A carga de trabalho do banco de dados MySQL é determinada pelo número de consultas que ele processa. Existem várias situações nas quais a lentidão do MySQL pode se originar. A primeira possibilidade é se houver alguma consulta que não esteja usando a indexação adequada. Quando uma consulta não pode usar um índice, o servidor MySQL precisa usar mais recursos e tempo para processar essa consulta. Ao monitorar consultas, você tem a capacidade de identificar o código SQL que é a causa raiz de uma lentidão e corrigi-lo antes que o desempenho geral diminua.
Nesta postagem do blog, vamos destacar o recurso Query Outlier disponível no ClusterControl e ver como ele pode nos ajudar a melhorar o desempenho do banco de dados. Em geral, o ClusterControl executa a amostragem de consulta do MySQL de duas maneiras:
- Busque as consultas do Esquema de desempenho (recomendado ).
- Analisar o conteúdo do MySQL Slow Query.
Se o Esquema de Desempenho estiver desabilitado, o ClusterControl assumirá como padrão o log de Consulta Lenta. Para saber mais sobre como o ClusterControl faz isso, confira esta postagem no blog, Como usar o Monitor de Consulta ClusterControl para MySQL, MariaDB e Servidor Percona.
O que são valores atípicos de consulta?
Um outlier é uma consulta que leva mais tempo do que o tempo de consulta normal desse tipo. Não leve isso literalmente como consultas "mal escritas". Ele deve ser tratado como possíveis consultas comuns subótimas que podem ser melhoradas. Após um número de amostras e quando o ClusterControl tiver estatísticas suficientes, ele pode determinar se a latência é maior que o normal (2 sigmas + average_query_time), então é um outlier e será adicionado ao Query Outlier.
Esse recurso depende do recurso Principais consultas. Se o monitoramento de consultas estiver habilitado e as principais consultas forem capturadas e preenchidas, os valores atípicos de consulta os resumirão e fornecerão um filtro com base no carimbo de data/hora. Para ver a lista de consultas que requerem atenção, vá para ClusterControl -> Query Monitor -> Query Outliers e deve ver algumas consultas listadas (se houver):
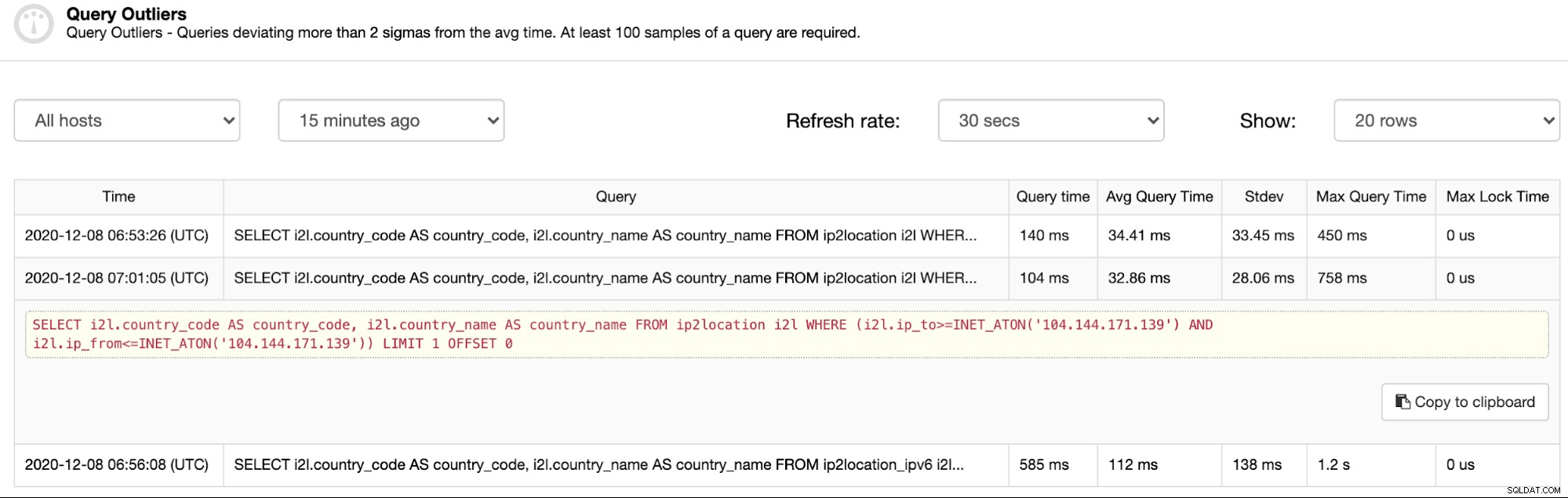
Como você pode ver na captura de tela acima, os valores discrepantes são basicamente consultas que levou pelo menos 2 vezes mais do que o tempo médio de consulta. Primeiro a primeira entrada, o tempo médio é de 34,41 ms enquanto o tempo de consulta do outlier é de 140 ms (mais de 2 vezes maior que o tempo médio). Da mesma forma, para as próximas entradas, as colunas Query Time e Avg Query Time são duas coisas importantes para justificar os pontos pendentes de uma determinada consulta atípica.
