Um balanceador de carga de banco de dados, ou proxy reverso de banco de dados, distribui a carga de trabalho do banco de dados de entrada em vários servidores de banco de dados executados por trás dele. Os objetivos de ter balanceadores de carga de banco de dados são fornecer um único endpoint de banco de dados para os aplicativos se conectarem, aumentar o rendimento das consultas, minimizar a latência e maximizar a utilização de recursos dos servidores de banco de dados.
Pode haver duas formas de topologia do balanceador de carga de banco de dados:
- Topologia centralizada
- Topologia distribuída
Nesta postagem do blog, abordaremos as duas topologias e entenderemos alguns prós e contras de cada configuração. Além disso, seria possível misturar as duas topologias?
Topologia Centralizada
Em uma configuração centralizada, um proxy reverso está localizado entre os dados e a camada de apresentação, conforme representado pelo diagrama a seguir:
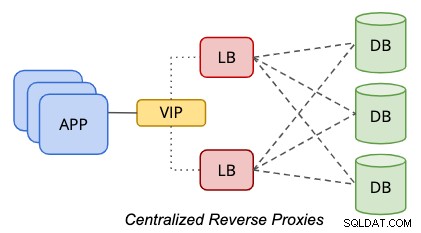
Para eliminar um ponto único de falha, é preciso definir até dois ou mais nós do balanceador de carga para fins de redundância. Se seu aplicativo puder lidar com vários pontos de extremidade de banco de dados, por exemplo, o aplicativo ou driver de banco de dados for capaz de realizar verificações de integridade se o balanceador de carga estiver íntegro para processamento de consulta, você provavelmente poderá ignorar a parte do endereço IP virtual. Caso contrário, ambos os nós do balanceador de carga devem ser vinculados a um nome de host comum ou endereço IP virtual, para fornecer transparência aos clientes de banco de dados onde ele só precisa usar um único ponto de extremidade de banco de dados para acessar a camada de dados. O uso de DNS ou mapeamento de host também é possível se você quiser pular o uso de endereços IP virtuais.
Essa abordagem baseada em camadas é muito mais simples de gerenciar devido ao posicionamento independente do host estático. É muito improvável que a camada do balanceador de carga seja dimensionada (adicionando mais nós) devido à sua base sólida em resiliência, redundância e transparência para a camada de aplicativo. Você provavelmente precisará escalar o host (adicionando mais recursos ao host), o que geralmente acontecerá muito no futuro, depois que as cargas de trabalho do balanceador de carga se tornarem mais exigentes à medida que sua empresa crescer.
Essa topologia requer uma camada e hosts adicionais, o que pode ser caro em uma infraestrutura bare-metal com servidores físicos. Essa configuração é mais fácil de gerenciar em um ambiente virtual ou em nuvem, onde você tem a flexibilidade de adicionar uma camada adicional entre a camada de aplicativo e a camada de banco de dados, sem custar muito em custos de infraestrutura física, como eletricidade, espaço em rack e custos de rede.
Topologia distribuída
Em uma configuração de topologia distribuída, os balanceadores de carga são colocados dentro da camada de apresentação (aplicativo ou servidores Web), conforme simplificado pelo diagrama a seguir:
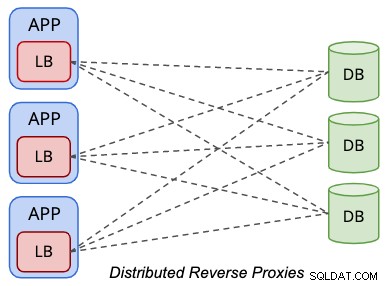
Aplicativos tratam o balanceador de carga de banco de dados de forma semelhante a um servidor de banco de dados local, onde o load balancer torna-se a representação dos bancos de dados remotos da perspectiva do aplicativo. Normalmente, o balanceador de carga estará escutando a interface de rede local como 127.0.0.1 ou "localhost", que simplificará o host de banco de dados do endpoint do banco de dados para os aplicativos.
