Os logs de transações são um componente vital e importante da arquitetura do banco de dados. Neste artigo, discutiremos os logs de transações do SQL Server, a importância e sua função na migração do banco de dados.
Introdução
Vamos falar sobre diferentes opções para fazer backups do SQL Server. O SQL Server oferece suporte a três tipos diferentes de Backups.
1. Completo
2. Diferencial
3. Log de transações
Antes de entrar nos conceitos de log de transações, vamos discutir outros tipos básicos de backup no SQL Server.
Um backup completo é uma cópia de tudo. Como o nome indica, ele fará backup de tudo. Ele fará backup de todos os dados, todos os objetos do banco de dados, como um arquivo, grupo de arquivos, tabela, etc:– Um backup completo é a base para qualquer outro tipo de backup.
Um backup diferencial fará backup dos dados que foram alterados desde o último backup completo.
A terceira opção é um Backup de log de transações, que registrará todas as instruções que emitimos para o banco de dados no log de transações. O log de transações é um mecanismo conhecido como “WAL” (Write-Ahead-Logging). Ele grava todas as informações no log de transações primeiro e depois no banco de dados. Em outras palavras, o processo normalmente não atualiza o banco de dados diretamente. Esta é a única opção completa disponível com o modelo de recuperação completa do banco de dados. Em outros modelos de recuperação, os dados são parciais ou não há dados suficientes no log. Por exemplo, o registro de log ao gravar o início de uma nova transação (o registro de log LOP_BEGIN_XACT) conterá a hora em que a transação foi iniciada e os registros de log LOP_COMMIT_XACT (ou LOP_ABORT_XACT) registrarão a hora em que a transação foi confirmada (ou abortada).
Para localizar internos do log de transações online, você pode consultar a função sys.fn_dblog.
A função do sistema sys.fn_dblog aceita dois parâmetros, primeiro, LSN inicial e LSN final da transação. Por padrão, é definido como NULL. Se estiver definido como NULL, retornará todos os registros de log do arquivo de log de transações.
USE WideWorldImporters GO SELECT [Current LSN], [Operation], [Transaction Name], [Transaction ID], [Log Record Fixed Length], [Log Record Length] [Transaction SID], [SPID], [Begin Time], * FROM fn_dblog(null,null)

Como todos sabemos, as transações são armazenadas em formato binário e não em formato legível. Para ler o arquivo de log de transações offline, você pode usar fn_dump_dblog.
Vamos consultar o arquivo de log de transações para ver quem descartou o objeto usando o fn_dump_dblog.
SELECT [Current LSN], [Operation], [Transaction Name], [Transaction ID], SUSER_SNAME ([Transaction SID]) AS DBUser
FROM fn_dump_dblog (
NULL, NULL, N'DISK', 1, N'G:\BKP\AdventureWorks_2016_log.trn',
DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT,
DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT,
DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT,
DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT,
DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT,
DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT,
DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT,
DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT,
DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT)
WHERE
Context IN ('LCX_NULL') AND Operation IN ('LOP_BEGIN_XACT')
AND [Transaction Name] LIKE '%DROP%' 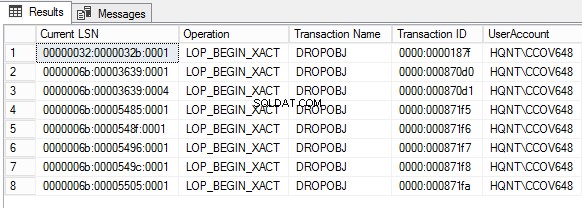
Usaremos a função fn_dblog() para ler a parte ativa do log de transações para encontrar a atividade que é executada nos dados. Depois que o log de transações for limpo, você precisará consultar os dados de um arquivo de log usando fn_dump_dblog().
Essa função fornece o mesmo conjunto de linhas que fn_dblog(), mas possui algumas funcionalidades interessantes que a tornam útil em alguns cenários de solução de problemas e recuperação. Especificamente, ele pode ler não apenas o log de transações do banco de dados atual, mas também backups de logs de transações em disco ou fita.