É relativamente fácil encontrar um padrão de uma consulta atípica específica observando um período de tempo maior, como uma semana atrás, conforme destacado na captura de tela a seguir:
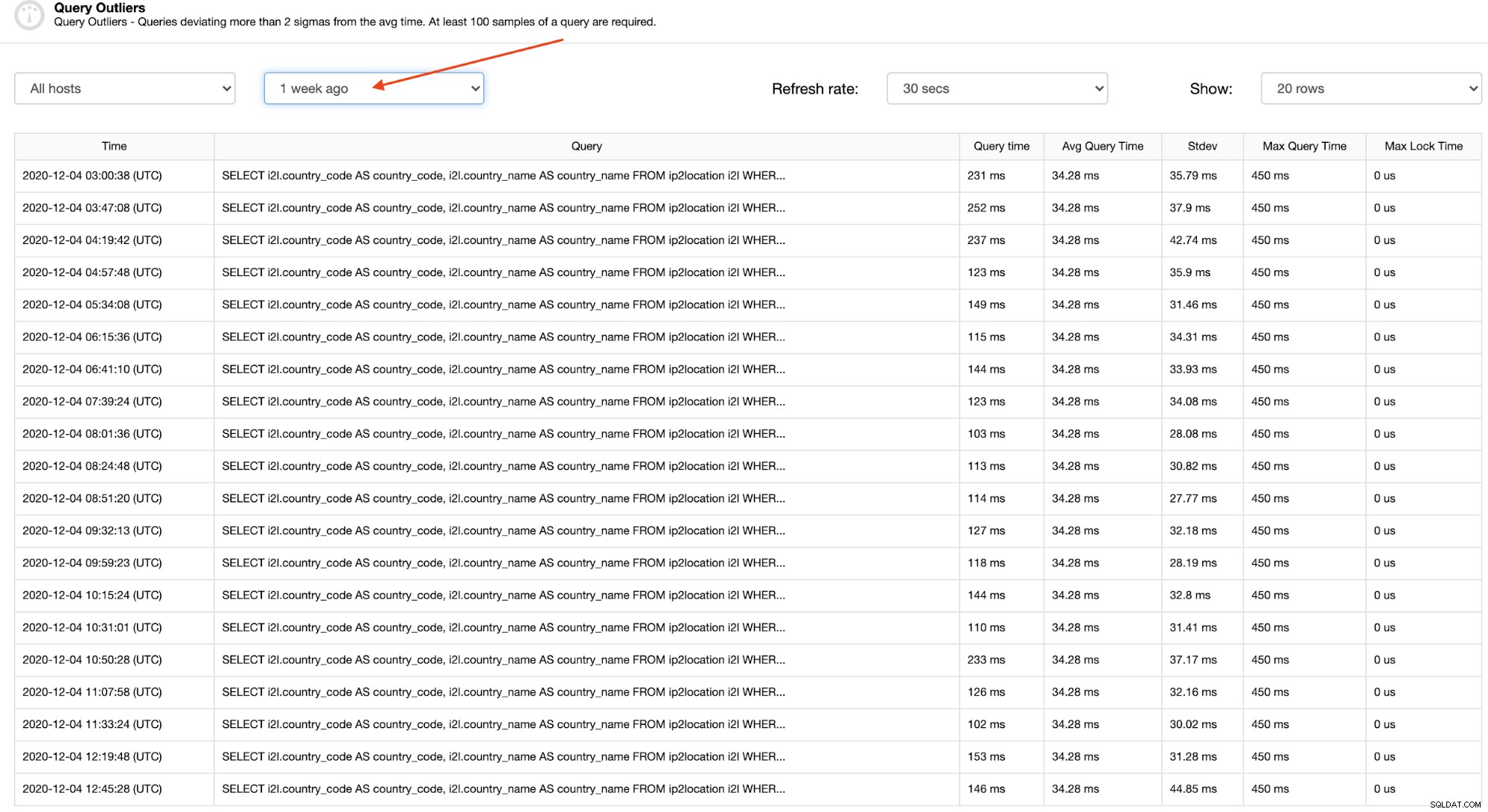
Clicando em cada linha, você pode ver a consulta completa que é realmente útil para identificar e entender o problema, conforme mostrado na próxima seção.
