pronta para ser consultada pela Pesquisa Semântica:
Verifique se a pesquisa semântica está habilitada para uma tabela
Verifique se a pesquisa semântica permanece intacta para a tabela de interesse executando o seguinte script no banco de dados de amostra:
-- Check if Semantic Search is enabled for a database, table, and column
SELECT * FROM sys.fulltext_index_columns WHERE object_id = OBJECT_ID('EmployeesForSemanticSearch')
GOA saída deve indicar que foi habilitada para a terceira coluna conforme a configuramos no início do passo a passo:
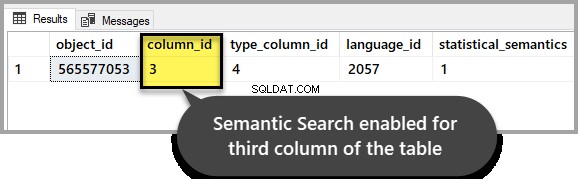
Exemplo 1:como usar a pontuação de pesquisa semântica para encontrar um documento relevante
Agora podemos usar a Pesquisa Semântica para comparar dois documentos para encontrar uma palavra-chave de interesse e sua pontuação relativa, o que ajuda a nos apontar para documentos mais relevantes.
Se estivermos interessados em ver o documento onde a palavra “pesquisa ” é mencionado com mais frequência em comparação com o outro documento, então temos que ficar de olho na pontuação de cada um dos documentos quando executamos o seguinte script T-SQL:
-- Using Semantic Search to find the score for the word research in both documents
SELECT TOP (100) DOC_TBL.EmpID, DOC_TBL.EmpDocumentType,KEYP_TBL.keyphrase,
KEYP_TBL.score
FROM
EmployeesForSemanticSearch AS DOC_TBL
INNER JOIN SEMANTICKEYPHRASETABLE
(
EmployeesForSemanticSearch,
EmpDocument
) AS KEYP_TBL
ON DOC_TBL.EmpID = KEYP_TBL.document_key
WHERE KEYP_TBL.keyphrase = 'research'
ORDER BY KEYP_TBL.Score DESC;O resultado da consulta acima é o seguinte:
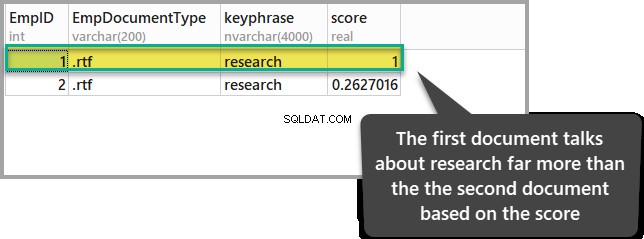
O documento com maior pontuação mostra que tem mais relevância em relação ao outro documento no que diz respeito ao nosso ponto de interesse (pesquisa).
Exemplo 2:como usar a pontuação de pesquisa semântica para encontrar um documento relevante
Também podemos encontrar o documento onde a palavra “fato” domina quando comparado com qualquer outro documento executando o script abaixo:
-- Using Semantic Search to find the score for the word fact in both documents
SELECT TOP (100) DOC_TBL.EmpID, DOC_TBL.EmpDocumentType,KEYP_TBL.keyphrase,
KEYP_TBL.score
FROM
EmployeesForSemanticSearch AS DOC_TBL
INNER JOIN SEMANTICKEYPHRASETABLE
(
EmployeesForSemanticSearch,
EmpDocument
) AS KEYP_TBL
ON DOC_TBL.EmpID = KEYP_TBL.document_key
WHERE KEYP_TBL.keyphrase = 'fact'
ORDER BY KEYP_TBL.Score DESC;Os resultados são os seguintes:
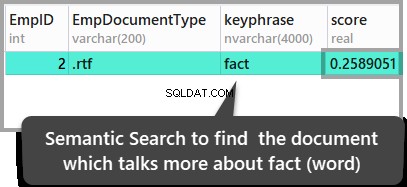
Os resultados acima levam à conclusão de que o segundo documento armazenado é o único documento onde a palavra fato é mencionado, mas se você quiser verificar esses resultados, abra os documentos armazenados para dar uma olhada neles.
Parabéns! Você aprendeu com sucesso não apenas a configurar a pesquisa semântica no SQL Server, mas também ganhou alguma experiência prática no uso da pesquisa semântica.
Coisas para fazer
Agora que você pode configurar e escrever algumas consultas básicas de pesquisa semântica, tente o seguinte para melhorar ainda mais suas habilidades:
- Tente adicionar outro documento que fale sobre pesquisa e, em seguida, execute o script no primeiro exemplo para ver qual documento é o documento mais relevante comparando suas pontuações.
- Tendo em mente este artigo, adicione outro documento onde a palavra fato é mencionado algumas vezes e, em seguida, execute o T-SQL no exemplo 2 deste artigo para ver se os resultados permanecem os mesmos ou mudam.
- Tente usar a Pesquisa semântica adicionando mais documentos e mais texto a documentos novos e existentes e, em seguida, encontre os documentos que correspondem às suas palavras de interesse.
- Explore os exemplos mais adiante para descobrir por conta própria se a Pesquisa semântica diferencia maiúsculas de minúsculas (Dica:você pode modificar ligeiramente os exemplos).