Para obter a lista dos objetos que são descartados usando o arquivo de transação, execute a consulta a seguir. Inicialmente, os dados são despejados na tabela temporária. Em alguns casos, a execução de fun_dump_dblog() demora um pouco mais para ser executada. Portanto, é melhor capturar os dados na tabela temporária.
Para obter um ID de objeto da coluna Lock Information, execute a seguinte consulta.
SELECT * INTO TEMP FROM fn_dump_dblog ( NULL, NULL, N'DISK', 1, N'G:\BKP\AdventureWorks_2016_log.trn', DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT) WHERE [Transaction ID] in( SELECT DISTINCT [Transaction ID] FROM fn_dump_dblog ( NULL, NULL, N'DISK', 1, N'G:\BKP\AdventureWorks_2016_log.trn', DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT) WHERE [Transaction Name] LIKE '%DROP%') and [Lock Information] like '%ACQUIRE_LOCK_SCH_M OBJECT%'
Para obter um ID de objeto da coluna Lock Information, execute a seguinte consulta.
SELECT DISTINCT [Lock Information],PATINDEX('%: 0%', [Lock Information])+4,(PATINDEX('%:0%', [Lock Information])-PATINDEX('%: 0%', [Lock Information]))-4,
Substring([Lock Information],PATINDEX('%: 0%', [Lock Information])+4,(PATINDEX('%:0%', [Lock Information])-PATINDEX('%: 0%', [Lock Information]))-4) objectid
from temp 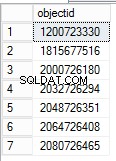
O object_id pode ser encontrado manipulando o valor da coluna Lock Information. Para encontrar o nome do objeto para o ID do objeto correspondente, restaure o banco de dados do backup logo antes de a tabela ser descartada. Após a restauração, você pode consultar a visualização do sistema para obter o nome do objeto.
USE AdventureWorks2016; GO SELECT name, object_id from sys.objects WHERE object_id = '1815677516';
Agora, vamos ver as diferentes formas dos mesmos detalhes de transação usando sys.dn_dblog, sys.fn_full_dblog. A função do sistema fn_full_dblog funciona apenas com o SQL Server 2017.
Consulta para buscar as 10 principais transações usando fn_dblog.
SELECT TOP 10 * FROM sys.fn_dblog(null,null)

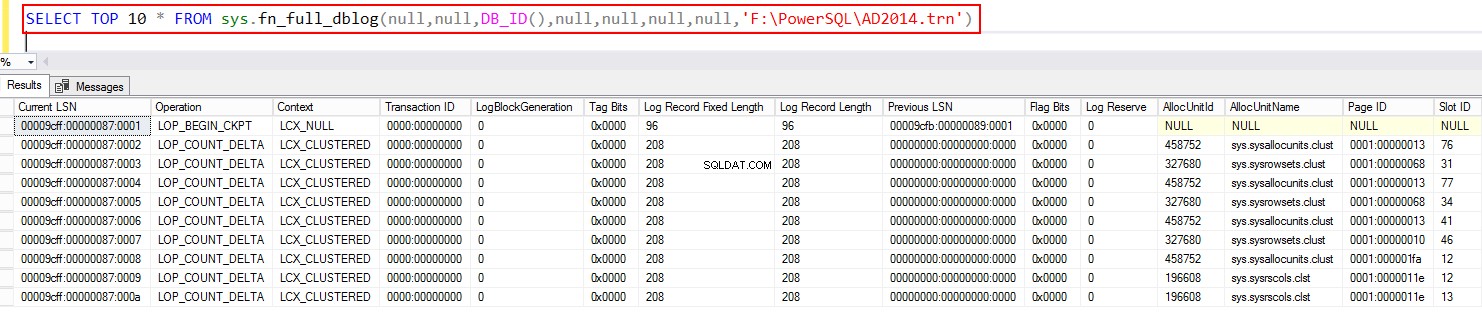
Do SQL Server 2017 em diante, você pode usar o fn_full dblog.
