Na parte anterior, testamos o tempo de backup e a eficácia da compactação para diferentes níveis e métodos de compactação de backup. Neste blog, continuaremos nossos esforços e falaremos sobre mais configurações que, provavelmente, a maioria dos usuários realmente não altera, mas pode ter um efeito visível no processo de backup.
A configuração é a mesma da parte anterior:usaremos o cluster de replicação mestre-escravo MariaDB com ProxySQL e Keepalived.
Geramos 7,6 GB de dados usando o sysbench:
sysbench /root/sysbench/src/lua/oltp_read_write.lua --threads=4 --mysql-host=10.0.0.111 --mysql-user=sbtest --mysql-password=sbtest --mysql-port=6033 --tables=32 --table-size=1000000 prepareUsando PIGZ
Desta vez vamos habilitar Usar PIGZ para gzip paralelo para nossos backups. Como antes, testaremos cada nível de compactação para ver como ele funciona.
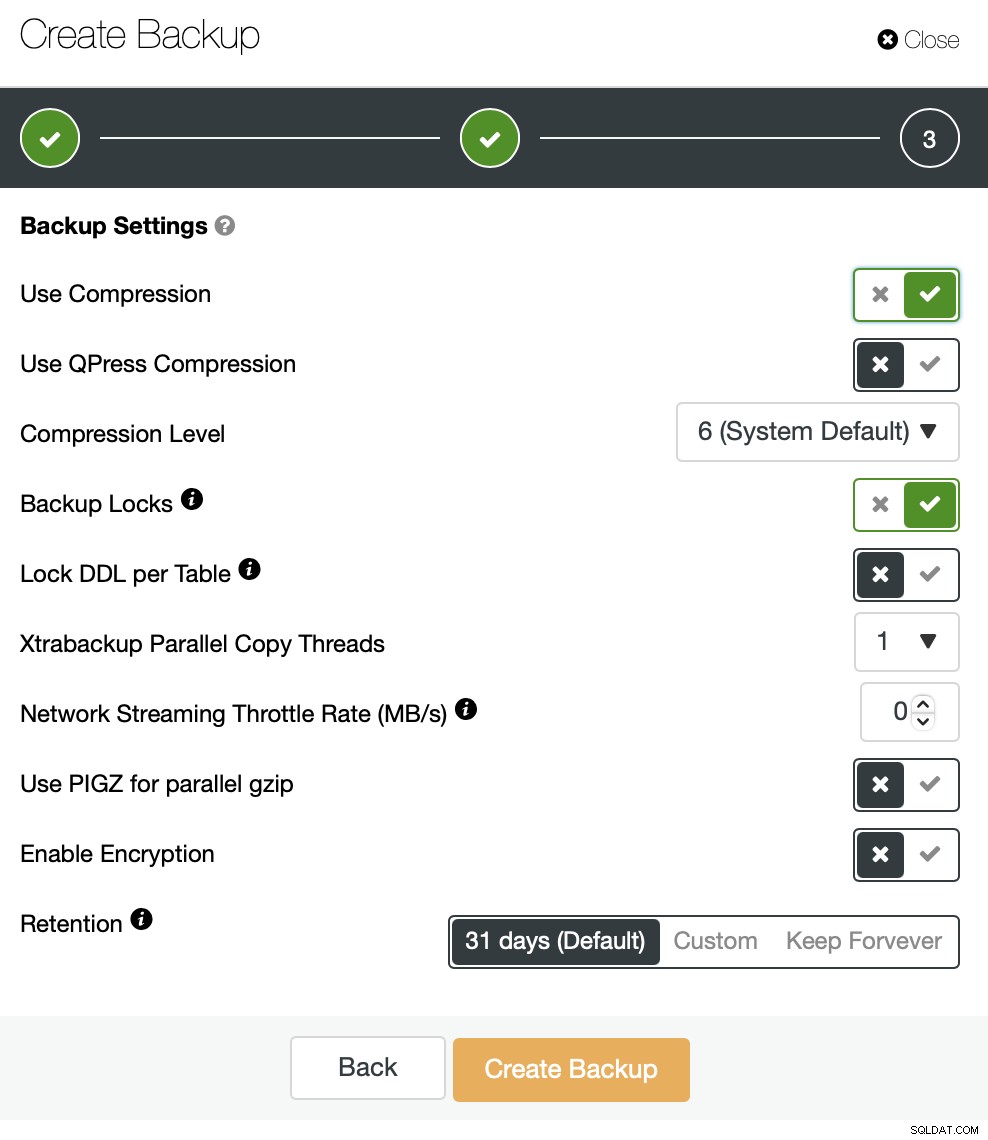
Estamos armazenando o backup localmente na instância, a instância está configurada com 4 vCPUs.