Corrigindo os valores atípicos de consulta
Para corrigir os outliers, precisamos entender a natureza da consulta, o mecanismo de armazenamento das tabelas, a versão do banco de dados, o tipo de cluster e o impacto da consulta. Em alguns casos, a consulta atípica não está realmente prejudicando o desempenho geral do banco de dados. Como neste exemplo, vimos que a consulta se destacou durante toda a semana e foi o único tipo de consulta capturado, portanto, provavelmente é uma boa ideia corrigir ou melhorar essa consulta, se possível.
Como no nosso caso, a consulta outlier é:
SELECT i2l.country_code AS country_code, i2l.country_name AS country_name
FROM ip2location i2l
WHERE (i2l.ip_to >= INET_ATON('104.144.171.139')
AND i2l.ip_from <= INET_ATON('104.144.171.139'))
LIMIT 1
OFFSET 0;E o resultado da consulta é:
+--------------+---------------+
| country_code | country_name |
+--------------+---------------+
| US | United States |
+--------------+---------------+Usando EXPLAIN
A consulta é uma consulta de seleção de intervalo somente leitura para determinar as informações de localização geográfica do usuário (código do país e nome do país) para um endereço IP na tabela ip2location. Usar a instrução EXPLAIN pode nos ajudar a entender o plano de execução da consulta:
mysql> EXPLAIN SELECT i2l.country_code AS country_code, i2l.country_name AS country_name
FROM ip2location i2l
WHERE (i2l.ip_to>=INET_ATON('104.144.171.139')
AND i2l.ip_from<=INET_ATON('104.144.171.139'))
LIMIT 1 OFFSET 0;
+----+-------------+-------+------------+-------+--------------------------------------+-------------+---------+------+-------+----------+------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+--------------------------------------+-------------+---------+------+-------+----------+------------------------------------+
| 1 | SIMPLE | i2l | NULL | range | idx_ip_from,idx_ip_to,idx_ip_from_to | idx_ip_from | 5 | NULL | 66043 | 50.00 | Using index condition; Using where |
+----+-------------+-------+------------+-------+--------------------------------------+-------------+---------+------+-------+----------+------------------------------------+A consulta é executada com uma varredura de intervalo na tabela usando o índice idx_ip_from com 50% de linhas em potencial (filtradas).
Mecanismo de armazenamento adequado
Observando a estrutura da tabela de ip2location:
mysql> SHOW CREATE TABLE ip2location\G
*************************** 1. row ***************************
Table: ip2location
Create Table: CREATE TABLE `ip2location` (
`ip_from` int(10) unsigned DEFAULT NULL,
`ip_to` int(10) unsigned DEFAULT NULL,
`country_code` char(2) COLLATE utf8_bin DEFAULT NULL,
`country_name` varchar(64) COLLATE utf8_bin DEFAULT NULL,
KEY `idx_ip_from` (`ip_from`),
KEY `idx_ip_to` (`ip_to`),
KEY `idx_ip_from_to` (`ip_from`,`ip_to`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_binEsta tabela é baseada no banco de dados de localização IP2 e raramente é atualizada/gravada, geralmente apenas no primeiro dia do mês (recomendado pelo fornecedor). Portanto, uma opção é converter a tabela para o mecanismo de armazenamento MyISAM (MySQL) ou Aria (MariaDB) com formato de linha fixo para obter melhor desempenho somente leitura. Observe que isso só é aplicável se você estiver executando no MySQL ou MariaDB autônomo ou replicação. No Galera Cluster and Group Replication, mantenha o mecanismo de armazenamento InnoDB (a menos que você saiba o que está fazendo).
