Uma configuração de cluster de replicação mestre/escravo é um caso de uso comum na maioria das organizações. O uso do MySQL Replication permite que seus dados sejam replicados em diferentes ambientes e garante que as informações sejam copiadas. É assíncrono e single-thread (por padrão), mas a replicação também permite que você o configure para ser síncrono (ou realmente “semi-síncrono”) e pode executar o thread escravo para vários threads ou em paralelo.
Essa ideia é muito comum e geralmente chega com uma configuração simples, fazendo com que seu escravo sirva como sua recuperação ou para soluções de backup. No entanto, isso sempre tem um preço, especialmente quando consultas ruins (como falta de chaves primárias ou exclusivas) são replicadas ou algum problema com o hardware (como problemas de rede ou IO de disco). Quando esses problemas ocorrem, o problema mais comum é o atraso de replicação.
Um atraso de replicação é o custo do atraso para transação(ões) ou operação(ões) calculado pela diferença de tempo de execução entre o nó principal/mestre em relação ao nó de espera/escravo. A maioria dos casos no MySQL depende da replicação de consultas incorretas, como falta de chaves primárias ou índices incorretos, hardware de rede ruim ou placa de rede com defeito, localização distante entre regiões ou zonas diferentes ou alguns processos, como backups físicos em execução, podem causar seu banco de dados MySQL para atrasar a aplicação da transação replicada atual. Este é um caso muito comum ao diagnosticar esses problemas. Neste blog, veremos como lidar com esses casos e o que observar se você estiver enfrentando um atraso na replicação do MySQL.
O "SHOW SLAVE STATUS":O mantra do MySQL DBA
Em alguns casos, esta é a bala de prata ao lidar com o atraso de replicação e revela principalmente tudo a causa de um problema em seu banco de dados MySQL. Basta executar esta instrução SQL em seu nó escravo que está com suspeita de atraso de replicação.
Os campos iniciais que são comuns para rastrear problemas são,
- Slave_IO_State - Diz-lhe o que o segmento está fazendo. Este campo fornecerá boas informações se a integridade da replicação estiver funcionando normalmente, enfrentando problemas de rede, como reconectar a um mestre ou demorar muito para confirmar dados, o que pode indicar problemas de disco ao sincronizar dados com o disco. Você também pode determinar esse valor de estado ao executar SHOW PROCESSLIST.
- Master_Log_File - Nome do arquivo de log binário do mestre em que o encadeamento de E/S está sendo buscado no momento.
- Read_Master_Log_Pos - posição do arquivo binlog do mestre onde o thread de E/S de replicação já foi lido.
- Relay_Log_File - o nome do arquivo de log de retransmissão para o qual o thread SQL está executando os eventos no momento
- Relay_Log_Pos - posição binlog do arquivo especificado em Relay_Log_File para o qual o thread SQL já foi executado.
- Relay_Master_Log_File - O arquivo de log binário do mestre que o thread SQL já executou e é congruente com o valor Read_Master_Log_Pos.
- Seconds_Behind_Master - este campo mostra uma aproximação da diferença entre o carimbo de data/hora atual no escravo em relação ao carimbo de data/hora no mestre para o evento que está sendo processado no escravo. No entanto, este campo pode não ser capaz de informar o atraso exato se a rede estiver lenta porque a diferença em segundos é tomada entre o thread SQL escravo e o thread de E/S escravo. Portanto, pode haver casos em que ele pode ser alcançado com o encadeamento de E/S escravo de leitura lenta, mas eu o domino já é diferente.
- Slave_SQL_Running_State - estado do thread SQL e o valor é idêntico ao valor do estado exibido em SHOW PROCESSLIST.
- Retrieved_Gtid_Set - Disponível ao usar a replicação GTID. Este é o conjunto de GTID's correspondentes a todas as transações recebidas por este escravo.
- Executed_Gtid_Set - Disponível ao usar a replicação GTID. É o conjunto de GTIDs escritos no log binário.