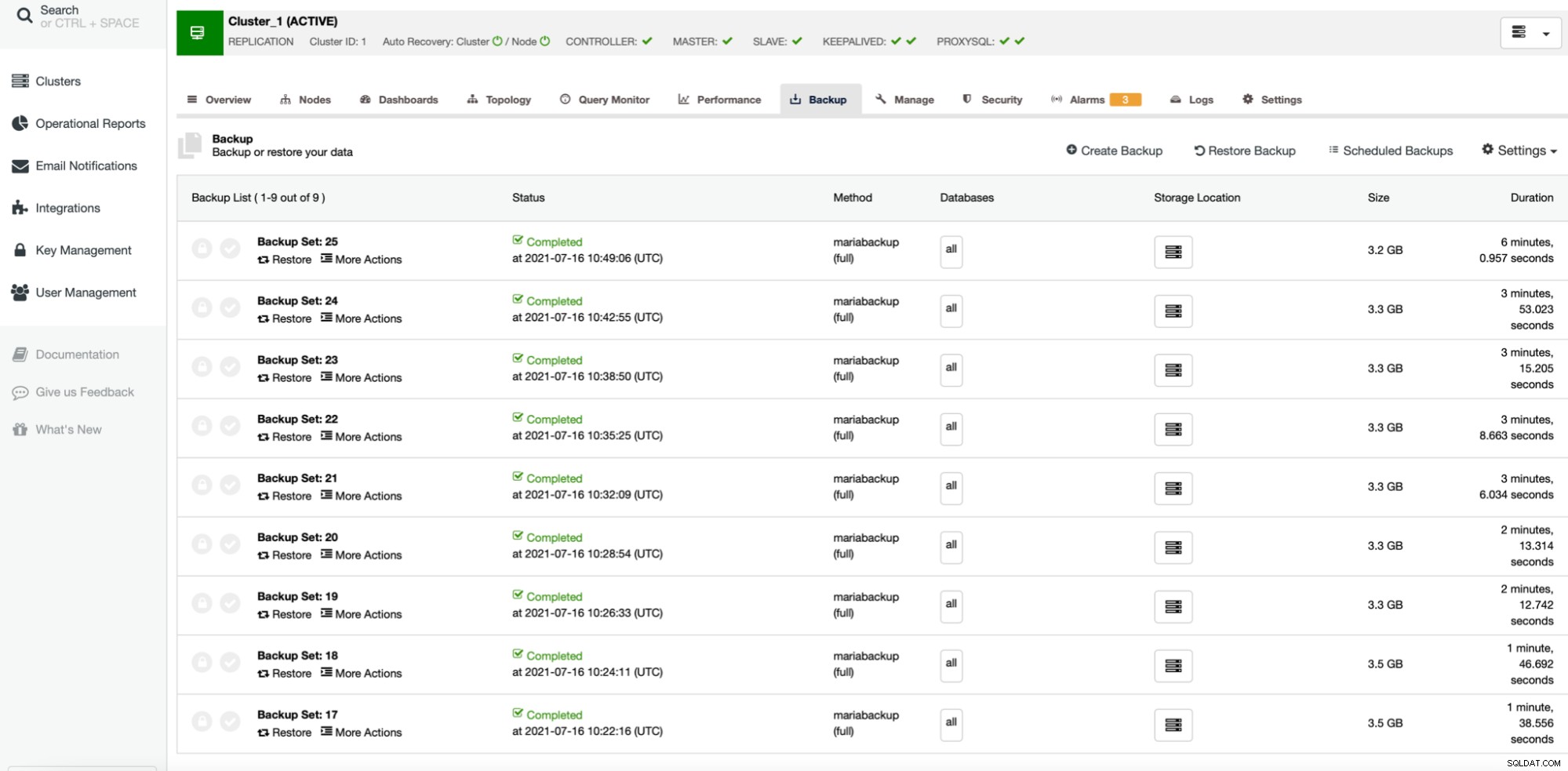
O resultado é meio que esperado. O processo de backup foi significativamente mais rápido do que quando usamos apenas um único núcleo de CPU. O tamanho do backup permanece praticamente o mesmo, não há motivo real para que ele mude significativamente. É claro que o uso do pigz melhora o tempo de backup. No entanto, há um lado sombrio do uso do gzip paralelo, e é a utilização da CPU:
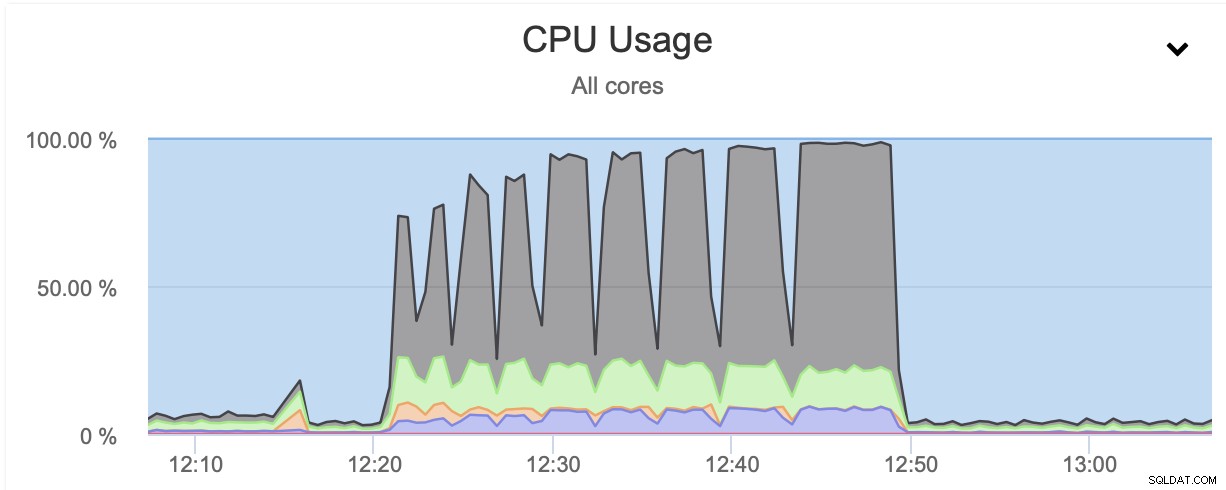
Como você pode ver, a utilização da CPU dispara e chega a quase 100% para níveis de compressão mais altos. Aumentar a utilização da CPU no servidor de banco de dados não é necessariamente a melhor ideia, pois normalmente queremos que a CPU esteja disponível para o banco de dados. Por outro lado, se tivermos uma réplica dedicada a fazer backups e, digamos, consultas mais pesadas - um nó que não é usado para servir um tipo de tráfego OLTP, podemos habilitar o gzip paralelo para reduzir bastante o backup Tempo. Como pode ser visto claramente, não é uma opção para todos, mas definitivamente é algo que você pode achar útil em alguns cenários específicos. Basta ter em mente que a utilização da CPU é algo que você precisa acompanhar, pois afetará a latência das consultas e, por meio dela, afetará a experiência do usuário - algo que sempre devemos considerar ao trabalhar com os bancos de dados.