De qualquer forma, para converter a tabela de InnoDB para MyISAM com formato de linha fixo, basta executar o seguinte comando:
ALTER TABLE ip2location ENGINE=MyISAM ROW_FORMAT=FIXED;Em nossa medição, com 1000 testes de pesquisa de endereços IP aleatórios, o desempenho da consulta melhorou cerca de 20% com MyISAM e formato de linha fixo:
- Tempo médio (InnoDB):21,467823 ms
- Tempo médio (MyISAM corrigido):17,175942 ms
- Melhoria:19.992157565301 %
Você pode esperar que esse resultado seja imediato após a alteração da tabela. Nenhuma modificação na camada superior (aplicativo/balanceador de carga) é necessária.
Ajustando a consulta
Outra maneira é inspecionar o plano de consulta e usar uma abordagem mais eficiente para um melhor plano de execução de consulta. A mesma consulta também pode ser escrita usando subconsulta como abaixo:
SELECT `country_code`, `country_name` FROM
(SELECT `country_code`, `country_name`, `ip_from`
FROM `ip2location`
WHERE ip_to >= INET_ATON('104.144.171.139')
LIMIT 1)
AS temptable
WHERE ip_from <= INET_ATON('104.144.171.139');A consulta ajustada tem o seguinte plano de execução de consulta:
mysql> EXPLAIN SELECT `country_code`,`country_name` FROM
(SELECT `country_code`, `country_name`, `ip_from`
FROM `ip2location`
WHERE ip_to >= INET_ATON('104.144.171.139')
LIMIT 1)
AS temptable
WHERE ip_from <= INET_ATON('104.144.171.139');
+----+-------------+--------------+------------+--------+---------------+-----------+---------+------+-------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------------+------------+--------+---------------+-----------+---------+------+-------+----------+-----------------------+
| 1 | PRIMARY | <derived2> | NULL | system | NULL | NULL | NULL | NULL | 1 | 100.00 | NULL |
| 2 | DERIVED | ip2location | NULL | range | idx_ip_to | idx_ip_to | 5 | NULL | 66380 | 100.00 | Using index condition |
+----+-------------+--------------+------------+--------+---------------+-----------+---------+------+-------+----------+-----------------------+Usando a subconsulta, podemos otimizar a consulta usando uma tabela derivada que se concentra em um índice. A consulta deve retornar apenas 1 registro onde o valor ip_to for maior ou igual ao valor do endereço IP. Isso permite que as linhas potenciais (filtradas) atinjam 100%, que é o mais eficiente. Em seguida, verifique se ip_from é menor ou igual ao valor do endereço IP. Se for, então devemos encontrar o registro. Caso contrário, o endereço IP não existe na tabela ip2location.
Em nossa medição, o desempenho da consulta melhorou cerca de 99% usando uma subconsulta:
- Tempo médio (InnoDB + varredura de intervalo):22,87112 ms
- Tempo médio (InnoDB + subconsulta):0,14744 ms
- Melhoria:99.355344207017 %
Com a otimização acima, podemos ver um tempo de execução de consulta inferior a milissegundos desse tipo de consulta, o que é uma grande melhoria considerando que o tempo médio anterior é de 22 ms. No entanto, precisamos fazer algumas modificações no nível superior (aplicativo/balanceador de carga) para nos beneficiar dessa consulta ajustada.