Por exemplo, vamos pegar o exemplo abaixo que usa uma replicação GTID e está enfrentando um atraso de replicação:
mysql> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.10.70
Master_User: cmon_replication
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: binlog.000038
Read_Master_Log_Pos: 826608419
Relay_Log_File: relay-bin.000004
Relay_Log_Pos: 468413927
Relay_Master_Log_File: binlog.000038
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 826608206
Relay_Log_Space: 826607743
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 251
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 45003
Master_UUID: 36272880-a7b0-11e9-9ca6-525400cae48b
Master_Info_File: mysql.slave_master_info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: copy to tmp table
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp:
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set: 36272880-a7b0-11e9-9ca6-525400cae48b:7631-9192
Executed_Gtid_Set: 36272880-a7b0-11e9-9ca6-525400cae48b:1-9191,
864dd532-a7af-11e9-85f2-525400cae48b:1-173,
df68c807-a7af-11e9-9b56-525400cae48b:1-4
Auto_Position: 1
Replicate_Rewrite_DB:
Channel_Name:
Master_TLS_Version:
1 row in set (0.00 sec)Diagnosticando problemas como este, mysqlbinlog também pode ser sua ferramenta para identificar qual consulta está sendo executada em uma posição x &y do log binário específico. Para determinar isso, vamos pegar o Retrieved_Gtid_Set, Relay_Log_Pos e o Relay_Log_File. Veja o comando abaixo:
[example@sqldat.com mysql]# mysqlbinlog --base64-output=DECODE-ROWS --include-gtids="36272880-a7b0-11e9-9ca6-525400cae48b:9192" --start-position=468413927 -vvv relay-bin.000004
/*!50530 SET @@SESSION.PSEUDO_SLAVE_MODE=1*/;
/*!50003 SET @example@sqldat.com@COMPLETION_TYPE,COMPLETION_TYPE=0*/;
DELIMITER /*!*/;
# at 468413927
#200206 4:36:14 server id 45003 end_log_pos 826608271 CRC32 0xc702eb4c GTID last_committed=1562 sequence_number=1563 rbr_only=no
SET @@SESSION.GTID_NEXT= '36272880-a7b0-11e9-9ca6-525400cae48b:9192'/*!*/;
# at 468413992
#200206 4:36:14 server id 45003 end_log_pos 826608419 CRC32 0xe041ec2c Query thread_id=24 exec_time=31 error_code=0
use `jbmrcd_date`/*!*/;
SET TIMESTAMP=1580963774/*!*/;
SET @@session.pseudo_thread_id=24/*!*/;
SET @@session.foreign_key_checks=1, @@session.sql_auto_is_null=0, @@session.unique_checks=1, @@session.autocommit=1/*!*/;
SET @@session.sql_mode=1436549152/*!*/;
SET @@session.auto_increment_increment=1, @@session.auto_increment_offset=1/*!*/;
/*!\C utf8 *//*!*/;
SET @@session.character_set_client=33,@@session.collation_connection=33,@@session.collation_server=8/*!*/;
SET @@session.lc_time_names=0/*!*/;
SET @@session.collation_database=DEFAULT/*!*/;
ALTER TABLE NewAddressCode ADD INDEX PostalCode(PostalCode)
/*!*/;
SET @@SESSION.GTID_NEXT= 'AUTOMATIC' /* added by mysqlbinlog */ /*!*/;
DELIMITER ;
# End of log file
/*!50003 SET example@sqldat.com_COMPLETION_TYPE*/;
/*!50530 SET @@SESSION.PSEUDO_SLAVE_MODE=0*/;Ele nos diz que estava tentando replicar e executar uma instrução DML que tenta ser a fonte do atraso. Esta tabela é uma tabela enorme contendo 13 milhões de linhas.
Verifique SHOW PROCESSLIST, SHOW ENGINE INNODB STATUS, com a combinação de comandos ps, top, iostat
Em alguns casos, SHOW SLAVE STATUS não é suficiente para nos dizer o culpado. É possível que as instruções replicadas sejam afetadas por processos internos executados no banco de dados MySQL slave. A execução das instruções SHOW [FULL] PROCESSLIST e SHOW ENGINE INNODB STATUS também fornece dados informativos que fornecem informações sobre a origem do problema.