Threads de cópia paralela do Xtrabackup
Outra configuração que queremos destacar é Xtrabackup Parallel Copy Threads. Para entender o que é, vamos falar um pouco sobre o funcionamento do Xtrabackup (ou MariaBackup). Em suma, essas ferramentas realizam duas ações ao mesmo tempo. Eles copiam os dados, arquivos físicos, do servidor de banco de dados para o local de backup enquanto monitoram os logs de redo do InnoDB para quaisquer atualizações. O backup consiste nos arquivos e no registro de todas as alterações no InnoDB que ocorreram durante o processo de backup. Isso, com bloqueios de backup ou FLUSH TABLES WITH READ LOCK, permite criar um backup consistente no momento em que a transferência de dados foi concluída. Os threads de cópia paralela do Xtrabackup definem o número de threads que realizarão a transferência de dados. Se definirmos como 1, um arquivo será copiado ao mesmo tempo. Se definirmos para 8, teoricamente até 8 arquivos podem ser transferidos de uma só vez. Obviamente, deve haver armazenamento rápido o suficiente para realmente se beneficiar de tal configuração. Vamos realizar vários testes, alterando os Threads de Cópia Paralela do Xtrabackup de 1 a 2 e 4 a 8. Executaremos testes no nível de compactação 6 (padrão um) com e sem gzip paralelo habilitado.
