Na postagem anterior do blog, abordamos os conceitos básicos de dimensionamento - o que é, quais são os tipos, o que é obrigatório se quisermos dimensionar. Esta postagem do blog se concentrará nos desafios e nas maneiras pelas quais podemos expandir.
Desafio de dimensionamento
Escalar bancos de dados não é a tarefa mais fácil por vários motivos. Vamos nos concentrar um pouco nos desafios relacionados à expansão da infraestrutura de banco de dados.
Serviço com estado
Podemos distinguir dois tipos diferentes de serviços:sem estado e com estado. Serviços sem estado são aqueles que não dependem de nenhum tipo de dado existente. Você pode simplesmente ir em frente, iniciar esse serviço e ele funcionará com prazer. Você não precisa se preocupar com o estado dos dados nem com o serviço. Se estiver ativo, funcionará corretamente e você poderá distribuir facilmente o tráfego entre várias instâncias de serviço apenas adicionando mais clones ou cópias de VMs, contêineres ou similares existentes. Um exemplo de tal serviço pode ser um aplicativo da web - implantado a partir do repositório, tendo um servidor da web configurado corretamente, tal serviço apenas iniciará e funcionará corretamente.
O problema com bancos de dados é que o banco de dados é tudo menos stateless. Os dados devem ser inseridos no banco de dados, devem ser processados e persistidos. A imagem do banco de dados nada mais é do que apenas alguns pacotes instalados sobre a imagem do SO e, sem dados e configuração adequada, é inútil. Isso aumenta a complexidade do dimensionamento do banco de dados. Para serviços sem estado, basta implantá-los e configurar alguns balanceadores de carga para incluir novas instâncias na carga de trabalho. Para bancos de dados que implantam o banco de dados, a instância é apenas o ponto de partida. Mais adiante está o gerenciamento de dados - você precisa transferir os dados de sua instância de banco de dados existente para a nova. Isso pode ser uma parte significativa do problema e do tempo necessário para que as novas instâncias comecem a lidar com o tráfego. Somente após a transferência dos dados, podemos configurar os novos nós para fazer parte da topologia de replicação existente - os dados devem ser atualizados neles em tempo real, com base no tráfego que está chegando a outros nós.
Tempo necessário para aumentar
O fato de os bancos de dados serem serviços com estado é uma razão direta para o segundo desafio que enfrentamos quando queremos expandir a infraestrutura de banco de dados. Serviços sem estado - basta iniciá-los e pronto. É um processo bastante rápido. Para bancos de dados, você precisa transferir os dados. Quanto tempo vai demorar, depende de vários fatores. Qual o tamanho do conjunto de dados? Quão rápido é o armazenamento? Qual a velocidade da rede? Quais são as outras etapas necessárias para provisionar o novo nó com os novos dados? Os dados são compactados/descompactados ou criptografados/descriptografados no processo? No mundo real, pode levar de minutos a várias horas para provisionar os dados em um novo nó. Isso limita seriamente os casos em que você pode escalar seu ambiente de banco de dados. Picos de carga repentinos e temporários? Na verdade, eles podem ter desaparecido há muito tempo antes que você possa iniciar nós de banco de dados adicionais. Aumento repentino e consistente da carga? Sim, será possível lidar com isso adicionando mais nós, mas pode levar até horas para ativá-los e deixá-los assumir o tráfego dos nós de banco de dados existentes.
Carga adicional causada pelo processo de expansão
É muito importante ter em mente que o tempo necessário para aumentar a escala é apenas um lado do problema. O outro lado é a carga causada pelo processo de dimensionamento. Como mencionamos anteriormente, você precisa transferir todo o conjunto de dados para nós recém-adicionados. Isso não é algo que você possa ignorar, afinal, pode levar horas para ler os dados do disco, enviá-los pela rede e armazená-los em um novo local. Se o doador, o nó de onde você lê os dados, estiver sobrecarregado, você precisa considerar como ele se comportará se for forçado a realizar atividades de E/S pesadas adicionais? Seu cluster será capaz de assumir uma carga de trabalho adicional se já estiver sob forte pressão e se espalhar? A resposta pode não ser fácil de obter, pois a carga nos nós pode vir de diferentes formas. A carga vinculada à CPU será o melhor cenário, pois a atividade de E/S deve ser baixa e as operações de disco adicionais serão gerenciáveis. A carga vinculada à E/S, por outro lado, pode diminuir significativamente a transferência de dados, afetando seriamente a capacidade de dimensionamento do cluster.
Escala de escala
O processo de dimensionamento que mencionamos anteriormente é bastante limitado ao dimensionamento de leituras. É fundamental entender que escalar gravações é uma história completamente diferente. Você pode dimensionar as leituras simplesmente adicionando mais nós e espalhando as leituras por mais nós de back-end. As gravações não são tão fáceis de dimensionar. Para começar, você não pode escalar gravações assim. Cada nó que contém todo o conjunto de dados é, obviamente, necessário para lidar com todas as gravações realizadas em algum lugar do cluster, porque somente aplicando todas as modificações no conjunto de dados é possível manter a consistência. Portanto, quando você pensa nisso, não importa como você projeta seu cluster e qual tecnologia você usa, cada membro do cluster precisa executar cada gravação. Seja uma réplica, replicando todas as gravações de seu mestre ou nó em um cluster multimestre, como Galera ou InnoDB Cluster, executando todas as alterações no conjunto de dados realizadas em todos os outros nós do cluster, o resultado é o mesmo. As gravações não são dimensionadas simplesmente adicionando mais nós ao cluster.