Uma das vantagens de executar nessa topologia é que você não precisa de hosts extras para fins de balanceamento de carga. Ao combinar a camada do balanceador de carga na camada de apresentação, poderíamos salvar pelo menos dois hosts. Em um ambiente bare-metal, essa topologia poderia economizar muito dinheiro ao longo dos anos. Geralmente, a carga de trabalho do balanceador de carga é muito menos exigente se comparada às cargas de trabalho do banco de dados ou do aplicativo, o que torna justificável compartilhar os mesmos recursos de hardware com os aplicativos.
Quando co-localizado com o servidor de aplicativos, você aproxima o proxy reverso do aplicativo e elimina o ponto único de falha. Isso pode melhorar significativamente o desempenho do aplicativo quando você tem uma separação geográfica entre o aplicativo e a camada de dados, especialmente para balanceadores de carga de banco de dados que dão suporte ao cache de conjunto de resultados, como ProxySQL e MaxScale. Por outro lado, o número de balanceadores de carga de banco de dados geralmente é igual ao número de nós de aplicativo, o que significa que, se a camada do aplicativo for ampliada, o número de balanceadores de carga de banco de dados aumentará, o que pode potencialmente degradar o desempenho da integridade do banco de dados verifique o serviço. Observe que as verificações de integridade do balanceador de carga são um pouco mais chatas devido à sua responsabilidade de acompanhar o estado correto dos nós do banco de dados.
Com a ajuda de ferramentas de automação de infraestrutura de TI, como Chef, Puppet e Ansible, juntamente com as ferramentas de orquestração de contêineres, não é mais uma tarefa impossível automatizar a implantação e o gerenciamento de várias instâncias do balanceador de carga para essa topologia. No entanto, haverá outra curva de aprendizado para a equipe de operação criar políticas de implantação e gerenciamento de nível de produção testadas em batalha para reduzir o trabalho excessivo ao lidar com muitos nós do balanceador de carga. Não perca todos os aspectos importantes de gerenciamento do balanceador de carga de banco de dados, como backup/restauração, upgrade/downgrade, gerenciamento de configuração, controle de serviço, gerenciamento de falhas e assim por diante.
A topologia distribuída pode ser combinada com a topologia centralizada para alguns balanceadores de carga de banco de dados compatíveis, como ProxySQL, conforme ilustrado no diagrama a seguir:
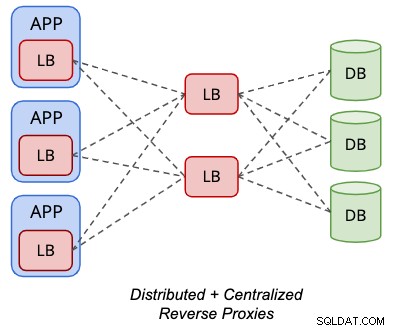
Os "servidores" de back-end de uma instância ProxySQL podem ser outro conjunto de ProxySQL nós em vez disso. Com essa configuração, um endereço IP virtual não é necessário para acesso de endpoint único aos nós do banco de dados, pois a instância local do ProxySQL hospedada localmente no servidor de aplicativos será o acesso de endpoint único do ponto de vista do aplicativo.
No entanto, isso requer duas versões de configurações do balanceador de carga - uma que reside na camada do aplicativo e outra reside nas camadas do balanceador de carga. Também requer mais hosts, excluindo a necessidade de aprender sobre tecnologia de endereço IP virtual, failover de IP e assim por diante. As vantagens e desvantagens das configurações distribuídas e centralizadas são a fusão nesta topologia.
Conclusão
Cada topologia tem suas próprias vantagens e desvantagens e deve ser bem planejada desde o início. Essa decisão antecipada é crítica e pode influenciar enormemente o desempenho, a escalabilidade, a confiabilidade e a disponibilidade do seu aplicativo a longo prazo.