Por exemplo, digamos que uma ferramenta de benchmarking esteja sendo executada, causando a saturação da E/S do disco e da CPU. Você pode verificar executando ambas as instruções SQL. Combine-o com os comandos ps e top.
Você também pode determinar gargalos com seu armazenamento em disco executando iostat que fornece estatísticas do volume atual que você está tentando diagnosticar. A execução do iostat pode mostrar o quão ocupado ou carregado está o seu servidor. Por exemplo, tomado por um escravo que está atrasado, mas também experimentando alta utilização de E/S ao mesmo tempo,
[example@sqldat.com ~]# iostat -d -x 10 10
Linux 3.10.0-693.5.2.el7.x86_64 (testnode5) 02/06/2020 _x86_64_ (2 CPU)
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 0.42 3.71 60.65 218.92 568.39 24.47 0.15 2.31 13.79 1.61 0.12 0.76
dm-0 0.00 0.00 3.70 60.48 218.73 568.33 24.53 0.15 2.36 13.85 1.66 0.12 0.76
dm-1 0.00 0.00 0.00 0.00 0.04 0.01 21.92 0.00 63.29 2.37 96.59 22.64 0.01
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 0.20 392.30 7983.60 2135.60 49801.55 12.40 36.70 3.84 13.01 3.39 0.08 69.02
dm-0 0.00 0.00 392.30 7950.20 2135.60 50655.15 12.66 36.93 3.87 13.05 3.42 0.08 69.34
dm-1 0.00 0.00 0.00 0.30 0.00 1.20 8.00 0.06 183.67 0.00 183.67 61.67 1.85
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 1.40 370.93 6775.42 2557.04 46184.22 13.64 43.43 6.12 11.60 5.82 0.10 73.25
dm-0 0.00 0.00 370.93 6738.76 2557.04 47029.62 13.95 43.77 6.20 11.64 5.90 0.10 73.41
dm-1 0.00 0.00 0.00 0.30 0.00 1.20 8.00 0.03 107.00 0.00 107.00 35.67 1.07
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 0.00 299.80 7253.35 1916.88 52766.38 14.48 30.44 4.59 15.62 4.14 0.10 72.09
dm-0 0.00 0.00 299.80 7198.60 1916.88 51064.24 14.13 30.68 4.66 15.70 4.20 0.10 72.57
dm-1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 0.10 215.50 8939.60 1027.60 67497.10 14.97 59.65 6.52 27.98 6.00 0.08 72.50
dm-0 0.00 0.00 215.50 8889.20 1027.60 67495.90 15.05 60.07 6.60 28.09 6.08 0.08 72.75
dm-1 0.00 0.00 0.00 0.30 0.00 1.20 8.00 0.01 32.33 0.00 32.33 30.33 0.91
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 0.90 140.40 8922.10 625.20 54709.80 12.21 11.29 1.25 9.88 1.11 0.08 68.60
dm-0 0.00 0.00 140.40 8871.50 625.20 54708.60 12.28 11.39 1.26 9.92 1.13 0.08 68.83
dm-1 0.00 0.00 0.00 0.30 0.00 1.20 8.00 0.01 27.33 0.00 27.33 9.33 0.28
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 1.70 284.50 8621.30 24228.40 51535.75 17.01 34.14 3.27 8.19 3.11 0.08 72.78
dm-0 0.00 0.00 290.90 8587.10 25047.60 53434.95 17.68 34.28 3.29 8.02 3.13 0.08 73.47
dm-1 0.00 0.00 0.00 2.00 0.00 8.00 8.00 0.83 416.45 0.00 416.45 63.60 12.72
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 0.30 851.60 11018.80 17723.60 85165.90 17.34 142.59 12.44 7.61 12.81 0.08 99.75
dm-0 0.00 0.00 845.20 10938.90 16904.40 83258.70 17.00 143.44 12.61 7.67 12.99 0.08 99.75
dm-1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 1.10 24.60 12965.40 420.80 51114.45 7.93 39.44 3.04 0.33 3.04 0.07 93.39
dm-0 0.00 0.00 24.60 12890.20 420.80 51114.45 7.98 40.23 3.12 0.33 3.12 0.07 93.35
dm-1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 0.00 3.60 13420.70 57.60 51942.00 7.75 0.95 0.07 0.33 0.07 0.07 92.11
dm-0 0.00 0.00 3.60 13341.10 57.60 51942.00 7.79 0.95 0.07 0.33 0.07 0.07 92.08
dm-1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00O resultado acima exibe a alta utilização de E/S e gravações altas. Ele também revela que o tamanho médio da fila e o tamanho médio da solicitação estão se movendo, o que significa que é uma indicação de uma alta carga de trabalho. Nesses casos, você precisa determinar se existem processos externos que fazem com que o MySQL sufoque os threads de replicação.