SELECT TOP 10 * FROM sys.fn_full_dblog(null,null,DB_ID(),null,null,null,null,NULL)

Você pode se aprofundar na função do sistema usando o sp_helptext fn_full_dblog.
Em seguida, consulte o arquivo de backup usando a função do sistema usando fn_full_dblog. Novamente, isso é aplicável apenas a partir do SQL Server 2017.
Restauração pontual
Vamos supor que você tenha a lista de todo o backup de log e, quando pretender restaurar os logs, tenha a possibilidade de realizar uma restauração pontual dos dados. Portanto, no processo de restauração de log, você não precisa necessariamente restaurar todos os dados, você pode restaurá-los até, antes ou depois de qualquer transação individual. Portanto, se o banco de dados travar em um momento específico e tivermos backup completo e backups de log, poderemos primeiro restaurar o backup completo e depois restaurar o backup de log e, no processo, restaurar o último log até um determinado momento , e isso deixaria o banco de dados no estado exato em que estava antes da ocorrência desse problema.
Os backups de log são VLDB (Very Large Database) bastante comuns e os bancos de dados mais críticos. É sempre recomendável testar o processo de restauração. Sempre que você fizer backups de banco de dados, é aconselhável pensar bem no processo de restauração e sempre testar o processo de restauração com mais frequência.
É sempre bom aliviar os testes do processo de restauração de tempos em tempos, portanto, apenas certifique-se de que o processo passe pelos backups normalmente.
Cenários
Vamos falar sobre um cenário, quando você precisa restaurar um banco de dados muito grande e todos sabemos que normalmente pode levar várias horas, e isso é algo que todos devem estar cientes. Se você está planejando uma migração de banco de dados sem perda de dados e janelas de interrupção menores, isso ainda pode ser um grande problema. Portanto, certifique-se de confiar no backup do log de transações para acelerar o processo.
Vamos considerar outro cenário em que você está realizando uma migração de banco de dados lado a lado entre duas versões diferentes do SQL Server; você está envolvido na migração do banco de dados para a mesma versão do software no destino e isso inclui a transferência do sistema operacional, banco de dados, aplicativo e rede etc:-; migrar o banco de dados de um hardware para outro; alterando tanto o software quanto o hardware. O processo de migração de banco de dados é sempre o desafio onde a perda de dados é sempre possível e está sujeita ao ambiente.
Práticas recomendadas de migração de banco de dados
Vamos discutir as práticas padrão de gerenciamento de migração de banco de dados.
A migração deve ser feita de forma transacional para evitar inconsistências nos dados. As etapas usuais do processo de migração são convencionalmente as seguintes:
- Parar o serviço do aplicativo — é aqui que começa o tempo de inatividade
- Inicie o backup de log, depende de seus requisitos
- Coloque o banco de dados no modo de recuperação para que não sejam feitas mais alterações no banco de dados
- Mover o(s) arquivo(s) de registro
- Restaurar o(s) arquivo(s) de log de transações do banco de dados — desde que você já tenha restaurado o backup completo do banco de dados no destino e deixe o banco de dados no estado de restauração.
- Clone os logins e corrija os usuários órfãos
- Criar vagas
- Instale o aplicativo
- Configurar rede – Alterar entradas DNS
- Reconfigure as configurações do aplicativo
- Iniciar serviço de aplicativo
- Teste o aplicativo
Primeiros passos
Neste artigo, discutiremos como lidar com a migração de banco de dados OLTP muito grande. Discutiremos estratégias para usar técnicas de servidor SQL e ferramentas de terceiros para segurança de dados com interrupção zero ou mínima na disponibilidade do sistema de produção. Durante o processo, há sempre uma chance de perder os dados. Você acha que o manuseio contínuo das transações é uma boa estratégia? Se “sim”, quais são suas opções favoritas?