Aplicação de patches ou reescrita de consultas
Corrija seus aplicativos para usar a consulta ajustada ou reescreva a consulta atípica antes que ela chegue ao servidor de banco de dados. Podemos conseguir isso usando um balanceador de carga MySQL como ProxySQL (regras de consulta) ou MariaDB MaxScale (filtro de reescrita de instrução), ou usando o plugin MySQL Query Rewriter. No exemplo a seguir, usamos ProxySQL na frente de nosso cluster de banco de dados e podemos simplesmente criar uma regra para reescrever a consulta mais lenta na mais rápida, por exemplo:
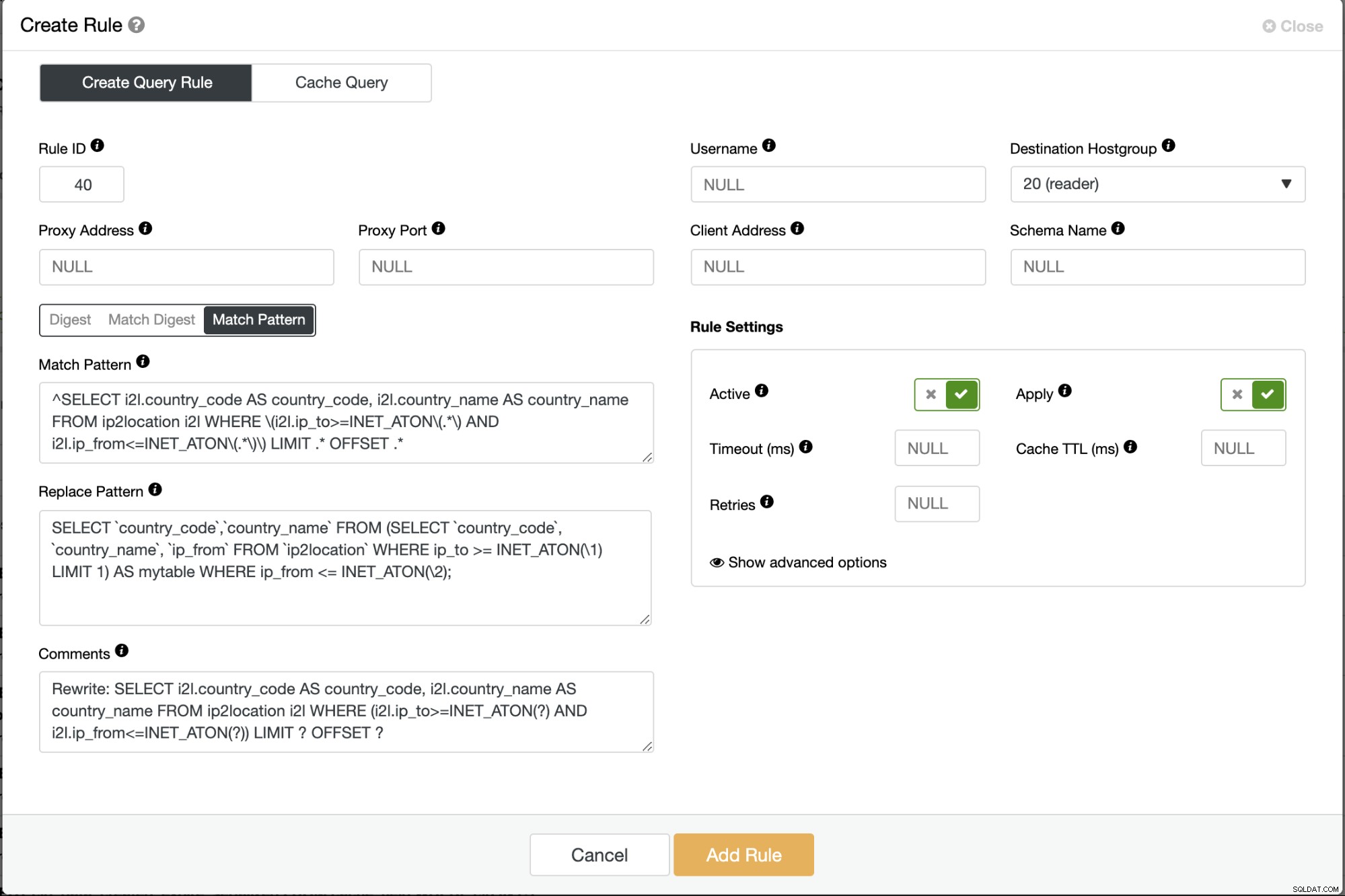
Salve a regra de consulta e monitore a página Query Outliers no ClusterControl. Essa correção obviamente removerá as consultas atípicas da lista depois que a regra de consulta for ativada.
Conclusão
Consultas atípicas é uma ferramenta proativa de monitoramento de consultas que pode nos ajudar a entender e corrigir o problema de desempenho antes que ele fique fora de controle. À medida que seu aplicativo cresce e se torna mais exigente, essa ferramenta pode ajudá-lo a manter um desempenho decente do banco de dados ao longo do caminho.