Como o ClusterControl pode ajudar?
Com o ClusterControl, lidar com o atraso do escravo e determinar o culpado é muito fácil e eficiente. Ele informa diretamente na interface do usuário da web, veja abaixo:
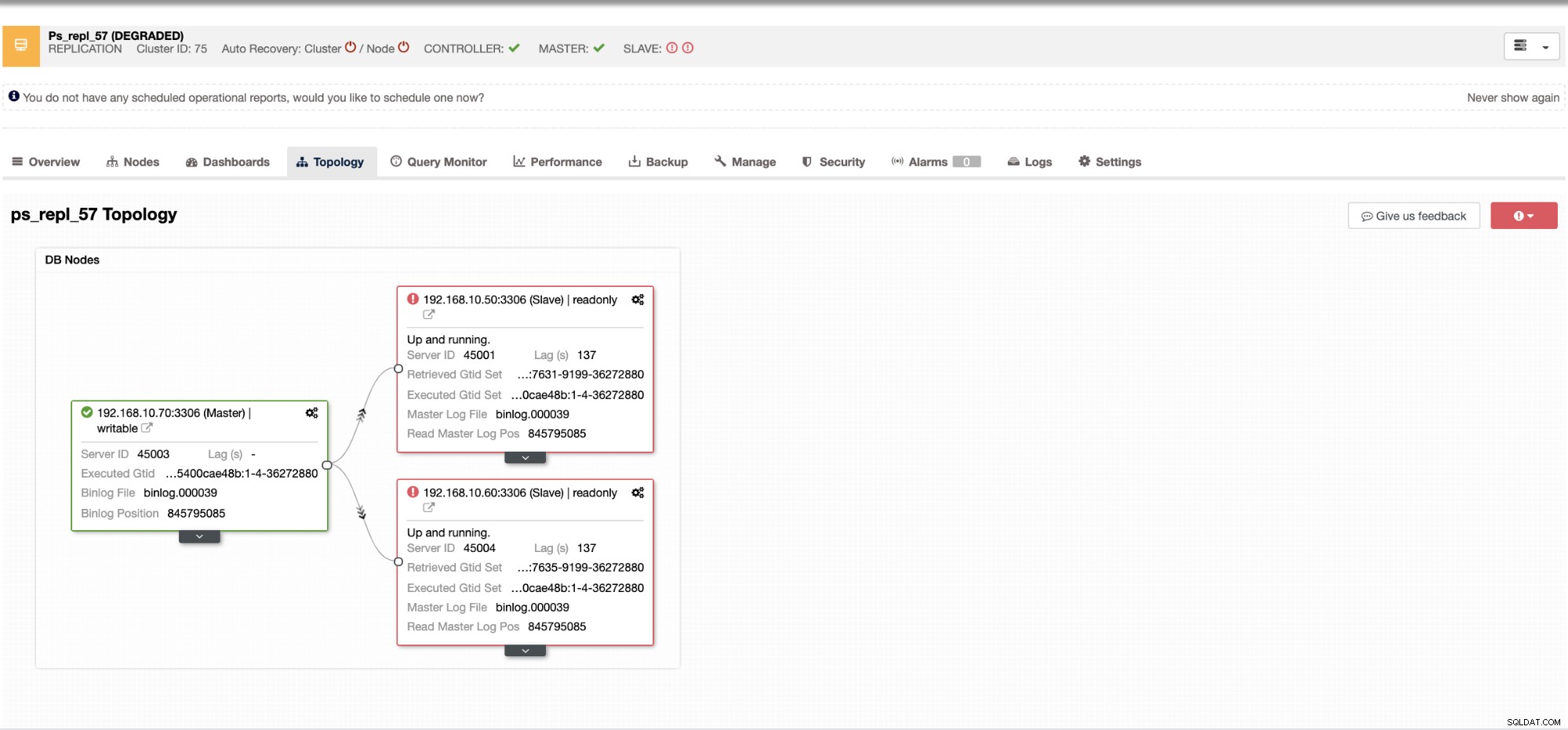
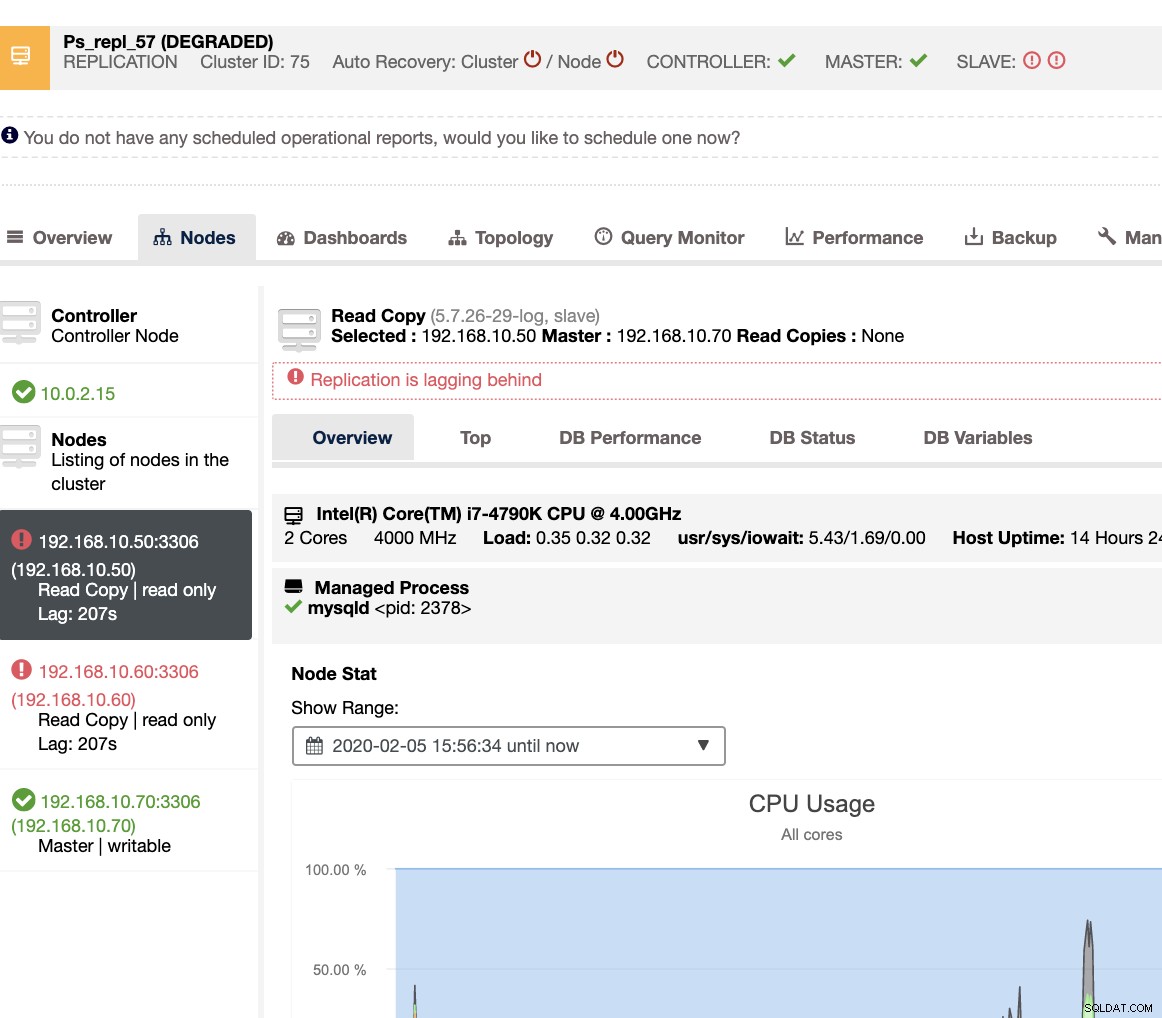
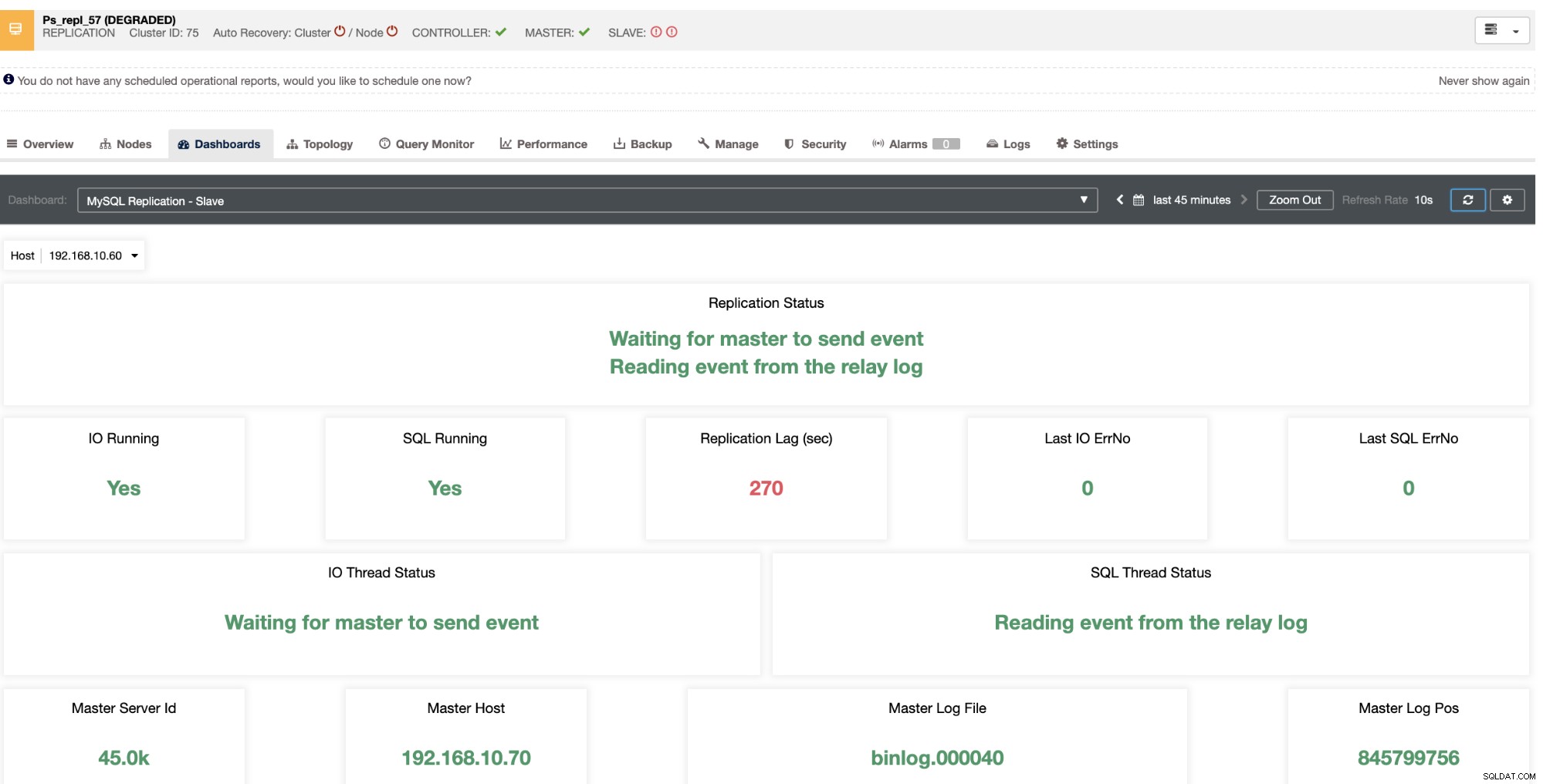