Vamos nos aprofundar nas opções disponíveis:
- Backup e restauração
- Envio de logs
- Espelhamento de banco de dados
- Ferramentas de terceiros
Backup e restauração
A técnica de backup e restauração de banco de dados é a opção mais viável para qualquer migração de banco de dados. Se for planejado e testado corretamente, evitaremos muitos erros de migração imprevistos. Todos sabemos que o backup é um processo online, é fácil iniciar o backup do log de transações em tempo hábil para diminuir o número de transações a serem fornecidas ao novo banco de dados. Durante a janela de migração, podemos limitar o acesso dos usuários ao banco de dados e iniciar um último backup de log e transferi-lo para o destino. Desta forma, o tempo de inatividade pode ser reduzido significativamente.
Envio de log
Todos nós entendemos a importância dos arquivos de log no mundo do banco de dados. A técnica de envio de logs oferece uma boa solução de recuperação de desastres e oferece suporte a acesso limitado somente leitura a bancos de dados secundários, durante o intervalo entre as tarefas de restauração. É essencialmente um conceito de backup do log de transações e é reproduzido em um backup completo em mais um banco de dados secundário. Esses bancos de dados secundários são cópias duplicadas do banco de dados primário e restauram continuamente os backups do log de transações para sua própria cópia, a fim de mantê-lo sincronizado com o banco de dados primário. Como o banco de dados secundário está em um hardware separado, em caso de falha do primário por qualquer motivo, a cópia de backup completa do sistema fica imediatamente disponível para uso e o tráfego de rede pode simplesmente ser redirecionado para o servidor secundário, sem que nenhum usuário saiba que um ocorreu uma falha. O envio de logs fornece uma maneira fácil e eficaz de gerenciar a migração em maior medida na maioria dos casos.
Espelhamento
O espelhamento de banco de dados também é uma opção para migração de banco de dados, desde que a origem e o destino sejam das mesmas versões e edições. Essencialmente, o espelhamento cria duas cópias duplicadas de um banco de dados em duas instâncias de hardware. As transações ocorreriam em ambos os bancos de dados simultaneamente. Você tem a capacidade de colocar um banco de dados de produção offline, alternando para a versão espelhada desse banco de dados e permitir que os usuários continuem acessando os dados como se nada tivesse acontecido. Em termos de implementação, lidamos com um servidor principal, um servidor espelho e uma testemunha. Mas será um recurso obsoleto e será removido de versões futuras do SQL Server.
Resumo
Neste artigo, discutimos os tipos de backups, backup de log de transações em detalhes, padrões de migração de dados, processo e estratégia, aprendidas a usar técnicas SQL para manipulação eficaz das etapas de migração de dados.
O mecanismo de gravação de log de transações WAL garante que as transações sejam sempre gravadas primeiro no arquivo de log. Dessa forma, o SQL Server garante que os efeitos de todas as transações confirmadas serão gravados nos arquivos de dados (no disco) e que quaisquer modificações de dados no disco originadas de transações incompletas serão ROLLBACK e não refletidas nos arquivos de dados.
Na maioria dos casos, o atraso na sincronização de dados é imprevisto e a perda de dados é permanente. Na maioria das vezes, tudo depende do tamanho do banco de dados e da infraestrutura disponível. Como prática recomendada, é melhor executar migrações manualmente do que como parte da implantação para manter as coisas segregadas para que a saída possa ser mais previsível.
Pessoalmente, eu preferiria o envio de log por vários motivos:você pode fazer um backup completo dos dados do servidor antigo com bastante antecedência, transferi-lo para o novo servidor, restaurá-lo e, em seguida, aplicar as transações residuais (t-log backup ) desde o ponto até o momento do cutover. O processo é realmente bastante simples.
A migração do banco de dados não é difícil se for feita da maneira correta. Espero que esta postagem ajude você a executar as migrações de banco de dados de maneira mais suave.