Como podemos escalar o banco de dados?
Então, sabemos que tipo de desafios estamos enfrentando. Quais são as opções que temos? Como podemos escalar o banco de dados?
Ao adicionar réplicas
Em primeiro lugar, iremos dimensionar simplesmente adicionando mais nós. Claro, vai levar tempo e com certeza, não é um processo que você pode esperar que aconteça imediatamente. Claro, você não poderá escalar gravações assim. Por outro lado, o problema mais comum que você enfrentará é a carga da CPU causada por consultas SELECT e, como discutimos, as leituras podem ser simplesmente dimensionadas apenas adicionando mais nós ao cluster. Mais nós para ler significa que a carga em cada um deles será reduzida. Quando você estiver no início de sua jornada no ciclo de vida de seu aplicativo, apenas assuma que é com isso que você estará lidando. Carga da CPU, consultas não eficientes. É muito improvável que você precise expandir as gravações até muito mais longe no ciclo de vida, quando seu aplicativo já tiver amadurecido e você tiver que lidar com o número de clientes.
Por fragmentação
Adicionar nós não resolverá o problema de gravação, foi o que estabelecemos. O que você precisa fazer é fragmentar - dividir o conjunto de dados no cluster. Nesse caso, cada nó contém apenas uma parte dos dados, não tudo. Isso nos permite finalmente começar a escalar as gravações. Digamos que temos quatro nós, cada um contendo metade do conjunto de dados.
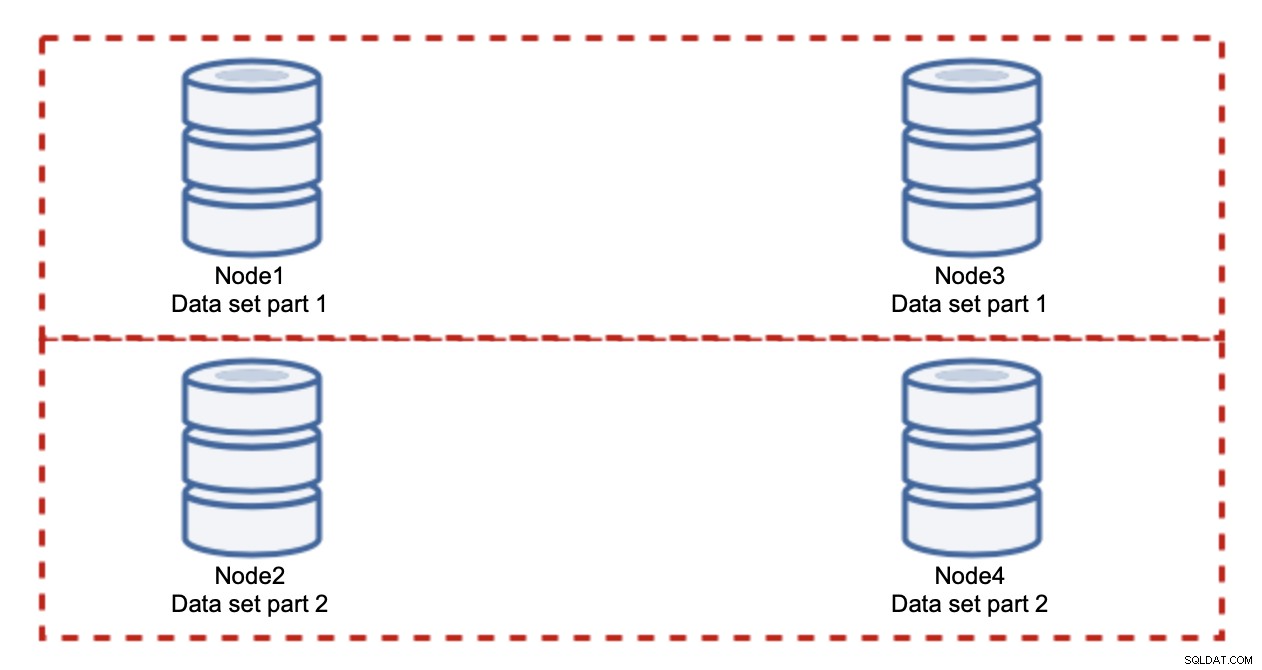