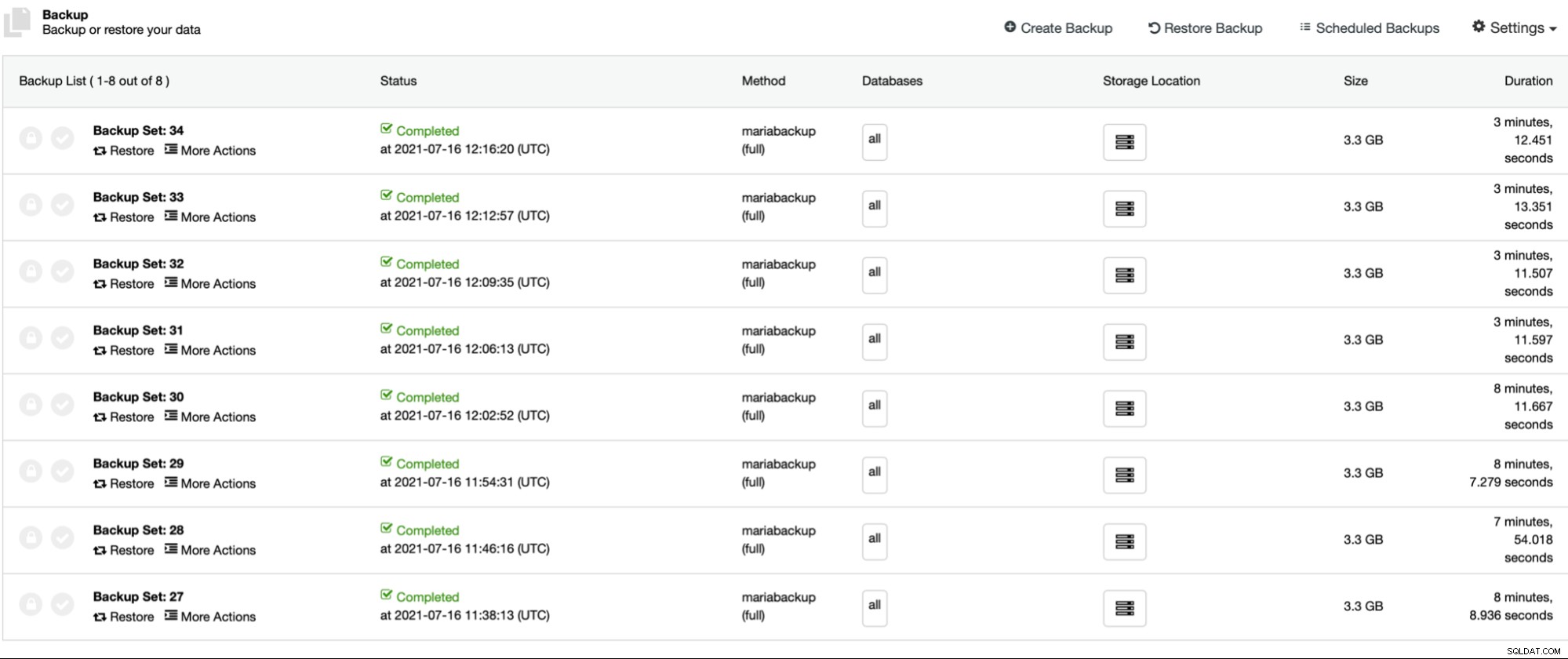
Os primeiros quatro backups (27 - 30) foram criados sem gzip paralelo, começando de 1 a 2, 4 e 8 linhas de cópia paralelas. Em seguida, repetimos o mesmo processo para os backups 31 a 34, desta vez usando gzip paralelo. Como você pode ver, no nosso caso dificilmente há diferença entre os threads de cópia paralela. Isso provavelmente será mais impactante se aumentarmos o tamanho do conjunto de dados. Também melhoraria o desempenho do backup se usássemos um armazenamento mais rápido e confiável. Como de costume, sua milhagem varia e em diferentes ambientes essa configuração pode afetar o processo de backup mais do que vemos aqui.
Limitação de rede
Finalmente, nesta parte de nossa curta série, gostaríamos de falar sobre a capacidade de limitar o uso da rede.
Como você deve ter visto, os backups podem ser armazenados localmente no nó ou ele também pode ser transmitido para o host do controlador. Isso acontece pela rede e, por padrão, será feito “o mais rápido possível”.
Em alguns casos, em que a taxa de transferência da rede é limitada (instâncias de nuvem, por exemplo), convém reduzir o uso da rede causado pelo MariaBackup definindo um limite na transferência da rede. Ao fazer isso, o ClusterControl usará a ferramenta 'pv' para limitar a largura de banda disponível para o processo.