Ele revela a você o atraso atual do escravo que seus nós escravos estão experimentando. Não só isso, com os painéis SCUMM, se ativados, fornecem mais informações sobre o que a saúde do seu nó escravo ou até mesmo todo o cluster está fazendo:


Não apenas essas coisas estão disponíveis no ClusterControl, mas também fornece a capacidade de evitar que consultas incorretas ocorram com esses recursos, como visto abaixo,
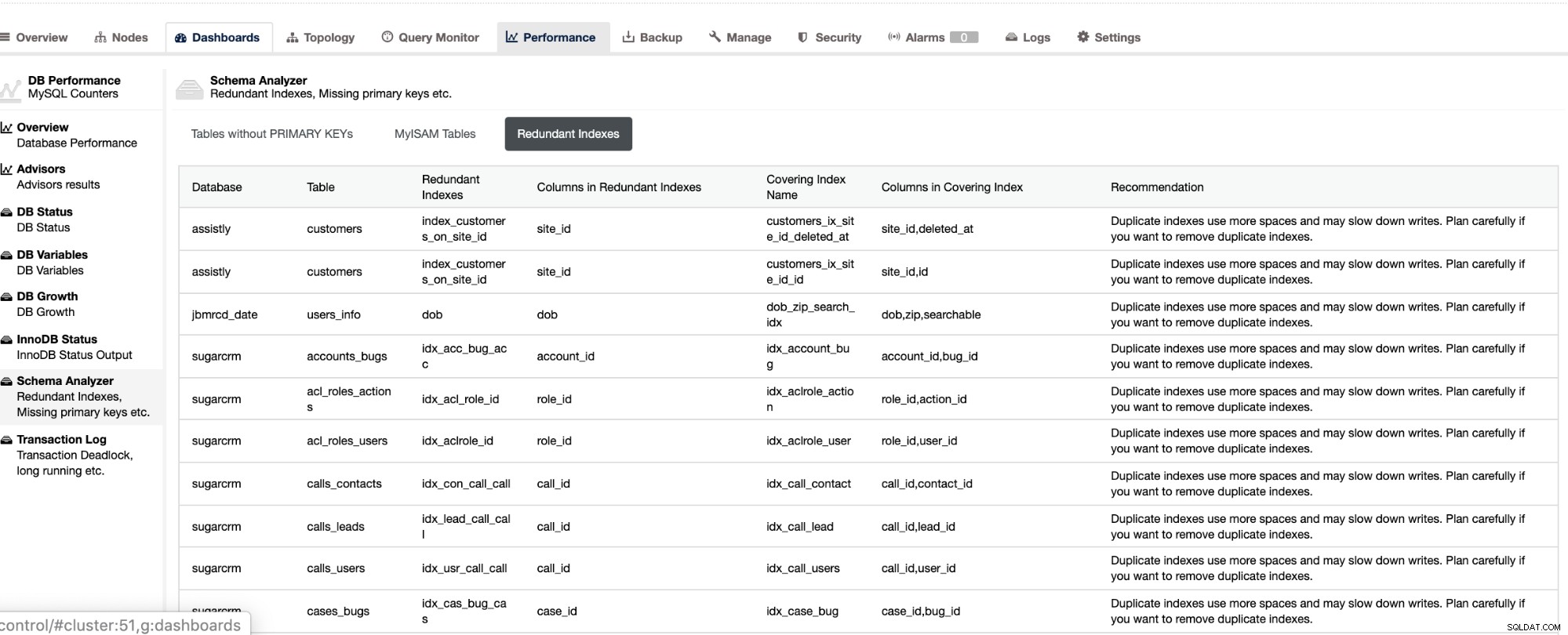
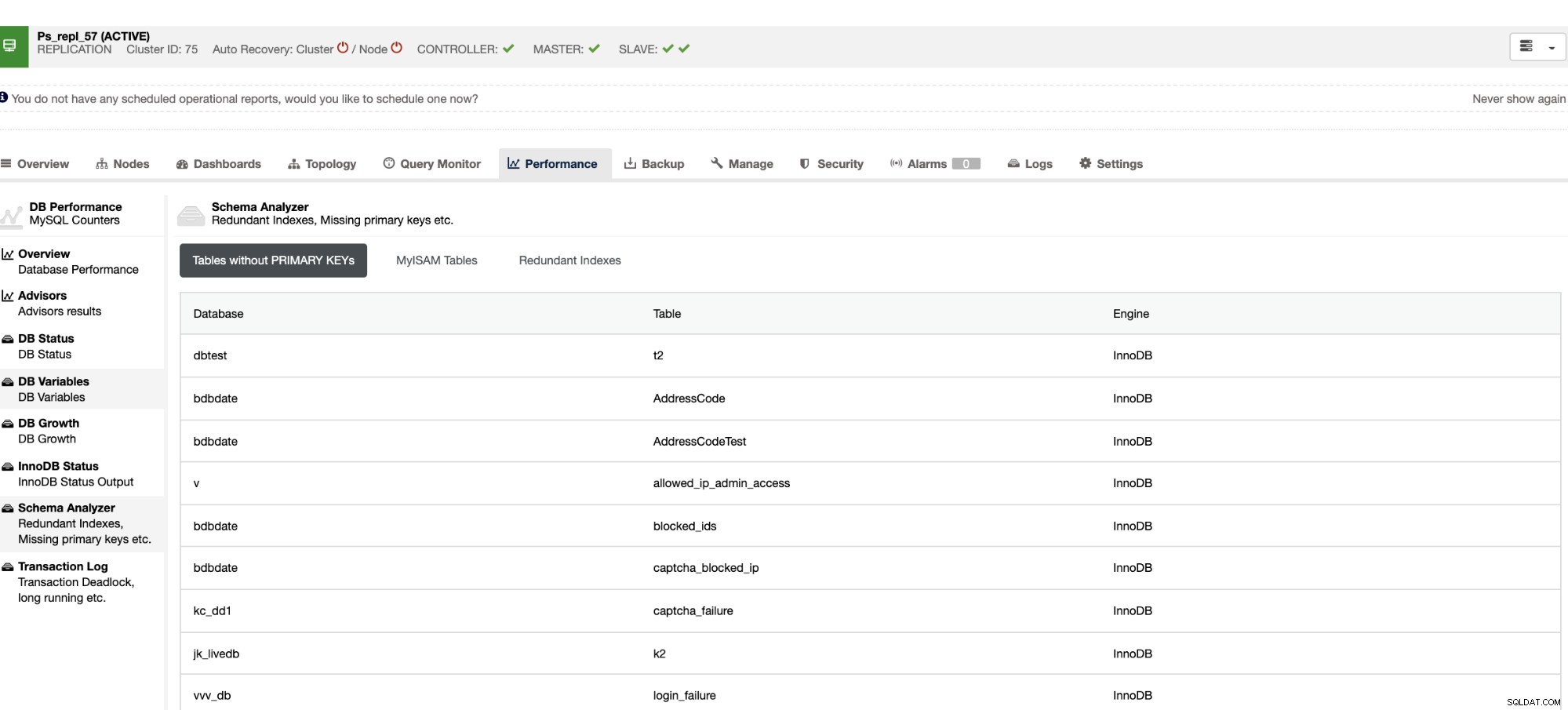
Os índices redundantes permitem determinar que esses índices podem causar problemas de desempenho para consultas de entrada que referenciam os índices duplicados. Ele também informa tabelas que não possuem chaves primárias, que geralmente são um problema comum de atraso de escravos quando uma determinada consulta SQL ou transações que fazem referência a tabelas grandes sem chaves primárias ou exclusivas quando são replicadas para os escravos.
Conclusão
Lidar com o atraso da replicação do MySQL é um problema frequente em uma configuração de replicação mestre-escravo. Pode ser fácil de diagnosticar, mas difícil de resolver. Certifique-se de ter suas tabelas com chave primária ou chave exclusiva existentes e determine as etapas e ferramentas sobre como solucionar problemas e diagnosticar a causa do atraso do escravo. A eficiência é sempre a chave na resolução de problemas.