Como você pode ver, a ideia é simples. Se a gravação estiver relacionada à parte 1 do conjunto de dados, ela será executada em node1 e node3. Se estiver relacionado à parte 2 do conjunto de dados, será executado em node2 e node4. Você pode pensar nos nós do banco de dados como discos em um RAID. Aqui temos um exemplo de RAID10, dois pares de espelhos, para redundância. Na implementação real pode ser mais complexo, você pode ter mais de uma réplica dos dados para melhorar a alta disponibilidade. A essência é, assumindo uma divisão perfeitamente justa dos dados, metade das gravações atingirá node1 e node3 e a outra metade nós 2 e 4. Se você quiser dividir a carga ainda mais, você pode introduzir o terceiro par de nós:
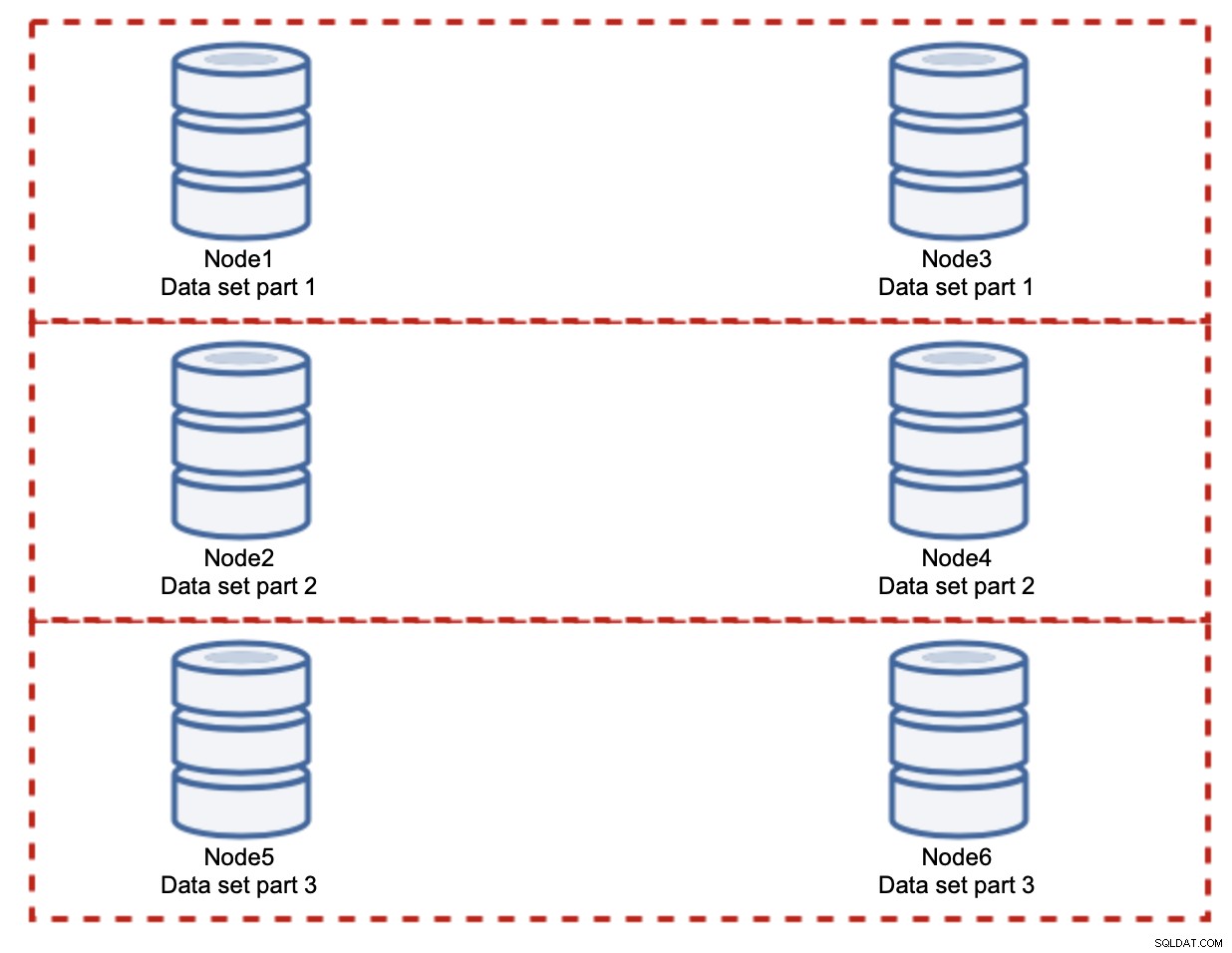
Neste caso, novamente, assumindo uma divisão perfeitamente justa, cada par ser responsável por 33% de todas as gravações no cluster.
Isso resume muito bem a ideia de fragmentação. Em nosso exemplo, adicionando mais shards, podemos reduzir a atividade de gravação nos nós do banco de dados para 33% da carga de E/S original. Como você pode imaginar, isso não vem sem inconvenientes.
Como vou descobrir em qual fragmento meus dados estão localizados? Os detalhes estão fora do escopo desta chamada, mas, em resumo, você pode implementar algum tipo de função em uma determinada coluna (módulo ou hash na coluna 'id') ou pode criar uma base de metadados separada onde armazenará os detalhes de como os dados são distribuídos.
Esperamos que você tenha achado esta curta série de blogs informativa e que tenha entendido melhor os diferentes desafios que enfrentamos quando queremos expandir o ambiente de banco de dados. Se você tiver algum comentário ou sugestão sobre este tópico, sinta-se à vontade para comentar abaixo deste post e compartilhar sua experiência