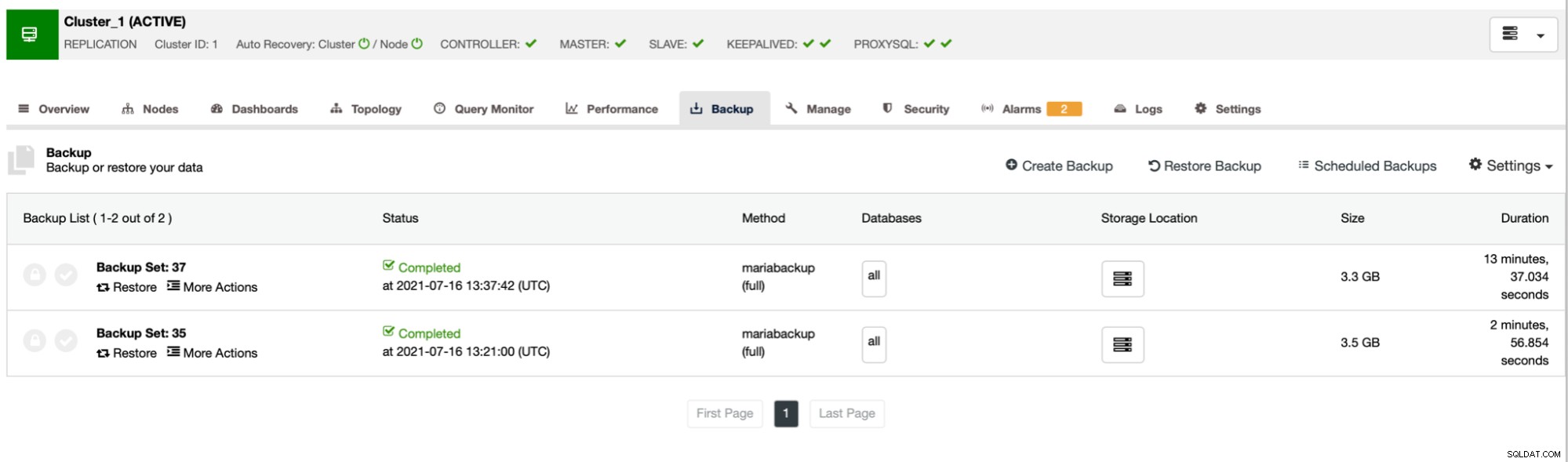
Como você pode ver, o primeiro backup levou cerca de 3 minutos, mas quando estrangulou a taxa de transferência da rede, o backup levou 13 minutos e 37 segundos.
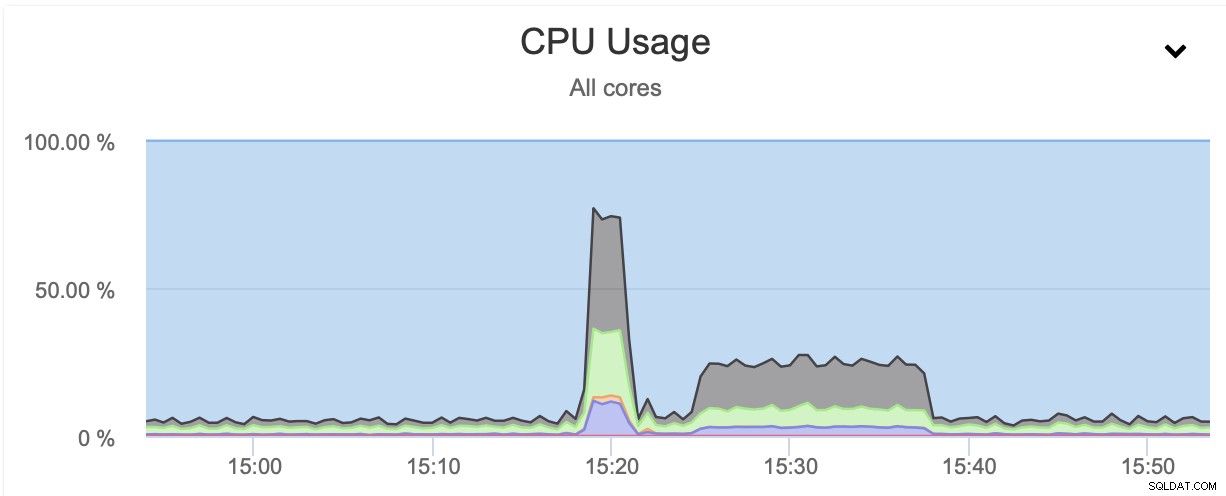
Em ambos os casos usamos pigz e o nível de compressão 1. O gráfico acima mostra que a limitação da rede também reduziu a utilização da CPU. Faz sentido, se o pigz tiver que esperar que a rede transfira os dados, ele não precisará pressionar muito a CPU, pois ficará inativo a maior parte do tempo.
Esperamos que você tenha achado este pequeno blog interessante e talvez ele o encoraje a experimentar alguns dos recursos e opções não tão comumente usados do MariaBackup. Se você gostaria de compartilhar um pouco de sua experiência, gostaríamos de ouvi-lo nos comentários abaixo.